Top 4 Humanloop Alternatives in 2025
Looking for a Humanloop alternative? These are top platforms for LLM evaluation, agent testing, and observability.
 Manouk Draisma · July 18, 2025 · LLM Evals
Manouk Draisma · July 18, 2025 · LLM EvalsWhether you're building AI agents, experimenting with LLM applications, or scaling AI infrastructure, LLM ops tooling is no longer optional, it's foundational. As teams move from prototypes to production, the need for robust systems to monitor, evaluate, and iterate on AI workflows have become critical.
Humanloop emerged as a popular solution for managing LLM workflows, prompt optimization, and evaluation. The platform provided prompt versioning, A/B testing capabilities, and evaluation frameworks that helped teams systematically improve their AI applications. Many teams relied on Humanloop for prompt management, model comparison, and basic evaluation workflows.
But with Humanloop sunsetting its platform in September 2025, teams are now evaluating alternatives that can meet their evolving needs in AI development and deployment.
Here we’ll evaluate four leading Humanloop alternatives that help you and your team build, scale, and evaluate your AI agents and LLM apps.
Top 4 Humanloop Alternatives
1. LangWatch
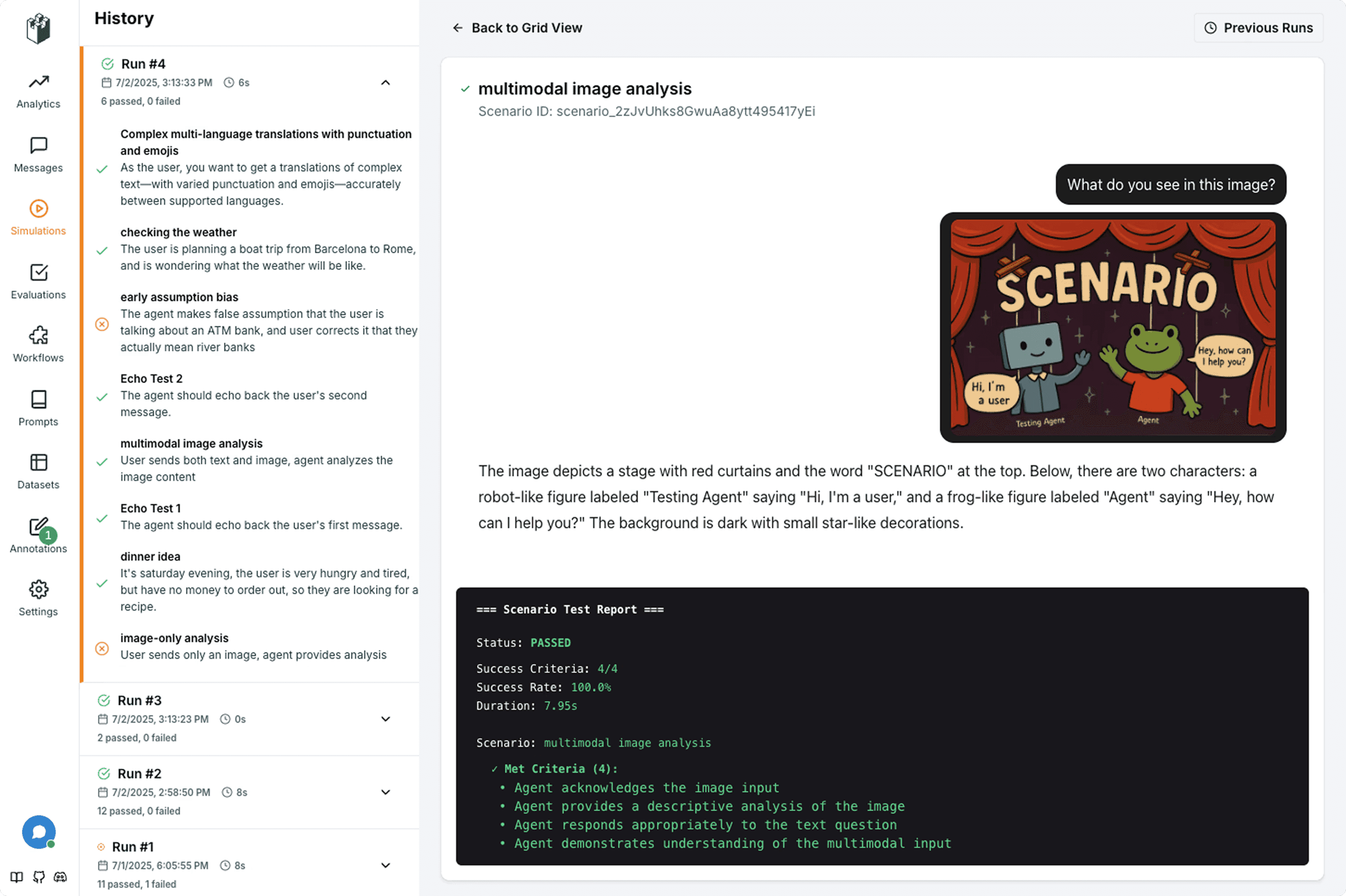
LangWatch is an LLM engineering platform for systematic testing and monitoring of AI applications and agents. We built it to address the gaps most AI teams face when moving from prototypes to production systems.
