Top 5 AI evaluation tools for AI agents & products in production (2026)
Discover the top 5 AI evaluation tools in 2026. Compare LangWatch, Braintrust, Arize, and others for testing, monitoring, and improving LLM applications in production
 Manouk Draisma · January 30, 2026 · LLM Evals
Manouk Draisma · January 30, 2026 · LLM EvalsAI evaluation platforms measure and improve AI system quality through automated testing, production monitoring, and continuous validation**.** Teams that skip proper evaluation only discover problems after deployment - chatbots provide incorrect answers, code assistants generate broken code, or recommendation systems drift off target.
The challenge with AI systems is their non-deterministic nature. Manual testing with a handful of examples doesn't scale. Production-grade evaluation solves this through:
-
Systematic testing with comprehensive datasets covering edge cases and common scenarios
-
Automated scoring using custom evaluators, LLM-as-judge, and heuristic checks
-
Continuous monitoring that catches quality degradation before users complain
-
Regression prevention by converting failures into permanent test suites
Best for complete LLMOps: LangWatch - AI testing platform with integrated evaluation, agent simulations, and prompt management workflows.
Best for ML/LLM combination: Arize Phoenix - Production monitoring with strong compliance and drift detection capabilities.
Best for Automated Quality Checks: Galileo - Model-powered evaluation with Luna EFM for hallucination detection.
Best for solo-developers: Langfuse - observability
This comprehensive guide examines the AI evaluation platforms in 2026, analyzing their strengths, limitations, and ideal use cases to help you select the right tool for your team.
Platform Comparison Overview
| Platform | Best For | Open Source | Offline Eval | Online Eval | Agent Testing | Starting Price |
|---|---|---|---|---|---|---|
| LangWatch | Full LLMOps lifecycle | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Agentic scenarios | Free tier |
| Braintrust | Development-to-production workflow | ❌ No | ✅ Yes | ✅ Yes | ✅ Multi-step | Free tier |
| Arize | Enterprise ML + LLM monitoring | ✅ Phoenix | ✅ Yes | ✅ Yes | ⚠️ Limited | Free tier |
| Maxim | Agent simulation | ❌ No | ✅ Yes | ✅ Yes | ✅ Simulation-focused | Free tier |
| Galileo | Automated hallucination detection | ❌ No | ✅ Yes | ✅ Yes | ⚠️ Basic | Free tier |
What is AI Evaluation
AI evaluation is the systematic measurement of AI system performance using automated scoring, production monitoring, and continuous testing against quality standards.
Effective evaluation operates across two distinct phases:
Pre-deployment Testing (Offline Evaluation)
Offline evaluation validates changes before they reach users:
-
Execute AI systems against curated test datasets with known expected outcomes
-
Calculate performance metrics including accuracy, relevance, safety, and domain-specific measures
-
Create performance baselines that inform future comparisons
-
Test variations in prompts, models, parameters, and system configurations
This phase answers: Will this change improve the system? What edge cases still fail? Did we introduce new problems?
Production Validation (Online Evaluation)
Online evaluation maintains quality after deployment:
-
Automatically score live user interactions as they occur
-
Monitor for quality degradation, hallucinations, policy violations, and unexpected behaviors
-
Analyze performance trends across time periods and user segments
-
Combine automated scoring with human review for complex cases
This phase answers: Is the system performing as expected? Are users experiencing issues? What patterns indicate problems?
For generative AI and LLMs, evaluation transforms unpredictable outputs into measurable signals. It answers critical questions: Did this prompt improve the performance? Which message types cause failures? Did the LLM update bring any regressions? Teams use these signals to gate deployments, compare approaches objectively, and prevent quality issues from reaching production.
