Writing Effective AI Evaluations, that hold up in production
LLM systems exist in constant motion. Prompts change. Models are swapped. User behavior evolves. New data sources are introduced. Each change reshapes the system’s failure surface.
 Manouk Draisma · December 23, 2025 · LLM Evals
Manouk Draisma · December 23, 2025 · LLM Evals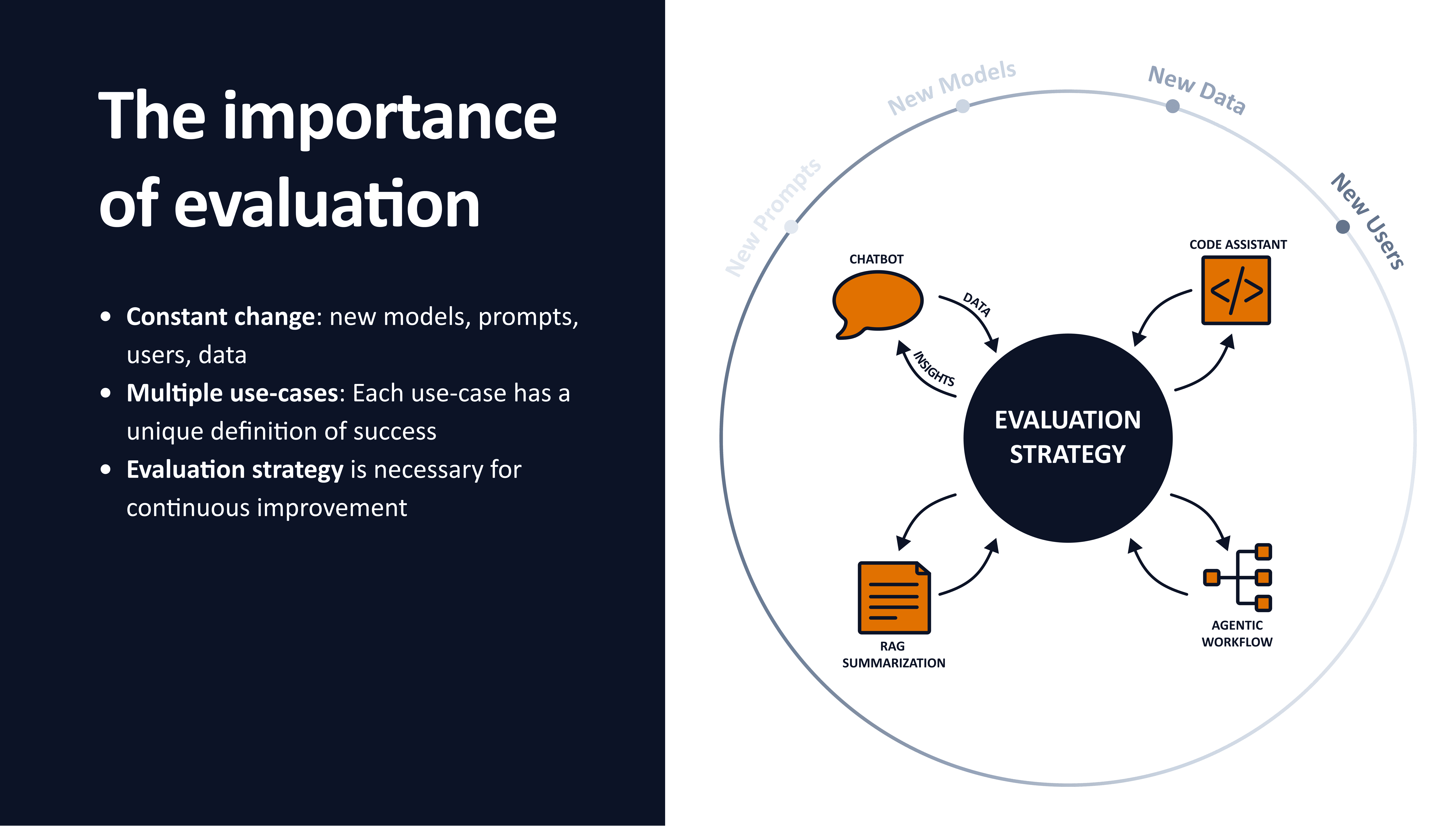
Most LLM systems do not fail dramatically. They fail quietly.
