Why Agentic AI needs a new layer of testing
Testing AI agents does require a new way of testing. Using Unit tests, Evaluations, Agent evaluations, simulations brings you a better way of agentic testing
 Manouk Draisma · December 12, 2025 · Agents
Manouk Draisma · December 12, 2025 · Agents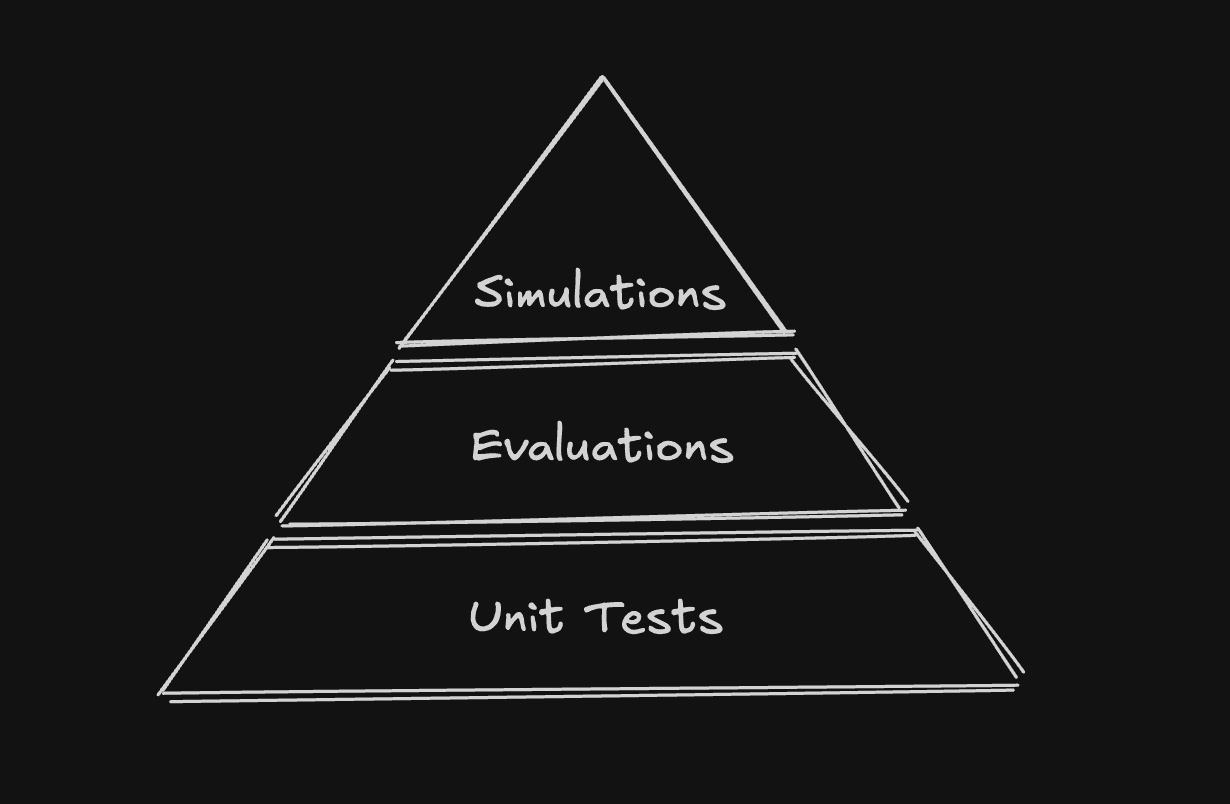
Software testing has always relied on a familiar structure: unit tests at the bottom, integration tests in the middle, and end-to-end tests at the top. For decades, that model held firm. We knew how to reason about software because the systems we were building were deterministic. If something failed, you could usually trace it to a function, a dependency, or an interface.
Agentic AI breaks that certainty.
Agents reason. They choose tools. They reorder steps based on context. They respond differently to the same input, depending on seemingly insignificant variables. They operate over multiple turns. And their behavior changes not only when you update code, but when you adjust a prompt or when your model provider quietly rolls out a new version.
Teams discover this the moment they push an agent into production: the traditional testing pyramid no longer explains the quality problem. Something is missing.
This article introduces the missing layer, explains why it exists, and describes how Skai adopted it in practice while deploying Celeste - their enterprise marketing agent - using LangWatch and Flagsmith together. The result is a reliable testing process for systems that were previously untestable.
The limits of traditional testing
The failure mode is easy to observe.
A small prompt edit meant to improve phrasing ends up altering the entire reasoning chain. An LLM update changes which tool an agent selects in step four, even though step one looks identical. A new feature interacts with an older one in an unexpected way. Slight shifts propagate in nonlinear directions.
This brittleness is inherent to the architecture. Agents are not pipelines; they are policies.
And because of this, traditional tests - unit tests, integration tests, static evals - capture only fragments of agent behavior. They confirm that individual components function correctly, but they cannot approximate how the system behaves when these components interact dynamically over time.
Agents expose an uncomfortable truth: functionality is no longer the primary failure mode. Behavior is.
A real example: Skai’s deployment of AI agents
When we invited Lior, Lead AI Architect at Skai, to speak during our joint webinar with Flagsmith, we brought him forward early for a reason. His team has been operating at the frontier of agentic systems, deploying Celeste to customers who depend on accurate marketing insights across multiple channels.
Celeste is capable of synthesizing large volumes of advertising data, answering detailed performance questions, and surfacing optimization recommendations. These are high-impact decisions that affect real budgets.
Skai quickly recognized the central difficulty: before adding any new feature, they needed to understand not just whether the feature worked, but whether it interacted correctly with all the existing capabilities of the agent.