5 Leading AI Evaluation Platforms (2026)
1. LangWatch
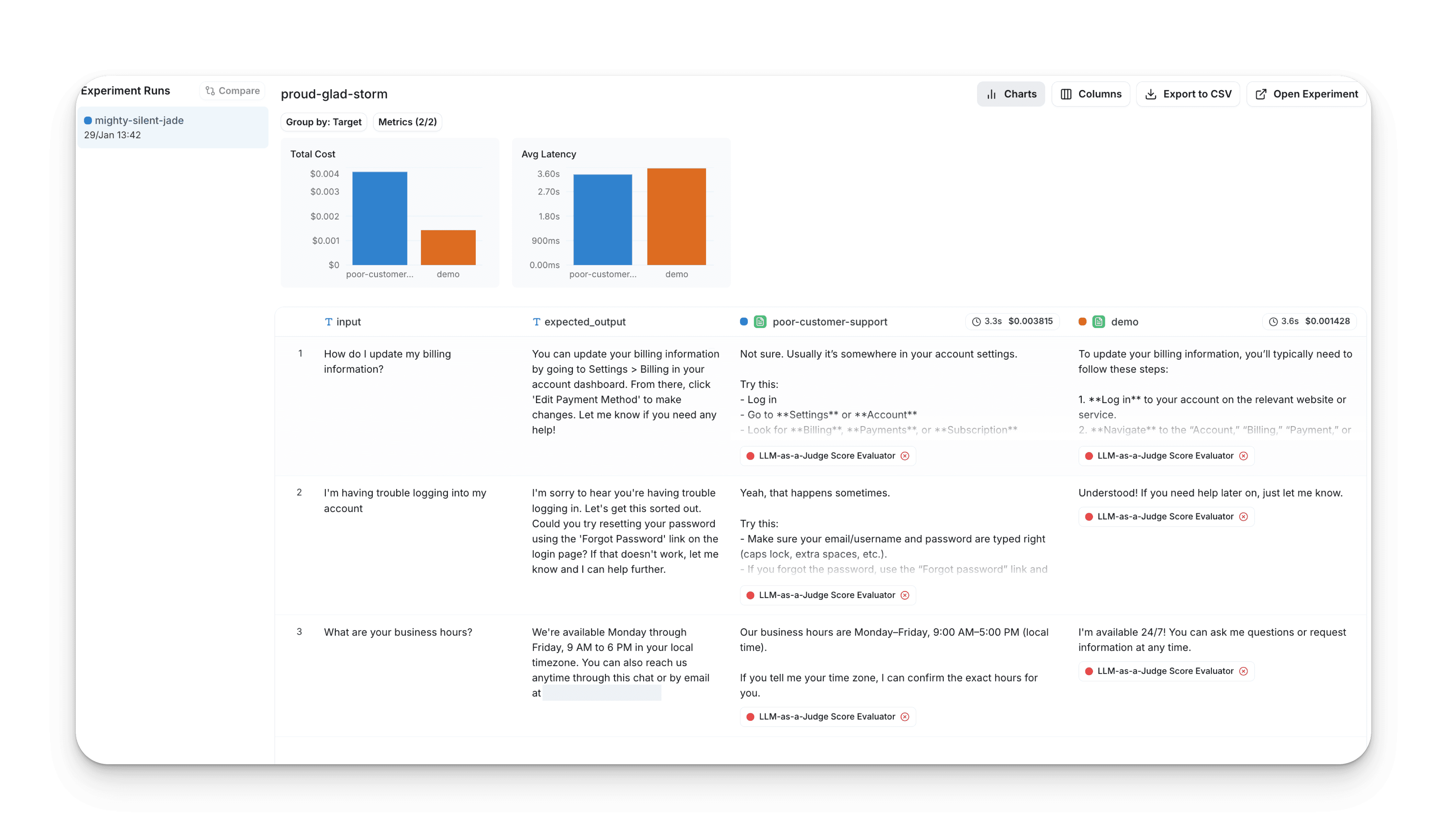
LangWatch delivers the most complete AI evaluation as part of a complete LLMOps platform. The system integrates offline experiments, online monitoring and agent simulations into a unified development experience.
Offline evaluation enables systematic testing through batch experiments. Teams create datasets from production traces or curated test cases, then run comprehensive evaluations using built-in evaluators or custom scoring logic. The platform tracks performance across prompt iterations, model changes, and configuration updates.