A prototype looks great in a demo, but once it reaches production, subtle issues start to surface. Agents misinterpret intent. Retrieval pulls the right documents but draws the wrong conclusions. Multi-step workflows succeed syntactically while failing semantically.
This happens because evaluation complexity grows faster than most teams expect.
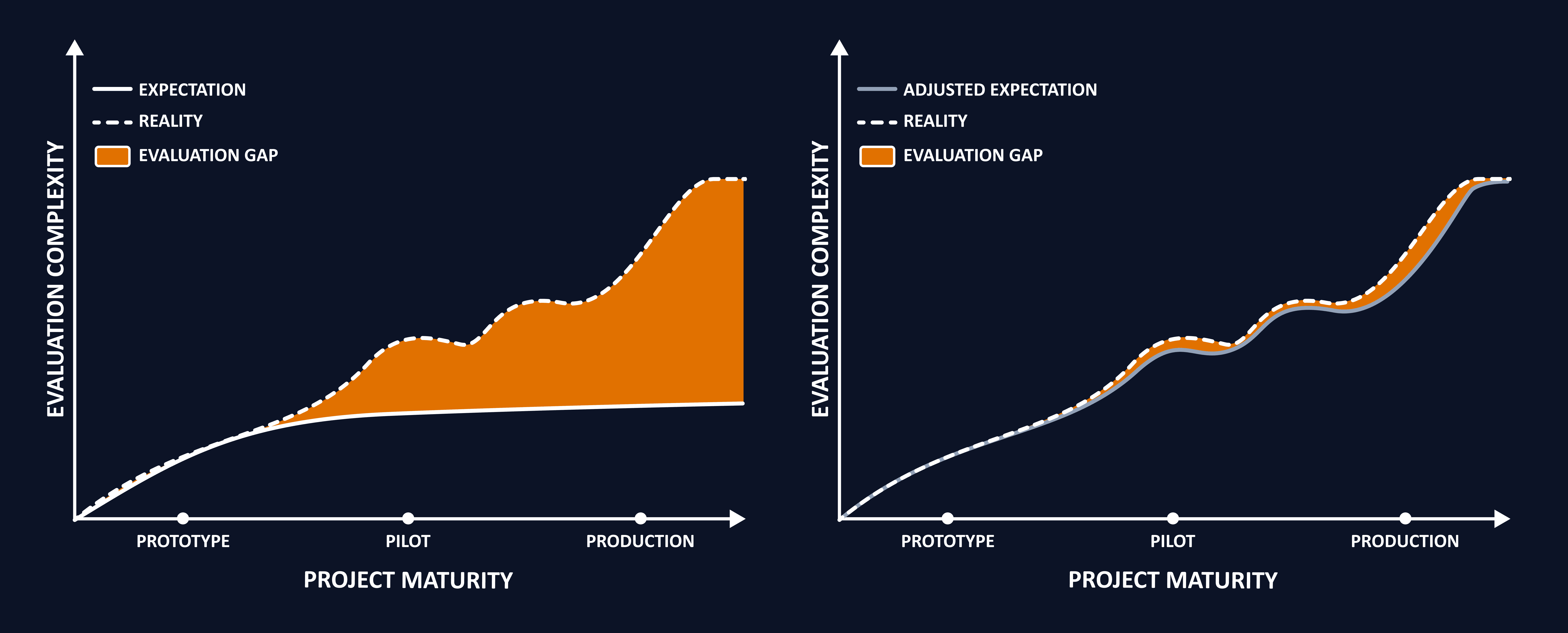
(the chart showing evaluation complexity vs project maturity, with the widening “evaluation gap” and the adjusted expectation curve)
Early on, teams assume evaluation effort will grow linearly. In reality, once you introduce real users, real data, and real workflows, evaluation complexity accelerates sharply. Without adjusting your strategy, you end up with a growing blind spot between what you think you are evaluating and what your system is actually doing.
Evaluation is not a one-time setup
One of the most important mindset shifts is understanding that evaluation is not something you “add at the end.”
