Introducing: LangWatch newest Prompt Playground
Manage, test, and version AI agent prompts with confidence. LangWatch Prompt Playground connects prompts to real traces, evaluations, and optimization workflows.
 Andrew Garde Joia · November 20, 2025 · Product Releases
Andrew Garde Joia · November 20, 2025 · Product ReleasesTL;DR
LangWatch Prompt Playground is a unified workspace for writing, testing, versioning, and managing prompts used in AI agents, across teams and environments. It supports multiple prompts, multiple versions, variations, and model settings - all in one place. Because it lives inside the LangWatch ecosystem, your prompts stay connected to real traces, datasets, analytics, evaluations, and scenario testing - so you're not just tweaking text in isolation, you're improving real production behavior.
So, let’s get into it then, shall we?
The honest reality: Prompt Management is a mess
If you’re building anything non-trivial with LLMs, you probably have something akin to this setup right now:
-
A couple prompts sitting in the OpenAI or Anthropic playground
-
A backup version buried somewhere in your codebase
-
A “golden” version living in a Notion doc, last edited by someone who has since gone on vacation
-
Debug sessions that start with copy-pasting a production prompt into yet another tool > iterating > deciding that it works better > pasting it back into your codebase > shipping it off to production, and hoping for the best, like you’ve just sent your kid back out onto the baseball field with some words of encouragement and their hat on a little less crooked
It kinda worked, right? It’s slow... it’s a bit scary. It’s a bit messy. It was fine when you had three prompts and one developer.
But now your prompt family has grown. There are 6 teams and a handful of engineers and domain experts, all working on the same prompts. You have 15 shared versions saved in Google docs, 5 more in your codebase (in case you need to do a quick rollback because your travel agent just “optimized” the flight manifest and now you have a real crisis), and you’ve copied and pasted and chatted up your agent so many times you’re scared to even look at it in case you bring your whole system down.
So yeah, it doesn’t really work. It’s just “working”.
But it’s typical.
And it’s exactly why we built Prompt Playground.
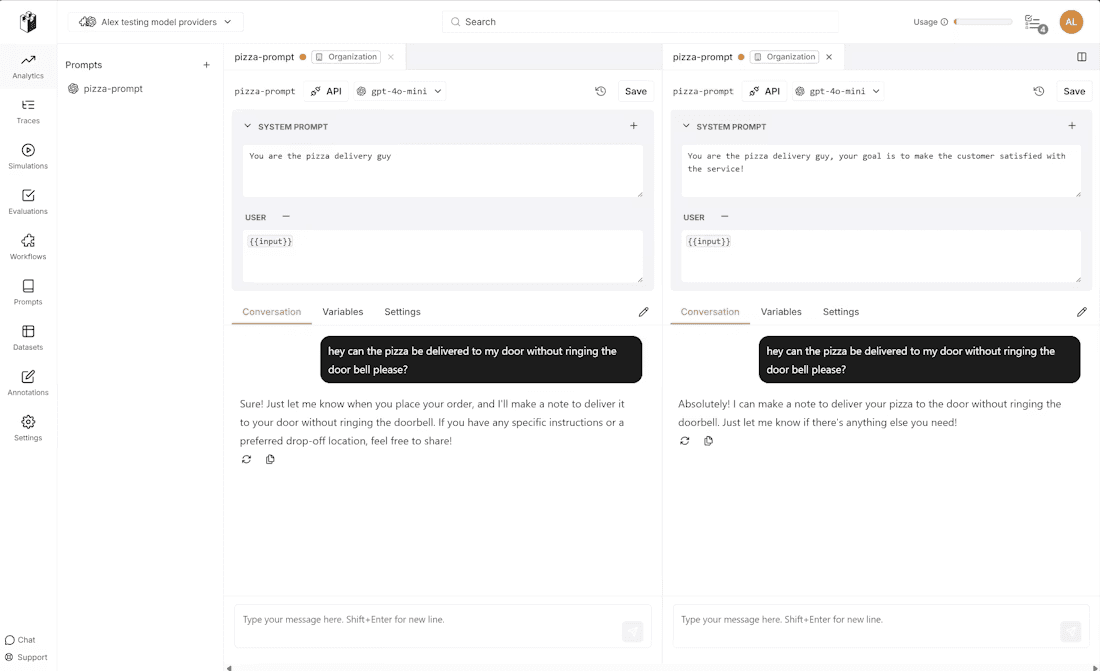
LangWatch Prompt Playground
The LangWatch Prompt Playground
“Is this just another prompt playground?”