Online evaluation monitors production quality automatically. Configure evaluators to run on live traffic, set sampling rates to control costs, and receive alerts when quality degrades. The system scores outputs asynchronously without adding latency to user requests.
Real-time evaluation integrates with triggers and alerts that notify teams via Slack, PagerDuty, or custom webhooks when issues arise. This creates rapid feedback loops between detection and resolution.
Agent testing (simulations) provides sophisticated validation through the Scenario framework. Create agentic tests that simulate realistic user interactions using User Simulator Agents that generate natural conversations and Judge Agents that evaluate outcomes in real-time.
Simulation Sets group related scenarios into comprehensive test suites, while Batch Runs execute all scenarios together. Debug mode allows stepping through conversations turn-by-turn, enabling developers to intervene and explore different interaction paths.
Human-in-the-loop workflows complement automated evaluation. The annotation system enables domain experts to review production traces, add labels, and provide qualitative assessments. These annotations feed directly into evaluation datasets and help identify patterns automated systems miss.
Unified development workflow eliminates tool fragmentation. Flow from observing production traces to creating datasets to running evaluations to optimizing prompts without switching platforms. Engineers and domain experts collaborate in shared interfaces rather than working in isolation.
Best for: Teams wanting evaluation, observability, and optimization integrated into a single open-source platform.
Key Strengths
-
Complete LLMOps integration: Evaluation works seamlessly with observability, datasets, annotations, and optimization in one platform
-
Agentic testing capabilities: User Simulator and Judge Agents enable realistic multi-turn validation that traditional testing approaches miss
-
Open-source transparency: Full code visibility with 2,500+ GitHub stars and active community development
-
OpenTelemetry-native: Framework-agnostic integration through open standards rather than vendor-specific SDKs
-
Human + automated workflows: Combines automated scoring with annotation workflows for comprehensive quality assessment
-
Self-hosting flexibility: Deploy in your infrastructure via Docker for complete data control
-
Comprehensive evaluator library: Built-in evaluators for common checks plus custom evaluator support
-
User event tracking: Captures thumbs up/down, text selection, and custom events for evaluation signals
Pricing
-
Free tier: Self-host unlimited or cloud with generous limits
-
Cloud Pro: Usage-based pricing for higher volumes
-
Enterprise: Custom pricing with advanced features and support
-
View pricing details
3. Arize
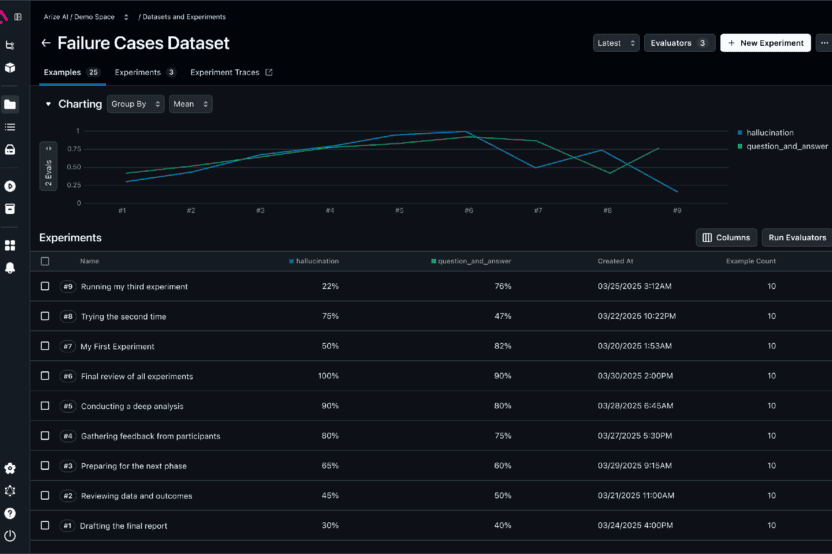
Arize extends traditional ML monitoring to LLM evaluation through Phoenix. The platform provides comprehensive production monitoring with strong enterprise compliance features.
Best for: Enterprises running both classical ML models and LLMs that need unified monitoring with strong compliance requirements.