Core capabilities:
Agent Simulations & Systematic Testing: Multi-step agent simulations that test complex workflows. Simulate real user behavior, test edge cases, and catch regressions automatically.
Domain Expert Collaboration: Non-technical stakeholders can define evaluation criteria, annotate problematic outputs, and contribute to AI quality without coding. Medical experts can evaluate clinical accuracy, financial analysts can assess compliance.
Flexible Deployment Options: Cloud, VPC, or fully on-premise deployment. Complete data sovereignty with ISO27001 certification, GDPR compliance, and EU AI Act alignment.
Production Monitoring: Real-time monitoring with structured feedback capture and complete traceability. When issues surface, trace every decision back to its source and convert problems into automated test cases.
Framework Integration: Works with any AI framework or model provider. Integrates with existing development workflows through CI/CD pipelines and supports OpenTelemetry standards.
**Why Choose LangWatch?
**LangWatch works for AI teams that need systematic AI quality beyond basic evaluation. If you're in an enterprise company in a regulated industry, need domain expert collaboration, or require deployment flexibility, LangWatch provides the infrastructure most teams actually need.
2. LangSmith
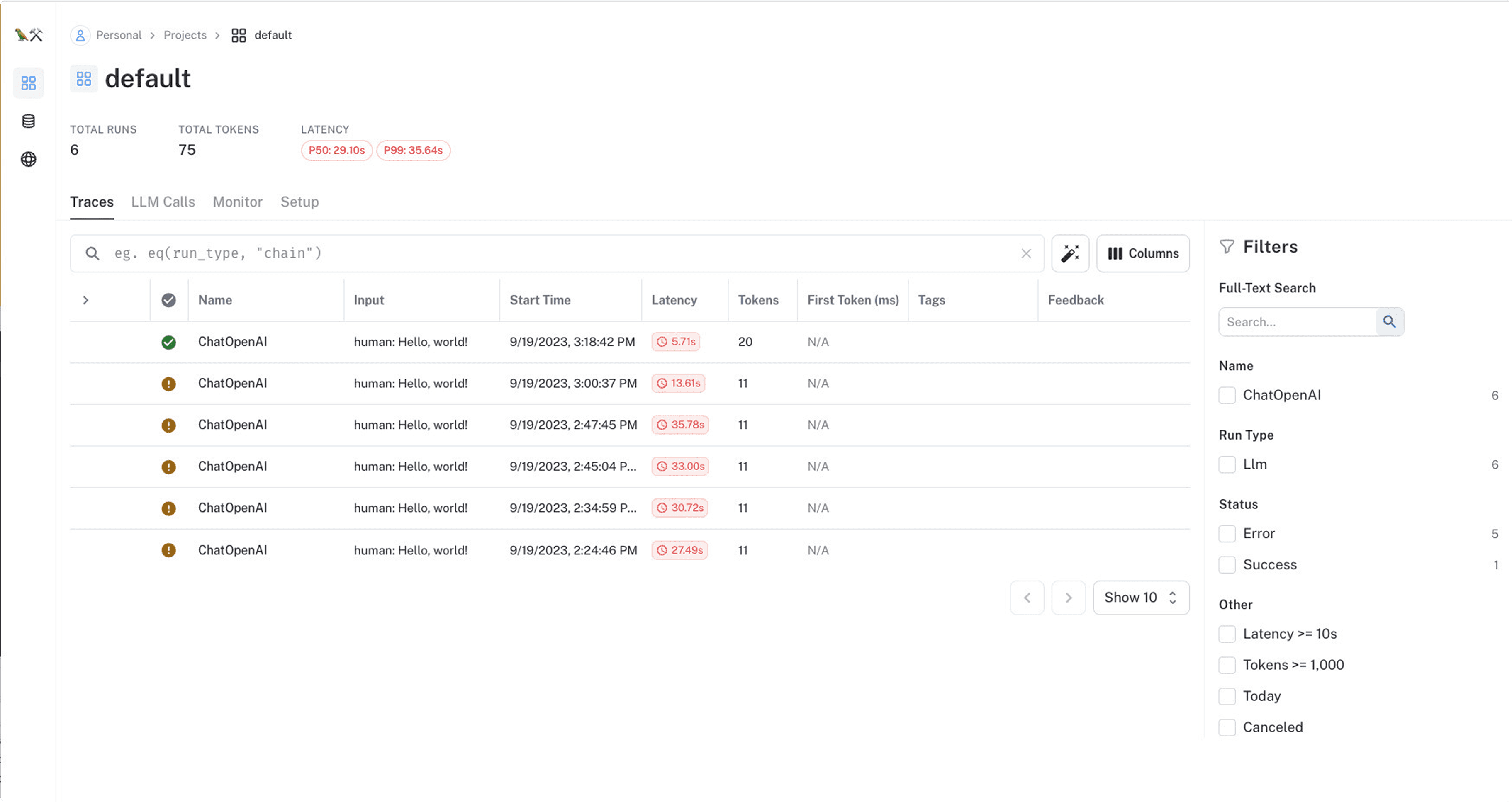
LangSmith is the observability and evaluation platform from the creators of LangChain. If your team builds primarily with LangChain, LangSmith provides native integration and deep visibility into chain and agent execution.
Core Capabilities:
-
