Arize AI alternatives: Top 5 Arize competitors compared (2026)
LangWatch wins for teams shipping production LLM applications with complex AI agents. Agent simulation testing, collaboration with PM's, OpenTelemetry-native tracing make it the most complete platform for agentic AI.
 Bram P · January 30, 2026 · LLM Evals
Bram P · January 30, 2026 · LLM EvalsTL;DR: Which Arize alternative fits your needs?
LangWatch wins for teams shipping production LLM applications with complex AI agents. Agent simulation testing, collaboration with PM's, OpenTelemetry-native tracing, and collaborative evaluation workflows make it the most complete platform for agentic AI.
Runner-up alternatives:
Confident AI - Eval and observability standardization across product teams
Langfuse - Open-source flexibility, for small start-ups / dev-focussed teams
LangSmith - Great if you're locked into LangChain
Helicone - Proxy-based observability, fastest no-code setup
Choose LangWatch if agent simulation (multi-turn conversations), automated prompt optimization, and cross-functional collaboration matter. Pick others if you only need basic logging or have specific constraints (e.g., LangChain-only, simple tracing).
Why teams look for Arize AI alternatives
Arize AI started as an ML model monitoring platform focused on traditional machine learning operations. The company built features for drift detection, model performance tracking, and tabular data monitoring designed for predictive ML models from years past.
As LLM applications moved from prototypes to production, Arize expanded into generative AI through its Arize Phoenix open-source framework and later added LLM capabilities to its web application. Arize now offers LLM evaluation, prompt versioning through their Prompt Hub, and tracing for conversational applications.
However, teams building production LLM applications with AI agents encounter specific workflow gaps:
-
ML-first architecture. Arize's platform was built for traditional ML workflows. LLM evaluation, prompt management, and generative AI tracing were added later, creating a disconnected experience between classical model monitoring and agentic AI development.
-
No agent simulation testing. Arize focuses on observing what happened after the fact. Teams need to test complex multi-turn agent conversations, tool usage patterns, and edge cases before deployment through synthetic simulations.
-
Limited prompt optimization capabilities. Manual prompt engineering doesn't scale for complex agent systems. Teams need systematic, automated approaches to improve prompts and agent behavior.
-
Evaluation and tracing live in separate workflows. Dataset management exists separately from the tracing interface. Correlating evaluation results to specific production traces requires manual work.
Teams shipping LLM applications with AI agents need platforms that integrate simulation testing, automated optimization, evaluation, and observability into a single system.
Top 5 Arize alternatives (2026)
1. LangWatch: End-to-end LLM observability and agent testing platform
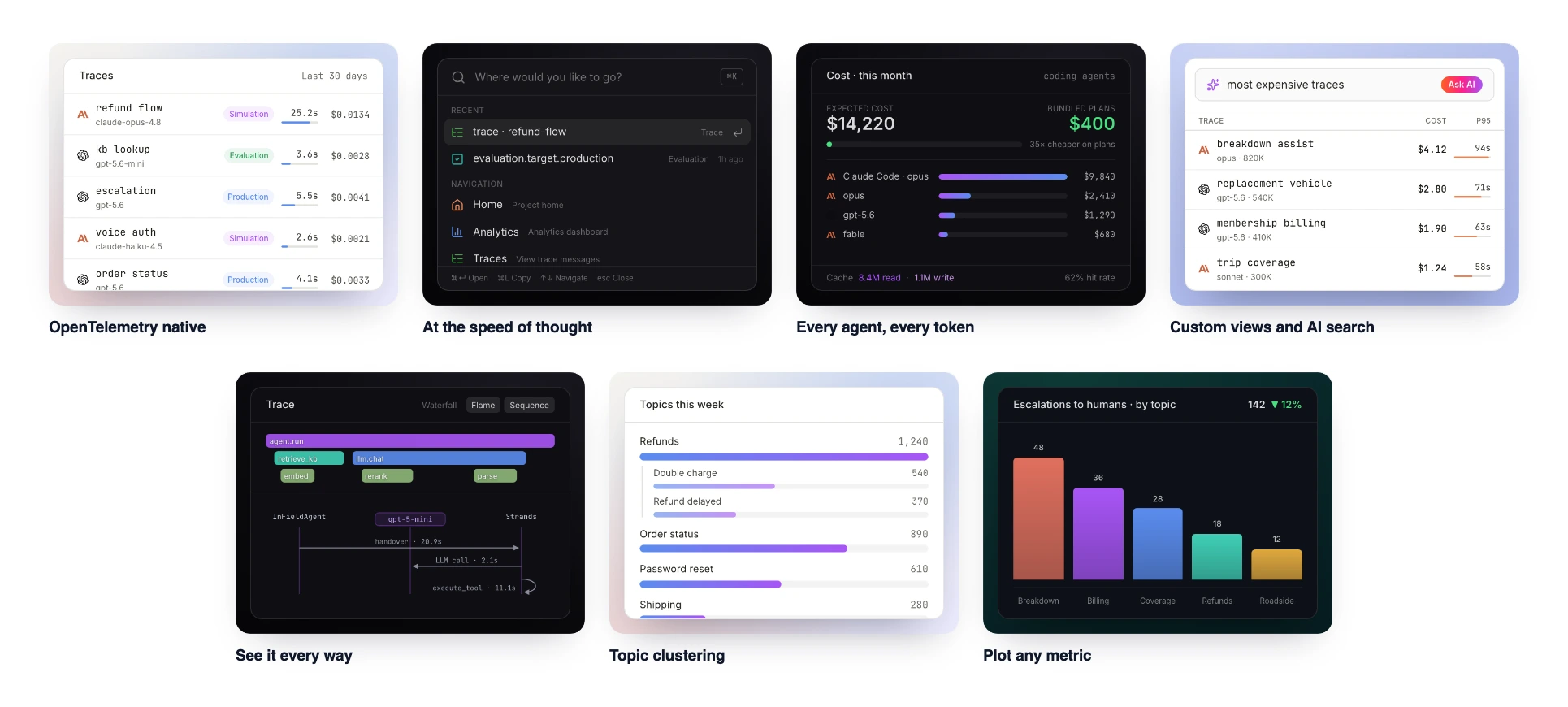
LangWatch takes an evaluation-first approach combined with unique agent simulation capabilities. Teams can test AI agents with thousands of synthetic conversations across scenarios, languages, and edge cases before production deployment, catching issues that traditional evaluation misses.
