Eat Sleep Append Repeat…
At LangWatch, we process a not-insignificant number of LLM traces, agentic simulations, evaluations, and experiment runs every single week
 Alex Forbes-Reed · April 20, 2026 · Developer findings
Alex Forbes-Reed · April 20, 2026 · Developer findingsministry of sound 💃🕺
LiveNation can't monopolise all the events
For the past couple of months we have been busy shovelling coal in the LangWatch engine room. Late last year - perhaps during a foul lapse in judgement - we decided to embark on the long and arduous journey to re-architect our platform to be event driven. Fast forward many late nights, a few sweaty migrations, and increasing the market cap of Red Bull by several percentage points, we're live and excited to share what this means for you, and how it super-charges us for 2026 and beyond 🚀.
This is not yet another lame-o "what is event sourcing" post forced into existence by marketing chasing yet another SEO trend, we hope this is actually useful. This is an update of what we’ve ended up with, why it matters for you, and some vanity metrics for good measure (couldn’t skimp on nice big numbers now could we).
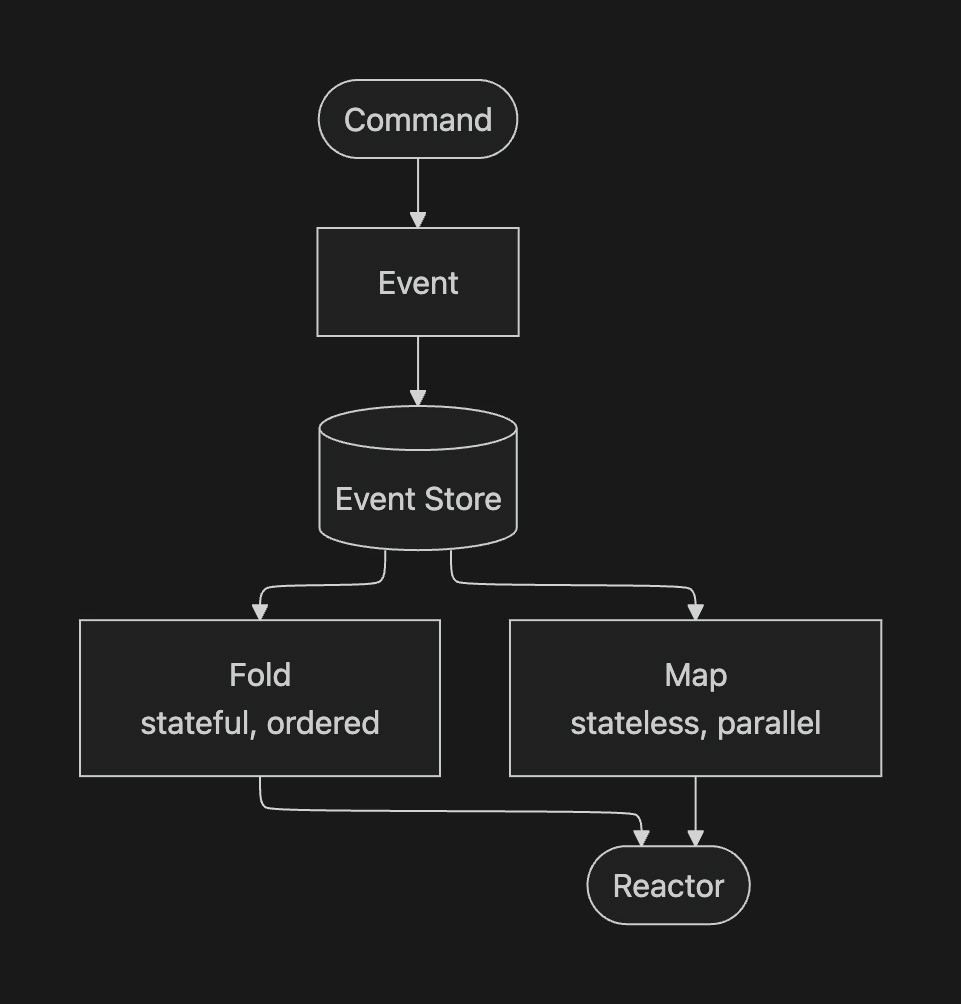
At LangWatch, we process a not-insignificant number of LLM traces, agentic simulations, evaluations, and experiment runs every single week (at least 1, we promise). Every span that hits our collector, evaluation that fires, experiment result that lands, or matrix style simulation battle testing of your agent, they're all events. Immutable, append-only, timestamped facts about what happened in your AI system.
And because they're events, we can do things with them that you simply can't do in a traditional CRUD*-y* architecture.