Key Strengths
-
Open-source Phoenix option for self-hosting with full transparency
-
Advanced drift detection for embeddings and model behavior
-
Production monitoring expertise from ML observability background
-
Session-level tracing for complex multi-step interactions
-
Real-time alerting and prebuilt monitoring dashboards
Considerations
-
Evaluation features less integrated than specialized platforms
-
More emphasis on monitoring than pre-deployment testing workflows
-
Some advanced features require external tooling or custom development
Pricing
-
Free: Phoenix self-hosting (open-source)
-
Cloud: Starting at $50/month for managed service
-
Enterprise: Custom pricing with compliance features
3. Galileo
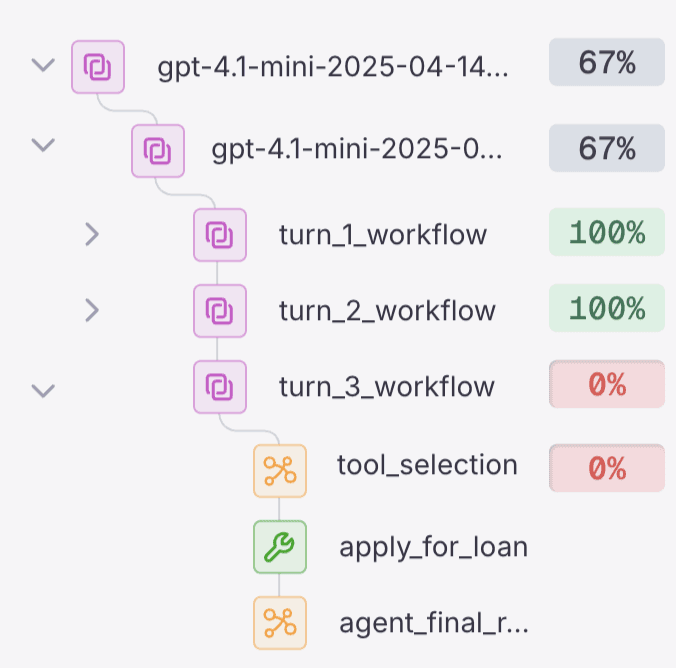
Galileo provides automated evaluation through Luna, specialized models fine-tuned for evaluation tasks like hallucination detection, prompt injection identification, and PII detection.
Best for: Organizations needing automated, model-driven evaluation at scale where manual review isn't feasible.
Key Strengths
-
Luna evaluation models provide specialized quality checks without manual review
-
ChainPoll multi-model consensus for confidence in evaluation results
-
Automated hallucination and factuality detection at scale
-
Real-time production guardrails for policy enforcement
-
Comprehensive documentation for evaluation workflows
Considerations
-
Evaluation depends on vendor-maintained models rather than open alternatives
-
Less flexibility for teams preferring self-hosted evaluation logic
-
Initial setup requires investment in understanding Luna model capabilities
Pricing
-
Free: 5,000 traces/month
-
Pro: $100/month (50,000 traces/month)
-
Enterprise: Custom pricing
4. Confident AI
Confident AI focuses specifically on LLM evaluation and testing, helping teams systematically measure, debug, and improve model behavior before and after deployment. The platform is designed around evaluation-first workflows rather than broad observability.
Best for:
Teams building LLM-powered products that need evaluation workflows to catch quality regressions, prompt issues, and model failures early.
Key Strengths
-
Simple setup for defining custom metrics, test cases, and expected outputs
-
Good support for regression testing across prompts, models, and datasets
-
Developer-friendly workflows oriented around fast iteration and experimentation
-
Clear separation between evaluation logic and application code
-
Useful for validating changes before pushing to production
Considerations
-
Limited production observability compared to full LLM monitoring platforms
-
Less emphasis on runtime tracing, agent-level debugging, or complex pipelines
-
Compliance and enterprise governance features are still relatively lightweight
-
Not designed for collaboration with teams including PM's data scientist.