“Prompt playgrounds” are everywhere now. Most of them are good at one thing: Letting you poke at a model and see what happens. That’s useful, but it’s just not enough.
At LangWatch, we’re working hard to build a complete picture of what you need to ship your agents with confidence. Prompts are central to this, and so we’ve built our playground to address what we think are the main pain points in the equation.
1. Prompt Organization: One home, not five
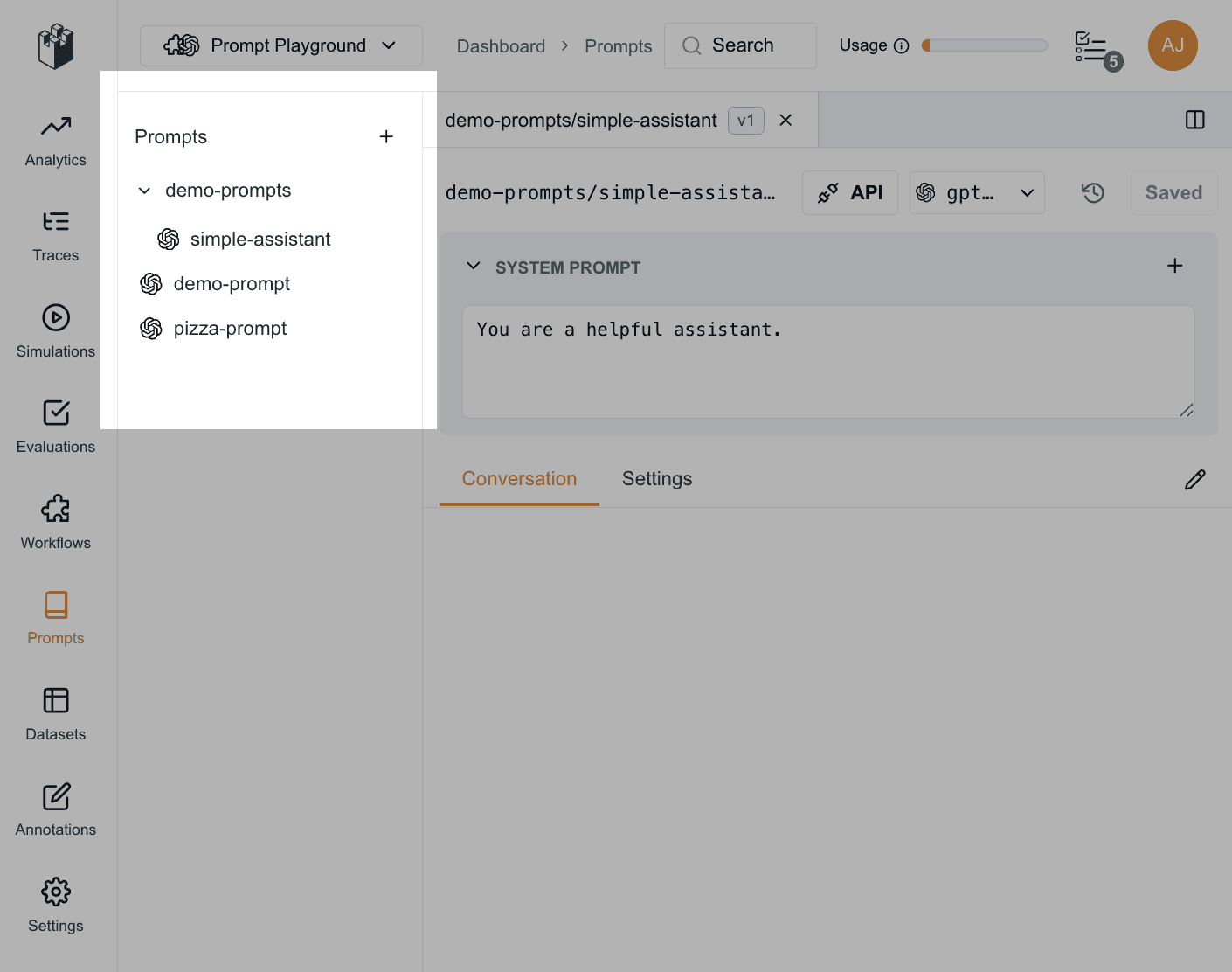
Your prompts are currently couch-surfing between your repo, a Notion doc, excel file and somebody’s head. They should have one obvious, shared home where everyone knows to look.