Integrated tracing for LangChain workflows with step-by-step visibility
-
Prompt versioning and comparison tools for systematic prompt tuning
-
Evaluation frameworks supporting automated and human feedback
-
Production monitoring with performance metrics and health checks
-
Metadata tagging and custom metrics for analysis
**Why Choose LangSmith?
**LangSmith works well if you build primarily with LangChain and need robust observability tools. The native integration eliminates instrumentation overhead and the evaluation capabilities are solid for teams focused on chain optimization.
LangSmith is built primarily for the LangChain ecosystem. If you need broader framework support, flexible deployment options, or collaboration tools for non-technical stakeholders, you'll need additional platforms.
3. Langfuse
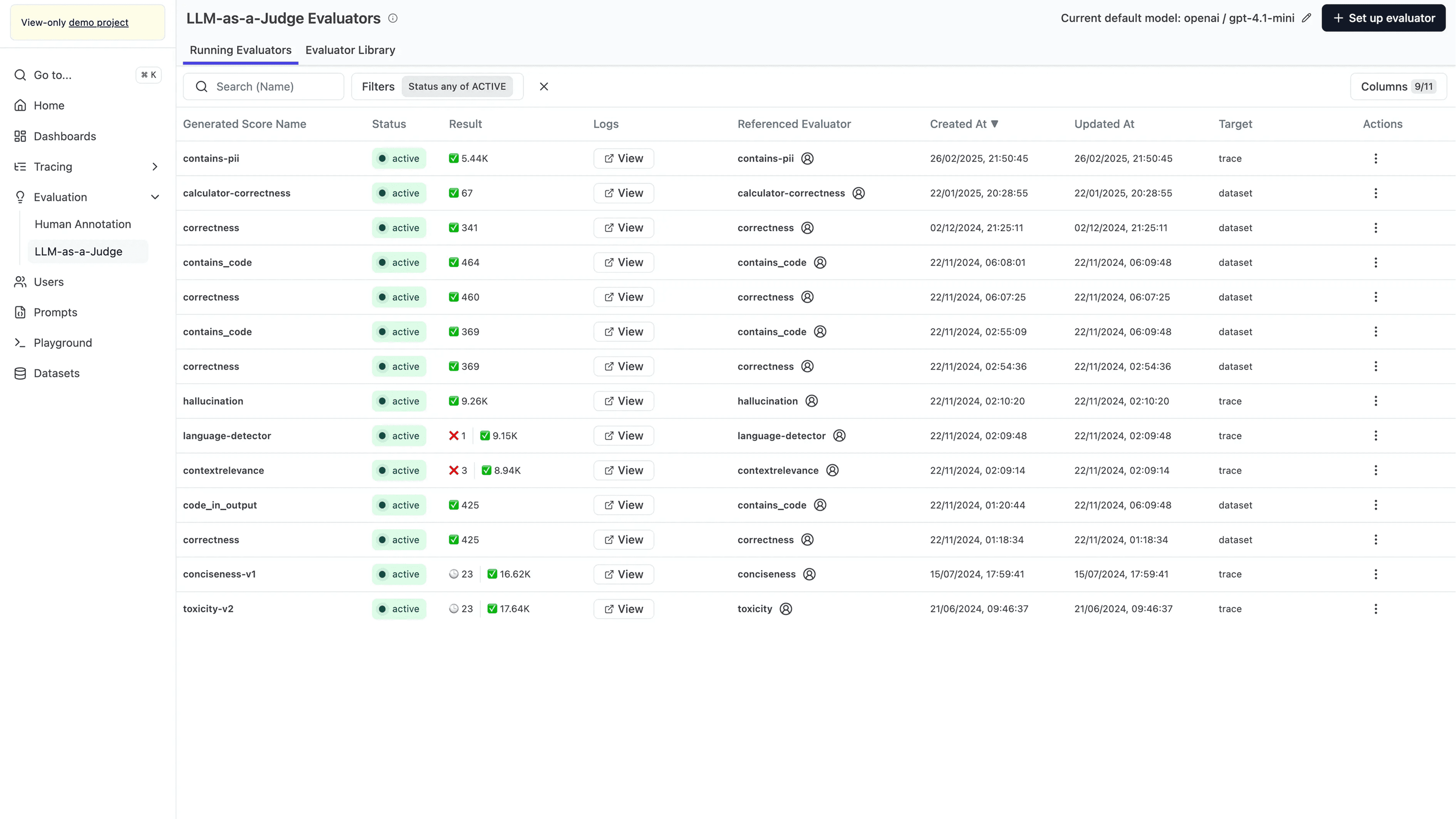
Langfuse is an open-source observability and evaluation platform focused on LLM application monitoring and performance tracking. The open-source approach provides transparency and control that proprietary platforms can't match.
Key Features:
-
Real-time tracing and debugging with detailed execution visibility
-
Evaluation and feedback collection through test datasets and human scoring
-
Custom metadata, metrics, and tagging for analytics
-
Both hosted and self-hosted deployment options
-
Active community and development
**Why Choose Langfuse?
**Langfuse works for teams that prioritize open-source solutions and need deep LLM observability. The self-hosted option provides data control, and the community-driven development ensures continued evolution.
Langfuse focuses on observability and evaluation but doesn't provide orchestration, systematic agent testing, or collaboration tools for domain experts. You'll likely need additional platforms for a complete solution.