Pricing
-
Free: Limited evaluation runs and basic features
-
Pro: Usage-based pricing for teams scaling evaluation workloads
-
Enterprise: Custom pricing for larger teams and advanced needs
AI Evaluation Tools Detailed Comparison
| Platform | Starting Price | Standout Features | Primary Focus |
|---|---|---|---|
| LangWatch | Free (generous limits) | Agentic testing with User Simulator and Judge Agents, OpenTelemetry-native, Collaboration with PM's, self-hosting, evaluation + observability + optimization integration | Complete LLMOps platform |
| Arize | Free (Phoenix) / $50/month (Cloud) | Phoenix open-source, drift detection, HIPAA/SOC 2 compliance, ML + LLM unified monitoring, session tracing | Enterprise ML observability |
| Galileo | Free (5K traces/month) | Luna evaluation models, ChainPoll consensus, automated hallucination detection, real-time guardrails, factuality checking | Model-powered evaluation |
| Confident AI | Free | Open source, dev friendly | Developers |
Why LangWatch excels for AI Evaluation
LangWatch transforms AI evaluation from an isolated activity into an integrated part of the complete development lifecycle. Rather than juggling separate tools for observability, testing, and optimization, teams work in a unified platform where evaluation insights directly inform improvements.
The LangWatch evaluation workflow:
-
Production monitoring → Dataset creation: Convert real user interactions into evaluation datasets with one click
-
Agentic simulations / testing → Comprehensive validation: Run User Simulator and Judge Agents to test multi-turn behaviors at scale
-
Automated + human evaluation → Quality insights: Combine built-in evaluators with domain expert annotations for comprehensive assessment
-
Prompt Management → Systematic improvement: Use Prompt Studio to improve prompts based on evaluation results and auto-optimizers
-
Continuous monitoring → Quality assurance: Online evaluators catch regressions and quality drift in production
Integrated platform advantages: The same traces powering observability feed into evaluation datasets. Evaluation results inform optimization experiments. Optimized prompts deploy with continuous monitoring. This tight integration eliminates handoffs and accelerates iteration cycles.
With 4,000+ GitHub stars and active community development, LangWatch provides transparency and control. Self-host for maximum data privacy or use the cloud version for operational simplicity
Teams using LangWatch report shipping AI agents 8x faster and an increase of 30% quality improvement. The platform brings systematic, measurable quality management that transforms experimental prototypes into production-ready systems.
Start evaluating with LangWatch →
When LangWatch might not fit
LangWatch provides comprehensive evaluation as part of a complete LLMOps platform. Consider alternatives in these specific scenarios:
-
Evaluation-only needs: Teams wanting only evaluation without observability or optimization might prefer specialized evaluation-only tools, though most teams benefit from the integrated approach.
-
Existing tool investments: Organizations deeply committed to existing observability or evaluation platforms may face migration costs, though LangWatch's OpenTelemetry-native approach simplifies integration with existing tools.
-
Minimal agent complexity: Applications with simple single-turn interactions may not need advanced agentic testing capabilities, though they still benefit from other evaluation features.
Frequently Asked Questions about AI Evaluation Tools
What is the best AI evaluation tool for production systems?
LangWatch is the best and complete AI evaluation tool because it integrates evaluation with observability, agent testing, and optimization in a single open-source platform. It excels at agentic testing with User Simulator and Judge Agents, provides both offline and online evaluation capabilities. It takes the approach of simulations, coming from the robotic industry - The OpenTelemetry-native approach ensures compatibility with any framework while providing specialized AI evaluation capabilities.
What metrics matter most in AI evaluation?
Essential metrics combine universal quality checks with application-specific measurements.
Universal metrics (for all AI systems):
-
Hallucination detection: Does output contain fabricated or unsupported information?
-
Safety validation: Policy violations, harmful content, bias detection, prompt injection attempts
-
Format compliance: Correct JSON structure, required fields, schema adherence
-
Latency and cost: Response time and token consumption
Application-specific metrics:
-
RAG systems: Retrieval precision, answer faithfulness, context relevance
-
Code generation: Syntax validity, test passage, compilation success, security vulnerabilities
-
Customer support: Issue resolution rate, response appropriateness, sentiment analysis
-
Content generation: Factual accuracy, tone consistency, brand alignment
Effective evaluation combines deterministic metrics (fast, cheap, reproducible) with LLM-as-judge scoring (for subjective qualities like tone or creativity), tracking both during development and production.