Prompt Playground gives them a permanent address. Organization, project, and draft prompts are easily found within the prompt navigation, and can be further organized into groups with a simple “/” naming convention.
In short:
-
Project prompts
-
Organization-level prompts
-
Draft prompts
-
Grouping via simple naming conventions like
support/billing/agent-v3You always know where the latest version lives. Everyone does.
**
2. Prompt collaboration**
Today, your prompts are effectively owned by “whoever touched them last.” They should have clear, visible owners and a trail of how they got to their current shape.
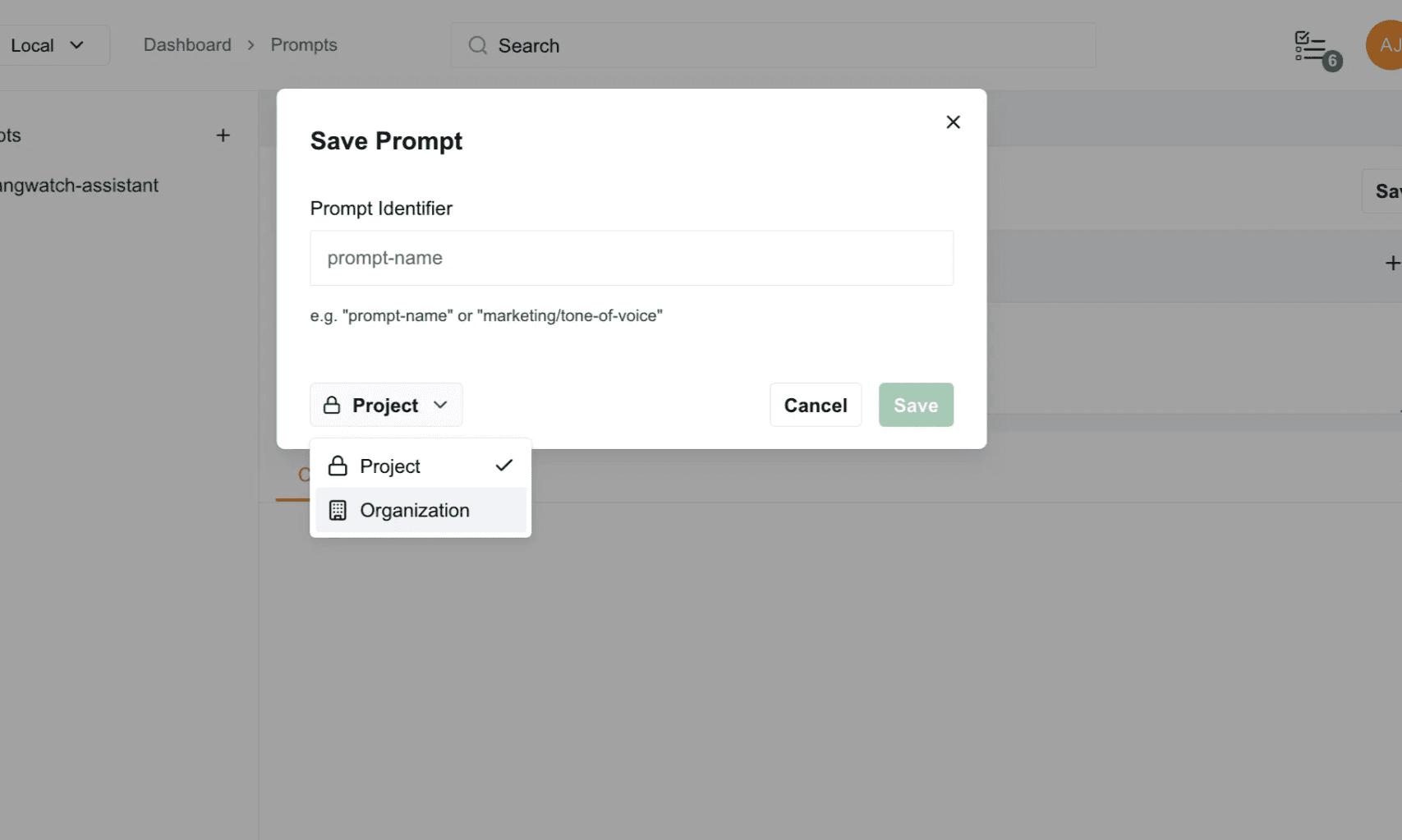
LangWatch Prompt Playground makes collaboration easy. Track prompt versions and see who made each change. Promote prompts to Organization level for shared access, while local drafts ensure teams can experiment privately without conflicts. This gives your team structure and transparency, supporting efficient, coordinated, prompt development.
3. Prompt experimentation: fast loops without chaos
Your prompt experiments are currently half science, half superstition. They should be quick to run, easy to compare, and impossible to lose.