LLM systems exist in constant motion. Prompts change. Models are swapped. User behavior evolves. New data sources are introduced. Each change reshapes the system’s failure surface.
(the circular diagram with “Evaluation Strategy” at the center and new models, prompts, data, users around it)
Each use case also defines success differently. A chatbot, a RAG summarizer, a code assistant, and an agentic workflow do not fail in the same way. Treating them with generic metrics is one of the fastest paths to false confidence.
This is why evaluation strategy needs to be central, continuous, and explicitly owned.
Start with error analysis, not metrics
Most teams start evaluation by asking what should we measure?
Strong teams start by asking where does this system actually break?
Error analysis is a qualitative process where humans inspect real execution traces and identify meaningful failures from a product perspective. A trace is not just input and output; it includes prompts, retrieved context, tool calls, intermediate steps, and final responses.
When you review traces systematically, patterns emerge quickly. What looks like dozens of bugs usually collapses into a handful of recurring failure modes: hallucinations, incorrect tool usage, missed escalations, brittle reasoning, or workflow breakdowns.
These observed failures form your failure taxonomy, and that taxonomy should dictate your evaluations. Anything else is guesswork.
This philosophy is heavily inspired by Hamel’s eval work and is foundational to how we approach evaluations at LangWatch.
Evaluation ownership must be explicit
One reason eval initiatives stall is unclear ownership. Evaluation is neither purely an engineering task nor purely a product task.
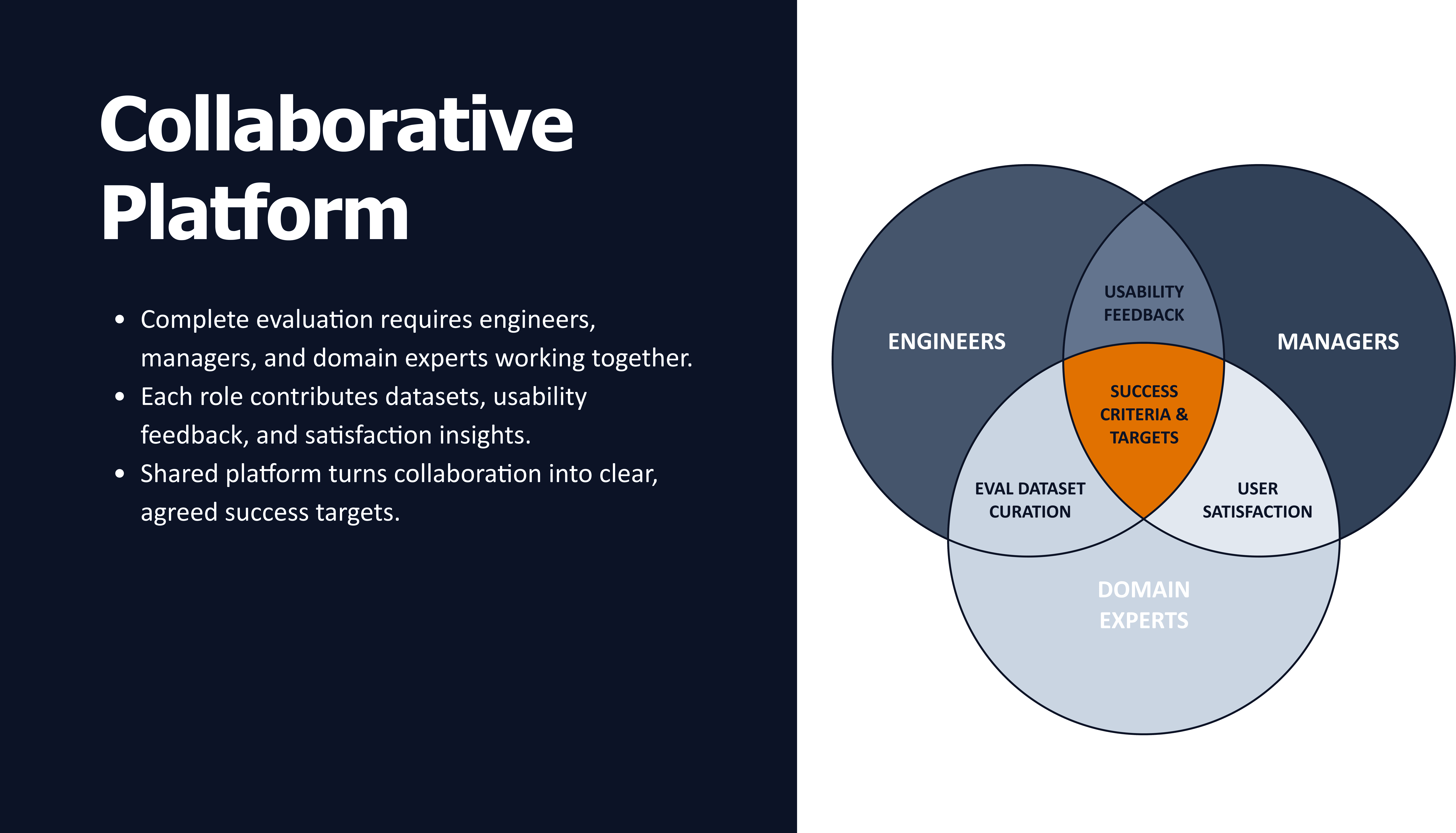
(the table showing responsibility across domain experts, engineers, managers, and the team)