As Lior put it:
“Agents are brittle. Any small change can cascade into behavior you didn’t expect. We needed a way to test the workflow, not just the final answer.”
The team experimented with different structures, but eventually converged on an approach that is becoming increasingly common across the industry:
a three-layer testing methodology tailored specifically for agentic systems.
The agent testing pyramid
Testing agents requires a new mental model, one that acknowledges deterministic software, probabilistic components, and autonomous behavior as distinct layers.
The Agent Testing Pyramid captures this structure.
1. Unit and integration tests: deterministic foundations
At the bottom of the pyramid is everything traditional testing already handles well.
APIs, tool backends, business logic, data transformations, memory interfaces, and authentication flows should behave deterministically. These pieces must remain stable regardless of how the agent reasons.
Even in systems driven by LLMs, this layer matters. It isolates failures that have nothing to do with reasoning or language and provides quick feedback loops for structural reliability.
But it offers no visibility into the behavior of the agent itself.
2. Evals and optimization: Improving probabilistic components
The middle layer evaluates the building blocks that influence agent behavior without defining it.
Retrievers, classifiers, parsers, safety filters, and reasoning prompts all vary in accuracy, robustness, and efficiency. These components are measured through:
-
accuracy metrics
-
win-rate comparisons
-
prompt refinement cycles
-
dataset-driven evaluation
This optimization layer is familiar to ML teams. Improvements here help agents make fewer mistakes, but they still do not capture what happens across a multi-turn workflow.
You can have a high-performing retriever, a strong routing model, and a reliable tool schema - and still end up with an agent that fails a realistic scenario.
Which is why the third layer is essential.
3. Simulations: Behavioral guarantees for multi-turn agents
The top of the pyramid is where the missing piece finally appears: simulations.
A simulation is not a static input-output eval. It is a multi-turn conversational test, executed by a simulated user, in which the agent must behave exactly as expected across an entire workflow.
It allows teams to express intent in a way the model can be judged against:
-
the agent must call a specific tool by step three
-
the agent must ask for missing information
-
the agent must follow the correct recovery path
-
the agent must remain in the appropriate language
-
the agent must complete the task successfully
-
the agent must avoid hallucinatory tool calls
These criteria transform agent behavior into something testable.
Simulations do not approximate correctness; they document it.
How Skai uses LangWatch and Flagsmith together
Skai’s approach illustrates how this pyramid becomes operational in a real engineering environment.
Their workflow includes several steps:
Collecting customer traces
Skai captures production interactions in LangWatch to identify recurring patterns, difficult edge cases, and new opportunities for optimization. These become their “golden datasets.”
Encoding behavioral criteria
For each dataset, Lior’s team defines explicit behavioral expectations. These may concern tool ordering, recovery mechanisms, output formats, or decision points.
Gating features with Flagsmith
New capabilities are introduced behind feature flags. Skai can test permutations of agent configuration without exposing customers to incomplete functionality.
Running simulations in LangWatch
Scenarios interact with Celeste as a real user would. This enables the team to verify behavior across full workflows, not just isolated responses.
Monitoring post-deployment
Once live, LangWatch provides real-time visibility into how Celeste behaves in production. Any deviation, incorrect tool usage, unexpected escalation rates, new hallucination patterns - can be detected early.
When needed, a Flagsmith kill switch immediately deactivates problematic features. The issue then gets encoded into a new simulation, closing the loop and preventing future regressions.
This is how behavioral testing becomes a continuous process rather than a one-time effort.
Why CTOs cannot ignore this shift
Agentic systems introduce a structural change in how software behaves. They require new validation methods - not because testing is now more important, but because the failure modes are fundamentally different.
CTOs who adopt this new testing layer gain several advantages:
-
predictable release cycles even as LLMs evolve
-
faster iteration without increasing risk
-
clear thresholds for acceptable agent behavior
-
reliable comparisons across model versions
-
auditability for compliance and governance teams
-
reduced reliance on manual QA loops
And, most importantly, a way to express and enforce what “good behavior” actually means for an agent.
This is the turning point.
As organizations move from LLM features to fully autonomous agents, simulation testing becomes not just beneficial but necessary.
FAQ: A CTO’s perspective on testing agentic systems
Are simulations simply more advanced evals?
No. Evals measure components. Simulations measure end-to-end behavior. They answer a different question: not whether a step is correct, but whether the entire workflow behaves as intended.
Does this replace unit tests?
It doesn’t. Deterministic infrastructure still requires deterministic guarantees. Simulations assume the foundation works - they do not test it.
How many simulations should a team maintain?
Most teams begin with a small set of high-value scenarios and expand incrementally as they discover new patterns in production. The number grows with maturity, not urgency.
Do simulations slow down releases?
They accelerate them. Teams can update prompts, models, and tools with much lower risk, knowing regressions will be detected immediately.
Should every production bug become a simulation?
Yes. Encoding discovered failures ensures they never repeat. This is one of the fastest routes to improving agent robustness.
What is the ROI of adopting simulation testing?
Teams adopting the Agent Testing Pyramid consistently report fewer customer incidents, smoother model upgrades, faster iteration cycles, and higher internal trust in agentic systems.
Closing thoughts
Agentic AI introduces a new kind of uncertainty, one that cannot be resolved by more deterministic testing alone. The industry is now converging on a new structure: deterministic foundations, probabilistic evaluations, and simulation-based behavioral testing at the top.
Skai’s deployment of Celeste illustrates that this approach is both practical and necessary. With Flagsmith managing feature states and LangWatch validating agent behavior, the team is able to deliver new capabilities without compromising reliability.
As organizations move further into agentic architectures, this new layer of testing becomes not an enhancement, but the baseline required to ship agents responsibly.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.