LangWatch consolidates agent testing, experimentation, evaluation, optimization, and observability into a single system. Teams use LangWatch instead of juggling multiple tools. Simulations, traces, evaluations, and optimization experiments stay in one place, with engineers, domain experts, and product managers collaborating together. Trusted in production by enterprises in banking and payments including Deloitte, Backbase, and PagBank.
Pros
Agent simulation testing
-
Simulate thousands of multi-turn conversations with AI agents testing scenarios before production
-
Test complex agentic workflows including tool usage, reasoning chains, and multi-modal interactions
-
Validate edge cases and adversarial scenarios in controlled environments
-
Framework-agnostic simulation through AgentAdapter interface supporting any agent architecture, including voice agents end to end
Systematic evaluation framework
-
Pre-built evaluators tested for accuracy including hallucination detection and safety checks
-
Auto-generated custom LLM-as-judge evaluators created by typing descriptions
-
Rigorous regression detection: Failed experiments automatically become part of the regression suite that runs in CI/CD, providing measurable metrics to teams
-
CLHF (Continuous Learning with Human Feedback) auto-tunes evaluators with few-shot examples
-
Versioned datasets: Datasets built from production logs or curated test sets track performance over time for consistent evaluation across changes
-
Run evaluations in real-time on production traces or offline on datasets
-
Collaborate on the platform or run via your CI/CD
-
Built-in guardrails add runtime PII and prompt-injection protection on production traffic
OpenTelemetry-native tracing
-
Built on OpenTelemetry standard for framework-agnostic integration
-
Automatic instrumentation for LangGraph, LangChain, Pydantic AI, and more
-
Support for 800+ models and providers including OpenAI, Anthropic, Bedrock, Gemini
-
Zero vendor lock-in with standardized tracing
-
Trace explorer renders runs as waterfalls, flame charts, topology graphs, and sequence diagrams, with AI-powered plain-language trace search
Collaborative UI & CI/CD runs
-
Dual interface: platform UI for domain experts, programmatic APIs for developers
-
Data review and labeling with collaborative annotation workflows
-
Convert production traces into reusable test cases and golden datasets
-
Custom dashboards for business stakeholders with user behavior analytics
Deployment flexibility
-
Self-hosting with unlimited features
-
Cloud-hosted option with generous free tier
-
Hybrid deployment keeping sensitive data on-premises
-
Enterprise support with air-gapped installations available
-
ISO 27001 and GDPR, with RBAC, SSO/SCIM, and audit logging, across EU, US, UK, and APAC
-
AI gateway for org-wide governance: virtual keys with budgets, routing policies, and a full audit trail
Cons
- Your team needs to be ready for setting quality standards, think about what's the goal and understand what quality looks like for your company/product.
Best for
Companies building production AI agents and complex agentic systems that need comprehensive testing, automated optimization, and cross-functional collaboration, including enterprises in regulated industries that require self-hosting, EU data residency, and audit-ready governance. Larger teams and organisations fit very well.
Pricing
Free tier (200K events/month) for developers exploring evaluation and simulation workflows. Paid from €29 per seat/month with unlimited experiments and simulations. Enterprise plans with custom deployments including hybrid and air-gapped modes.