Defining what “good” means requires domain expertise and product judgment. Creating seed datasets often benefits from managers and subject-matter experts. Sampling, labeling, and automation require engineering rigor. Monitoring and iteration require product oversight.
When these responsibilities are explicit, evaluation moves fast. When they are implicit, evals decay or never reach production.
Why binary evaluations outperform abstract scores
A common trap is relying on 1 - 5 ratings for qualities like helpfulness or correctness. These scores feel intuitive but are difficult to operationalize.
A “4 out of 5” response does not tell you whether to ship, block, or fix something. Binary evaluations force clarity. Either the system escalated when it should have, or it didn’t. Either the JSON validated, or it didn’t. Either the agent used the correct tool, or it didn’t.
Binary evals align naturally with CI, regression testing, and production monitoring, which is why they form the backbone of reliable evaluation systems.
The cost hierarchy of evaluators (and why it matters)
Not all evaluators are equal in cost or stability.
Deterministic checks like schema validation, regex rules, and reference assertions are cheap and robust. LLM-as-judge evaluators are powerful but expensive. They require calibration, revalidation, and ongoing maintenance as models evolve.
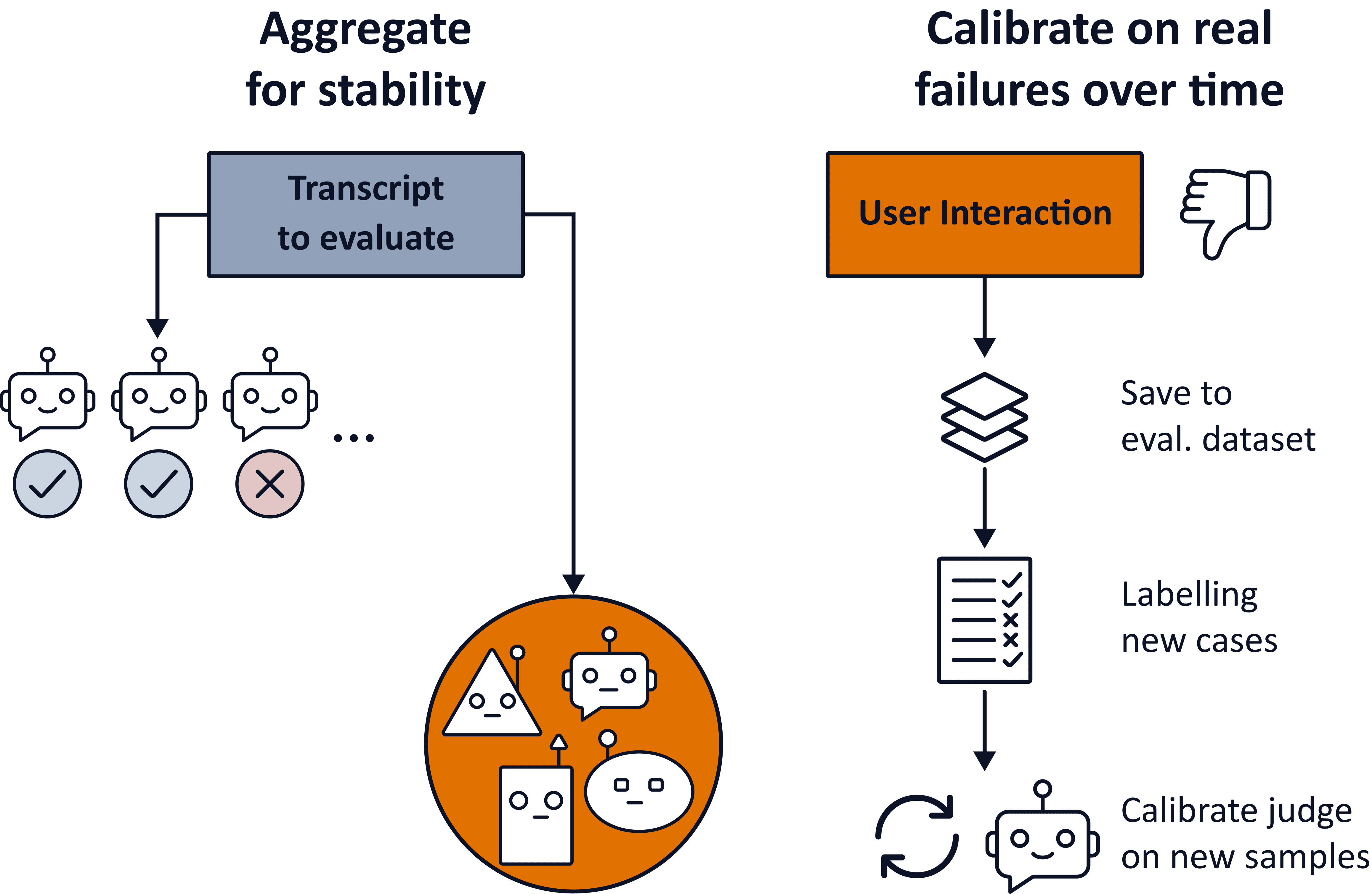
(the diagram showing aggregation for stability and calibration on real failures over time)
LLM judges should be treated as living components. They need continuous calibration using newly observed production failures. Without this feedback loop, they silently drift and lose reliability.
This is why expensive evaluators should be reserved for failure modes that cannot be captured deterministically and are worth the long-term investment.
Evaluating agentic workflows requires a different approach