300x Faster - All Gas… No Breaks
Before this re-architecture, our platform could process 10-20 events per second. That's not a typo, but it got us to where we are today. The bottleneck was ElasticSearch - slow on inserts, which constricted how many jobs we could process concurrently. The system would eventually catch up, but "eventually" started getting longer and longer. Then you lot started scaling your AI systems and 20 events a second started to become a problem more often than not.
The new platform has been running for about a month now, and has already processed 100 million events and counting, and with that that we've seen peak throughput north of 6,000 events per second already. Same servers, same team. We did swap out the database, moving from ElasticSearch to ClickHouse, which turned out to be an almost suspiciously good fit for event sourcing. Append-only writes, columnar storage, absurdly fast aggregations. But the real difference wasn't the database, but rather the architecture on top of it.
Everything that flows through LangWatch (traces, spans, evaluations, experiment results, simulation runs, you get the picture by now) is now an immutable event, appended once and never modified. The system projects event data into whatever views it needs, on the fly, as events arrive. No polling or batch jobs running every five minutes clogging the system up with pointless checks on stale data. Events arrive, we do some clever things instantly, and your dashboards update… in real time. type shit, as our gen-z intern would say.
We can increase event processing capacity simply by scaling out our worker count, hopefully making the majority of startup scaling pains an almost nostalgic memory.
We’re pretty sure no other LLM observability platform is built on this kind of foundation.
Feature Shipping, at an unreasonable pace
Now for some not so subtle flexing. This is the part that gets us out of bed in the morning.
When your platform is built on an event stream, adding a new feature doesn't mean cramming new fields into the data model not desired for it, writing a migration, figuring out how to backfill months/years of data, and praying nothing breaks. It means writing a small function that says "when this event happens, update this view." - yuge, and true.
Our billing usage tracking (counting every billable event per project per day across the entire platform) was an afternoon of work. Not a sprint, or a big project. An afternoon.
But the moment that really drove it home was when we replaced our entire scenario execution engine. We had a full job queue system: scheduling runs, tracking status, handling cancellation. A proper piece of infrastructure. We replaced the whole thing with event sourcing in a single pull request. Once you have an event log, you don't need a separate job queue. The events are the queue.
Your data gets retroactively better
Say we improve our trace processing pipeline. Better cost calculation, smarter input/output extraction, whatever (or even fix a bug, shocking). In a traditional system, that improvement only applies to new data. Everything you've already sent? Tough luck mate.
With event sourcing, we can replay your entire history through the new logic. Your old traces get the benefit of every improvement we ship, automatically. No data loss, no "oopsie, just wait for new data." The raw events are the source of truth, and the views we build from them can always be rebuilt. Harder. Better. Faster. Stronger.
Already live
We have some quick wins already live on production just as a side effect of the new system. These aren’t roadmapped or a loosey goosey todo list, but ready for you now.
-
Live trace updates: your browser updates the moment a span arrives. No refresh, no polling.
-
Real-time simulations: agentic simulations, via the scenario library, are now realtime. No more excuses to get a coffee here, sorry.
-
Usage tracking: real-time billing and usage calculations, per project, per day.
-
Supercharged evaluations and experiments: these should all be running noticeably faster now, which is always nice.
-
Fast is the only mode: the entire platform should be all round snappier, almost instant loading compared to before too.
We're ready. Send us everything.
The more data you throw at the platform, the more useful it gets. More traces means better evaluation baselines and dataset sources. More experiment runs means richer comparisons.
Mo' events, mo' signal, and the system is built to handle it all.
The system is built for whatever load you need. Dev, staging, production - it handles all of it without breaking a sweat. If you've been conservative with your telemetry because you weren't sure we could keep up: we can.
And if there's a feature you've been wishing LangWatch had? Tell us. We're probably only an afternoon away from building it.
Signing off
If you want to know how the sausage is made, stay tuned. We've got a proper technical deep-dive coming next, going into the guts of the event sourcing system, what we learned working with ClickHouse, and all the architectural decisions (and regrets) along the way.
We'll also be sharing how we built the internal tooling to manage all of this infrastructure. Turns out, building developer tools inside a developer tool is its own kind of sadistic adventure.
Curious about event sourcing? If you're new to the concept, Martin Fowler's overview is a great starting point. For something meatier, the Event Store docs go into proper depth.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.
Frequently asked questions
- What throughput did event sourcing unlock for LangWatch?
- The platform went from 10-20 events per second to peak throughput north of 6,000 events per second on the same servers, after moving from Elasticsearch to ClickHouse and adding an event-sourced architecture on top.
- How does event sourcing make old data retroactively better?
- Because raw events are the immutable source of truth, LangWatch can replay your entire history through improved processing logic, so old traces benefit from every fix and improvement without you re-sending anything.
- Why is ClickHouse a good fit for event sourcing?
- ClickHouse offers append-only writes, columnar storage, and very fast aggregations, which match the immutable append-only nature of an event log and make analytics dashboards load almost instantly.