Can AI evaluation tools test multi-agent systems?
Yes. Modern AI evaluation platforms test multi-agent systems by recording inter-agent communication, tool usage, and state transitions, then evaluating both individual steps and complete workflows. LangWatch's agentic testing framework uses User Simulator Agents to generate realistic conversations and Judge Agents to evaluate outcomes, enabling comprehensive validation of multi-turn agent behaviors that traditional testing approaches cannot capture. This approach tests agent reasoning, tool selection, error recovery, and collaborative behaviors.
How should teams choose an AI evaluation platform?
Select based on these critical requirements:
-
Workflow integration: Does evaluation integrate with your development process or require separate tools?
-
Agent testing capabilities: Can you test multi-step agent behaviors realistically?
-
Evaluation flexibility: Support for custom scorers, LLM-as-judge, and heuristic checks?
-
Production monitoring: Automated online evaluation with alerting and trend analysis?
-
Dataset management: Easy creation from production traces or curated test sets?
-
Cross-functional access: Can both engineers and domain experts contribute to evaluation?
-
Open-source vs. proprietary: Control, transparency, and self-hosting requirements?
LangWatch addresses all requirements through its integrated platform both via CI/CD and through the platform.
What distinguishes offline from online AI evaluation?
Offline evaluation validates AI systems before deployment using fixed datasets with known expected outputs. It catches issues during development, establishes performance baselines, and validates changes before they reach users. Teams use offline evaluation for systematic testing, A/B comparison of approaches, and regression detection.
Online evaluation scores production traffic automatically as it arrives, monitoring real user interactions for quality issues, safety violations, and performance degradation. It provides real-world validation that offline testing cannot capture, including edge cases and user interaction patterns not present in test datasets.
The most effective platforms use consistent scoring frameworks across both offline and online evaluation, ensuring that pre-deployment testing accurately predicts production behavior. LangWatch, Braintrust, and others provide unified evaluation that works identically in both contexts.
What do AI evaluation tools cost in 2026?
Most platforms offer free tiers suitable for testing, with paid plans scaling based on usage volume, team size, and advanced features. While Arize, Braintrust seems to be cheaper at first hand, once usage scales, price increases. LangWatch starts with a user-based priced tier, but once you scale in production with more messages they become reliably good in their costs.
How do evaluation tools prevent AI system regressions?
Evaluation platforms prevent regressions through continuous testing and automated gates:
-
Test case libraries: Convert production failures and edge cases into permanent test suites
-
CI/CD integration: Run evaluations on every code change and block merges that decrease quality metrics
-
Baseline tracking: Compare new performance against established benchmarks to detect degradation
-
Automated alerts: Notify teams immediately when production quality drops below thresholds
-
Version comparison: Track performance across prompt changes, model updates, and configuration tweaks
LangWatch excel at this by making failed production cases automatically become regression tests, while platforms like Maxim use simulation to catch issues before production deployment.
Can AI evaluation tools integrate with existing CI/CD pipelines?
Yes. Modern evaluation platforms provide CI/CD integration through GitHub Actions, webhooks, and programmatic APIs. Teams configure evaluation jobs that run on pull requests, block merges when quality decreases, and post detailed results as comments. LangWatch supports batch evaluation through its API and SDK and native GitHub Actions integration. This automation ensures every code change undergoes quality validation before reaching production.
What makes agentic testing different from traditional evaluation?
Agentic testing simulates realistic multi-turn interactions rather than evaluating isolated inputs and outputs. Traditional evaluation tests single prompts with fixed inputs, while agentic testing creates dynamic conversations where User Simulator Agents generate realistic user behaviors and Judge Agents evaluate the complete interaction. This approach catches issues in multi-step reasoning, tool usage, error recovery, and contextual understanding that single-turn evaluation misses entirely. LangWatch's Scenario framework and Maxim's simulation capabilities exemplify this approach.
How do teams balance automated and human evaluation?