Why teams choose LangWatch over Arize
| Feature | LangWatch | Arize | Winner |
|---|---|---|---|
| Agent simulation testing | ✅ Synthetic conversation testing with thousands of scenarios | ❌ No simulation capabilities | LangWatch |
| Automated prompt optimization | ✅ Automated, systematic prompt optimization | ❌ Manual prompt engineering only | LangWatch |
| LLM evaluation framework | ✅ Pre-built evaluators plus auto-generated custom ones both UI and CI/CD | ✅ Has evaluation capabilities | LangWatch |
| OpenTelemetry integration | ✅ Built on OpenTelemetry standard, framework-agnostic | ❌ Proprietary instrumentation | LangWatch |
| Collaborative workflows | ✅ Dual interface for domain experts and developers | ❌ Developer-focused interface | LangWatch |
| Trace visualization | ✅ Built for nested agent calls and complex workflows | ✅ Built on ML monitoring foundation | Tie |
| Dataset management | ✅ Automatically created from traces, integrated workflow | ❌ Available but separate from tracing | LangWatch |
| Deployment model | ✅ Cloud, self-hosted (free), and hybrid options | ✅ Cloud and on-prem | LangWatch |
LangWatch's agent simulation testing and automated optimization catch issues before production while enabling cross-functional teams to collaborate effectively. Start with LangWatch's free tier →
2. Confident AI: AI quality standardization across teams
Confident AI is an AI quality platform built to standardize evaluations and observability across multiple product teams. It provides full tracing across LLM calls, agents, tools, and retrieval steps, alongside online evaluations and signals that monitor application quality on real production traffic.
Pros
-
Standardization for evaluations and observability across product teams
-
Full tracing for LLM, RAG, and agent workflows
-
Online evaluations and signals on production traffic
-
Native red teaming and vulnerability monitoring
-
AI governance across pre-deployment and production
-
Vendor- and stack-agnostic
Cons
-
More extensive than smaller teams with a single AI application may need
-
No agent simulation testing for multi-turn conversations
-
Observability pricing is based on GB-month usage, which can make costs less predictable as trace volume grows
Pricing
Free plan available. Paid plans scale with usage, with custom and self-hosted options.
Best for
Companies with multiple product teams that want to standardize how they evaluate, monitor, and secure AI applications, rather than leaving each team to define quality independently.
3. Langfuse: Open-source LLM observability platform
Langfuse offers an open-source observability platform with trace logging, prompt management, and basic analytics. The open-source and self-hosting option appeals to teams with strict data policies.
Pros
-
Fully open-source with self-hosted deployment
-
Manual annotation system for marking problematic outputs
-
Session grouping for multi-turn conversation debugging
-
Active community and abundant documentation
-
Cost tracking across providers
Cons
-
No built-in eval runners or scorers - you build everything yourself
-
No CI/CD integration for automated testing
-
No collaboration with PM's, Data Scientists.
-
No agent simulation capabilities
-
No automated prompt optimization
-
Basic trace viewing without experiment comparison or statistical analysis
-
Self-hosting requires dedicated DevOps resources
Pricing
Free for open-source self-hosting. Paid cloud plan starts at $29/month with custom enterprise pricing.
Best for
Teams requiring open-source self-hosted deployment with full data control who have resources to build custom evaluation and optimization pipelines from scratch.
Read more on LangFuse <> LangWatch.
4. LangSmith: LangChain ecosystem observability
LangSmith is the observability platform built by the LangChain team. It traces LangChain applications automatically and provides evaluation tools designed specifically for LangChain workflows.
Pros
-
Zero-config tracing for LangChain and LangGraph applications
-
Automatic instrumentation with single environment variable
-
Dataset versioning and test suite management
-
Experiment comparison interface
-
LLM-as-judge evaluation for correctness and relevance
Cons
-
Works best within LangChain ecosystem, less flexible for other frameworks
-
No agent simulation testing capabilities
-
No automated prompt optimization framework
-
Costs scale linearly with request volume
-
Self-hosted deployment only on Enterprise plans
-
Deep LangChain integration creates switching costs
Pricing
Free tier with 5K traces monthly for one user. Paid plan at $39/user/month with custom enterprise pricing including self-hosting.
Best for
Teams running their entire LLM stack on LangChain or LangGraph who prioritize zero-config framework integration over flexibility and agent testing capabilities.
5. Helicone: Proxy-based LLM observability
Helicone provides proxy-based observability: route your LLM calls through its proxy with a base-URL change and it captures prompts, responses, token usage, and costs, with no SDK or code changes.
Pros
-
No-code setup through a proxy integration
-
Fast to get basic observability and cost tracking live
-
Built-in caching to reduce API spend
-
Virtual API keys for cost attribution across teams and projects
-
Supports major providers including OpenAI and Anthropic
Cons
-
Adds a network hop between your app and the LLM provider
-
Minimal evaluation or quality scoring
-
No agent simulation testing
-
Proxy reliance can become a single point of failure
Pricing
Free tier available. Paid plans scale with request volume.