4. Braintrust
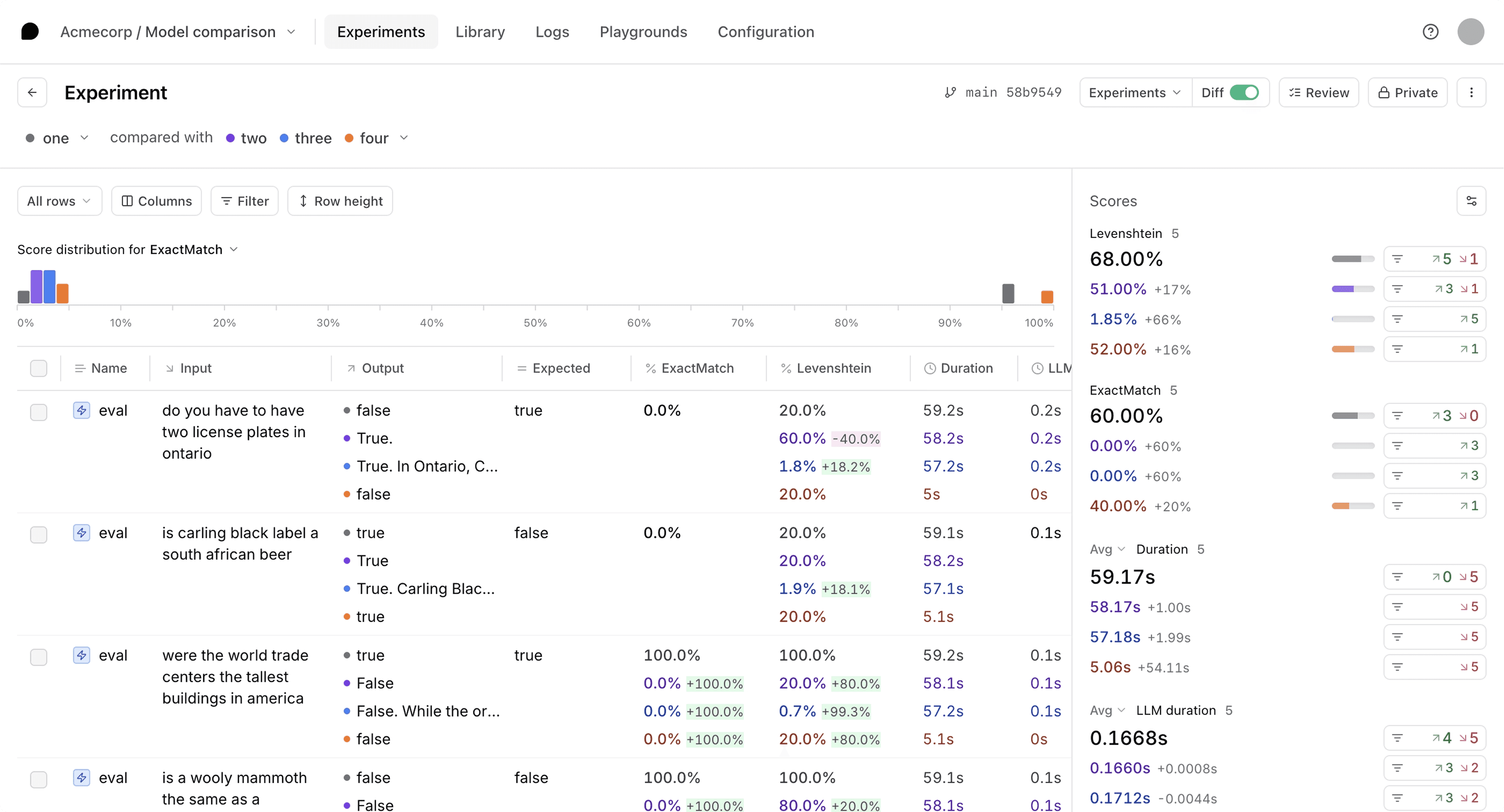
Braintrust is an evaluation platform with focus on systematic testing and performance tracking for AI applications.
Platform Capabilities:
-
Systematic evaluation frameworks with automated scoring
-
Dataset management and test case organization
-
Performance tracking and regression detection
-
Team collaboration features for evaluation workflows
-
Integration capabilities with existing development tools
**Why Choose Braintrust?
**Braintrust offers solid evaluation capabilities with business-focused features. The platform emphasizes systematic testing approaches and provides collaboration tools for technical teams.
Braintrust primarily serves technical users and may lack the domain expert collaboration features that many teams need for comprehensive AI quality management.
Choosing the Right Humanloop Alternative
Choose LangWatch if you need:
-
Flexible deployment options (cloud, VPC, on-premise)
-
Domain expert collaboration without coding requirements
-
Systematic agent testing beyond basic prompt evaluation
-
Compliance and security controls for regulated use cases
Choose LangSmith if you:
-
Build primarily with LangChain and need native integration
-
Want robust observability for chain and agent workflows
-
Have technical teams comfortable with the LangChain ecosystem
Choose Langfuse if you:
-
Prioritize open-source solutions and community development
-
Need self-hosted deployment for data control
-
Focus primarily on observability and performance monitoring
Choose Braintrust if you:
-
Need systematic evaluation with technical team collaboration
-
Want business-focused evaluation capabilities
-
Have primarily technical users managing AI quality
Humanloop Alternatives: Key Takeaways
With Humanloop sunsetting in September 2025, many teams are reassessing their LLM tooling needs. Whether you're focused on prompt optimization, agent testing, or production monitoring, there's no one-size-fits-all solution. The right platform depends on your team's technical requirements, collaboration needs, and deployment constraints.
If your focus is observability and you're building primarily with LangChain, LangSmith offers deep integration and robust tracing capabilities. For teams that prioritize open-source solutions and self-hosted deployment, Langfuse provides transparency and community-driven development. Braintrust serves technical teams that need systematic evaluation with good collaboration features.
But if your team needs systematic agent testing, domain expert collaboration, and flexible deployment options that work for both startups and regulated industries, LangWatch provides the comprehensive platform for moving from prototype to production with confidence.
Ready to migrate from Humanloop? Book a migration consultation (or email us at support@langwatch.ai) to discuss your specific needs or try LangWatch directly to explore our systematic testing and monitoring capabilities.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.