Effective evaluation combines automated scoring for scale with human judgment for nuance:
Automated evaluation handles:
-
High-volume production scoring that would be impractical manually
-
Deterministic checks (format validation, policy violations, PII detection)
-
Comparative metrics across large datasets
-
Continuous monitoring for regression detection
Human evaluation provides:
-
Subjective quality assessment for tone, creativity, appropriateness
-
Edge case identification and labeling
-
Ground truth creation for training automated evaluators
-
Complex judgment requiring domain expertise
LangWatch's annotation system enables domain experts to review traces and add labels without writing code, feeding these insights back into automated evaluation. This hybrid approach achieves both scale and quality.
Can evaluation tools work with custom LLM deployments?
Yes. Evaluation platforms supporting OpenTelemetry or flexible SDK integrations work with any LLM deployment. LangWatch's OpenTelemetry-native approach means it captures traces from custom models, self-hosted deployments, and proprietary LLM implementations as easily as it works with OpenAI or Anthropic. Teams instrument their code once using OpenTelemetry standards, then send traces to any compatible evaluation platform without vendor lock-in.
How do evaluation platforms handle sensitive data?
Evaluation tools protect sensitive data through multiple approaches:
-
Self-hosting: Platforms like LangWatch and Arize Phoenix offer Docker deployment in your infrastructure
-
Data isolation: Keep evaluation data within your security perimeter
-
Encryption: Data at rest and in transit protection
-
Access controls: Role-based permissions for viewing evaluation results and datasets
-
Compliance certifications: SOC 2, GDPR, HIPAA support for regulated industries
-
PII detection: Automated identification and redaction of personal information
Open-source platforms provide full code transparency for security audits, while managed services offer compliance certifications for enterprise requirements.
What integrations do AI evaluation platforms provide?
Leading platforms integrate with:
Development tools:
-
GitHub (automated PR evaluation, comments, merge gates)
-
GitLab, Bitbucket (CI/CD pipelines)
-
VS Code, IDEs (local testing)
Communication and alerting:
-
Slack, Discord (quality alerts, team notifications)
-
PagerDuty (incident management)
-
Email, webhooks (custom integrations)
AI frameworks:
-
LangChain, LlamaIndex (tracing and evaluation)
-
OpenAI, Anthropic, other LLM providers
-
Vercel AI SDK, custom frameworks via OpenTelemetry
Data platforms:
-
Cloud storage (S3, GCS) for datasets
-
Data warehouses for analytics
-
BI tools for reporting
LangWatch's OpenTelemetry-native approach provides maximum integration flexibility without requiring framework-specific SDKs.
How long does it take to implement AI evaluation?
Implementation time varies by platform and requirements:
Quick setup (hours to days):
-
Basic tracing integration via OpenTelemetry
-
Simple evaluators using built-in metrics
-
Cloud-hosted platforms with managed infrastructure
Moderate setup (days to weeks):
-
Custom evaluators for domain-specific quality checks
-
Dataset curation from production traces
-
Think about quality and what good means.
-
Agentic testing scenario development
-
CI/CD pipeline integration
Advanced setup (weeks to months):
-
Self-hosted deployment with custom infrastructure
-
Complex multi-agent testing frameworks
-
Enterprise compliance requirements
-
Migration from existing evaluation systems
Platforms like LangWatch emphasize quick time-to-value with pre-built integrations, while maintaining flexibility for advanced customization as teams mature their evaluation practices.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.
Frequently asked questions
- What are the best AI evaluation tools in 2026?
- The top AI evaluation tools include LangWatch for full LLMOps and agent simulations, Braintrust for development-to-production workflows, Arize for enterprise ML and LLM monitoring, Maxim for agent simulation, and Galileo for automated hallucination detection.
- What is AI evaluation?
- AI evaluation is the systematic measurement of AI system performance using automated scoring, production monitoring, and continuous testing against quality standards, spanning offline pre-deployment testing and online production evaluation.
- Why use LangWatch for AI evaluation?
- LangWatch combines integrated evaluation, agentic scenario testing, online and offline evals, and prompt management in one platform, helping teams catch quality degradation before users do.