Best for
Teams that want immediate LLM cost and request visibility with minimal setup and no code changes.
Arize alternative feature comparison
| Feature | LangWatch | Confident AI | Langfuse | LangSmith | Helicone |
|---|---|---|---|---|---|
| Distributed tracing | ✅ | ✅ | ✅ | ✅ | ✅ |
| Agent simulation testing | ✅ Thousands of scenarios | ❌ | ❌ | ❌ | ❌ |
| Automated prompt optimization | ✅ | ❌ | ❌ | ❌ | ❌ |
| Evaluation framework | ✅ 20+ built-in evaluators | ✅ | ✅ Build yourself | ✅ | ❌ |
| Online evals on production traffic | ✅ | ✅ | ❌ | Partial | ❌ |
| Native red teaming | ✅ | ✅ | ❌ | ❌ | ❌ |
| CI/CD integration | ✅ | ✅ | ✅ Guides | Partial | ❌ |
| OpenTelemetry native | ✅ | ✅ | ❌ | ❌ | ❌ |
| Collaborative workflows | ✅ Dual interface | ✅ | ❌ | ❌ | ❌ |
| Prompt versioning | ✅ | ✅ | ✅ | ✅ | ❌ |
| Dataset management | ✅ Auto from traces | ✅ | ✅ | ✅ | ❌ |
| Self-hosting | ✅ Free unlimited | ✅ Option | ✅ Free unlimited | ✅ Enterprise only | ✅ |
| Multi-provider support | ✅ 800+ models | ✅ | ✅ | ✅ | ✅ |
| Cost tracking | ✅ | ✅ | ✅ | ✅ | ✅ |
| Free tier | Generous + unlimited self-hosting | Free plan | 50K units | 5K traces | Free tier |
Choosing the right Arize alternative
Choose LangWatch if: You need agent simulation testing, multi-turn agent testing, automated prompt optimization, OpenTelemetry-native integration, or cross-functional collaboration between developers and domain experts.
Choose Langfuse if: Open-source self-hosting is mandatory and you have resources to build custom agent testing and optimization pipelines from scratch.
Choose Confident AI if: You need to standardize evaluation and observability across many product teams with governance and native red teaming, rather than agent simulation for a single product.
Choose LangSmith if: Your entire stack runs on LangChain/LangGraph and deep framework integration outweighs the need for agent simulation and optimization.
Choose Helicone if: You want the fastest no-code observability and cost tracking through a proxy and do not need evaluation or agent testing.
Final recommendation
LangWatch covers the entire LLM development lifecycle for agentic AI, including agent simulation testing, comprehensive evaluation, and production observability. The platform uniquely enables domain experts and developers to collaborate through dual interfaces while maintaining OpenTelemetry compatibility for vendor independence.
Companies building AI agents use LangWatch to test thousands of scenarios before production, automatically optimize prompts systematically, and maintain quality through collaborative evaluation workflows. The open-source offering provides unlimited self-hosting at no cost.
Get started free or explore the documentation to see how LangWatch handles agent testing, optimization, and observability for production LLM applications.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.
Frequently asked questions
- What are the best Arize AI alternatives in 2026?
- Strong Arize alternatives include LangWatch for agent simulation and evaluation, Confident AI for eval and observability standardization across teams, Langfuse for open-source flexibility, LangSmith for LangChain users, and Helicone for proxy-based observability.
- Why do teams look for Arize AI alternatives?
- Arize was built ML-first, so teams building production LLM agents often hit gaps like no agent simulation testing, limited prompt optimization, and evaluation and tracing living in separate workflows.
- Which Arize alternative is best for testing AI agents?
- LangWatch is the most complete option for agent testing. Its Scenario framework simulates multi-turn and voice-agent conversations with a User Simulator and a Judge Agent, runnable in CI/CD as merge-blocking gates, which Arize and most alternatives cannot do.
- Does Arize have a free tier for LLM tracing?
- Arize Phoenix offers a free tier with 25K trace spans per month for one user. LangWatch provides a generous free tier plus unlimited free self-hosting with no feature restrictions, including agent simulation and evaluation.
- Can I self-host LangWatch for free?
- Yes. LangWatch is open source under Apache-2.0 and self-hosts free with no feature limits via Docker or Kubernetes, with hybrid and EU, US, UK, and APAC options and ISO 27001 and GDPR compliance.
- Which platform is best for cross-functional collaboration?
- LangWatch was designed for cross-functional teams with a dual interface: domain experts create and review evaluations in the UI without coding, while developers build via APIs and SDKs, so technical and non-technical stakeholders share ownership of AI quality.