Agentic systems introduce a step change in evaluation complexity.
(single-turn stateless LLM vs multi-turn stateful agent with memory and tools)
In agentic systems, failures often occur between steps rather than at the final output. An agent might choose the wrong plan, misuse memory, fail to recover from a tool error, or proceed confidently when it should escalate.
Evaluating these systems means evaluating decisions, not just answers. This is why trace-level evaluation and step-specific checks are essential.
At LangWatch, we formalize this through the Agent Testing Pyramid, which structures evaluations from cheap, deterministic checks at the base to more expensive, holistic agent simulations at the top.
You can explore the full framework here:
👉 https://app.langwatch.ai
Where LangWatch fits
LangWatch is built around trace-first evaluation, failure-driven metrics, and cost-aware testing strategies.
Our documentation walks through how to:
-
Capture and inspect traces
-
Perform structured error analysis
-
Build and version evaluation datasets
-
Implement deterministic and LLM-based evaluators
-
Test agentic workflows end-to-end
-
Monitor evals in CI and production
You can explore the docs here:
👉 https://langwatch.ai/docs
Final thoughts
LLM evaluations are not about measuring everything. They are about choosing where automation creates leverage.
Error analysis tells you what to evaluate. Binary, application-specific metrics ensure evals are actionable. Cost-aware evaluator design prevents maintenance debt. Agent-aware testing protects complex workflows.
The real test of an evaluation strategy is simple:
when it passes, do you trust your system more?
If the answer is yes, you are building evals that actually hold up in production.
Ready to game-up your Eval Method? LangWatch offers 1-1 sessions for your team.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.