Prompt Playground streamlines prompt experimentation. Quickly create and test different prompt variants, compare results side by side, and save the versions that work - without clutter or confusion. Every experiment is organized, tracked, and easy to revisit, so your team can iterate with speed and confidence.
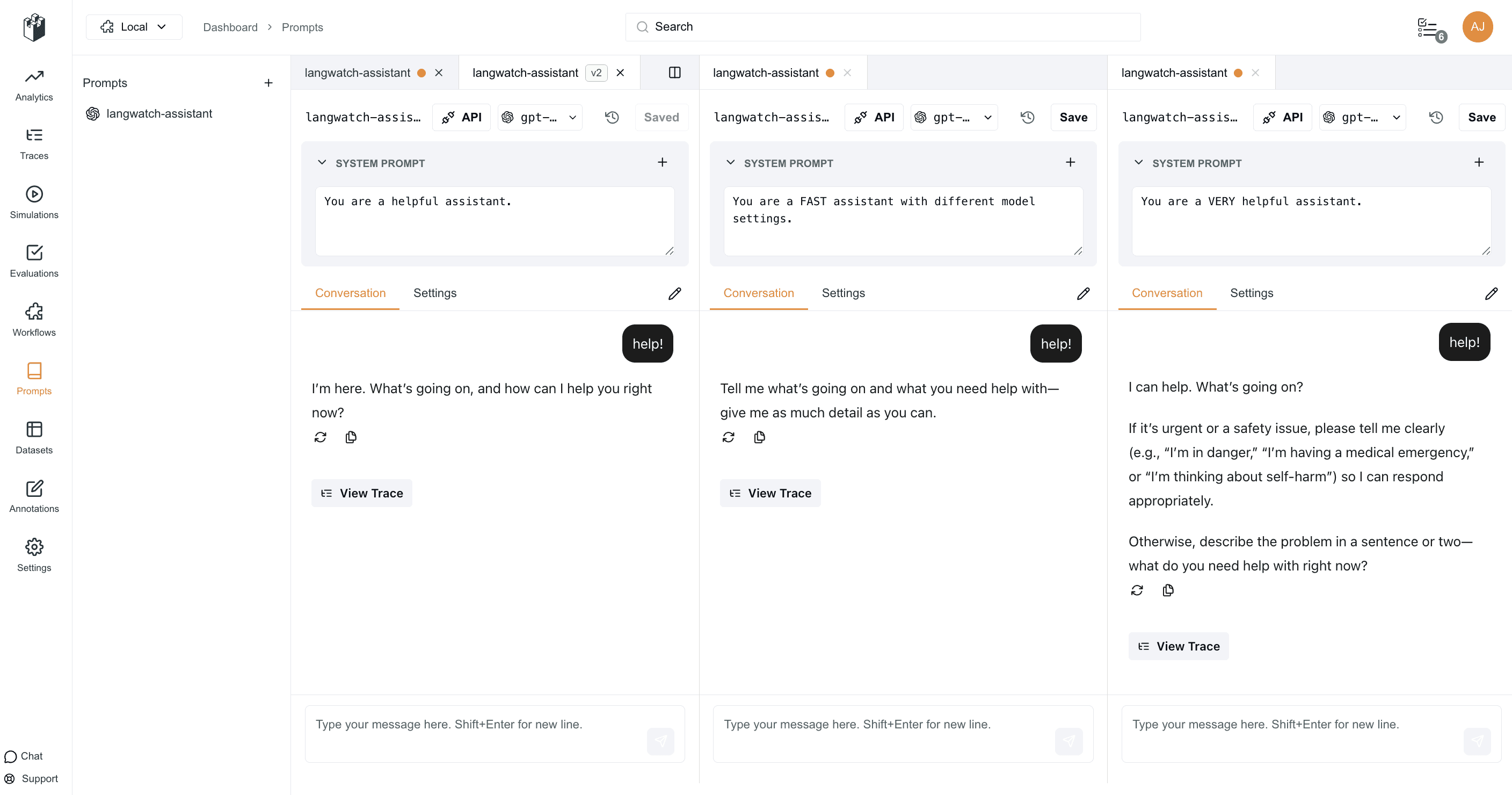
4. Versioning that isn’t a folder of screenshots
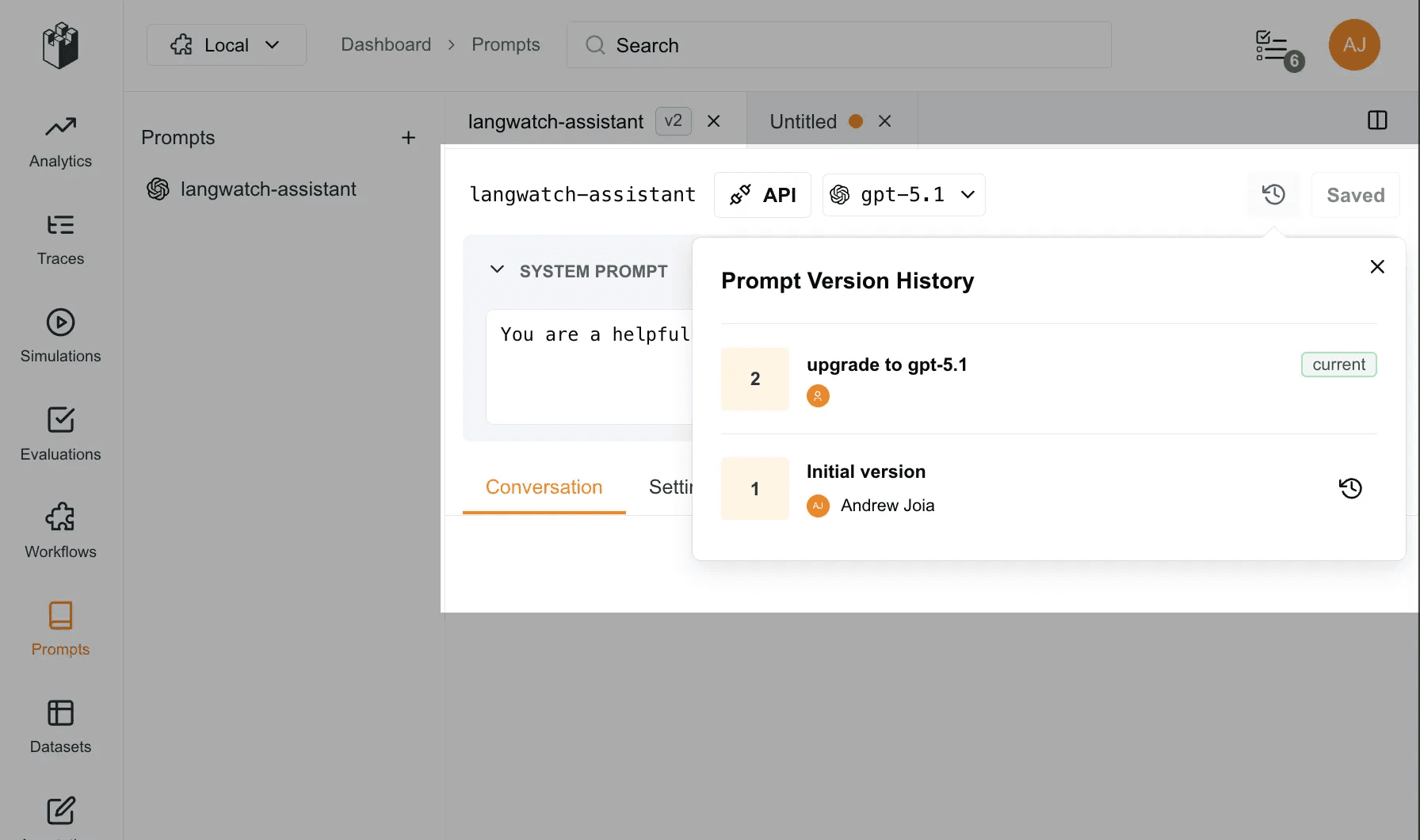
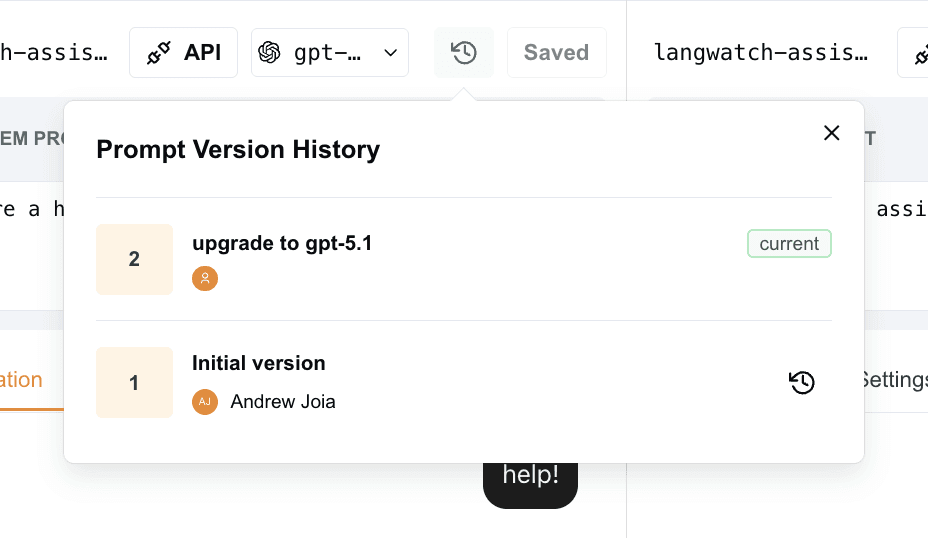
Your “snapshots” today are mostly screenshots and vague memories. They should be concrete versions you can restore, compare, and reason about.
Prompt Playground provides robust version history for every prompt. Each save creates a concrete, restorable snapshot, complete with text, parameters, and authoring. Easily compare past versions, restore previous iterations, and understand how prompts have evolved.
No more: “Does anyone know where the good version lives?”
**
5. Testing prompts against real conversations**
Your prompts are usually manually tested or tested against synthetic examples. They should be tested against the weird, messy, real conversations your users are actually having.
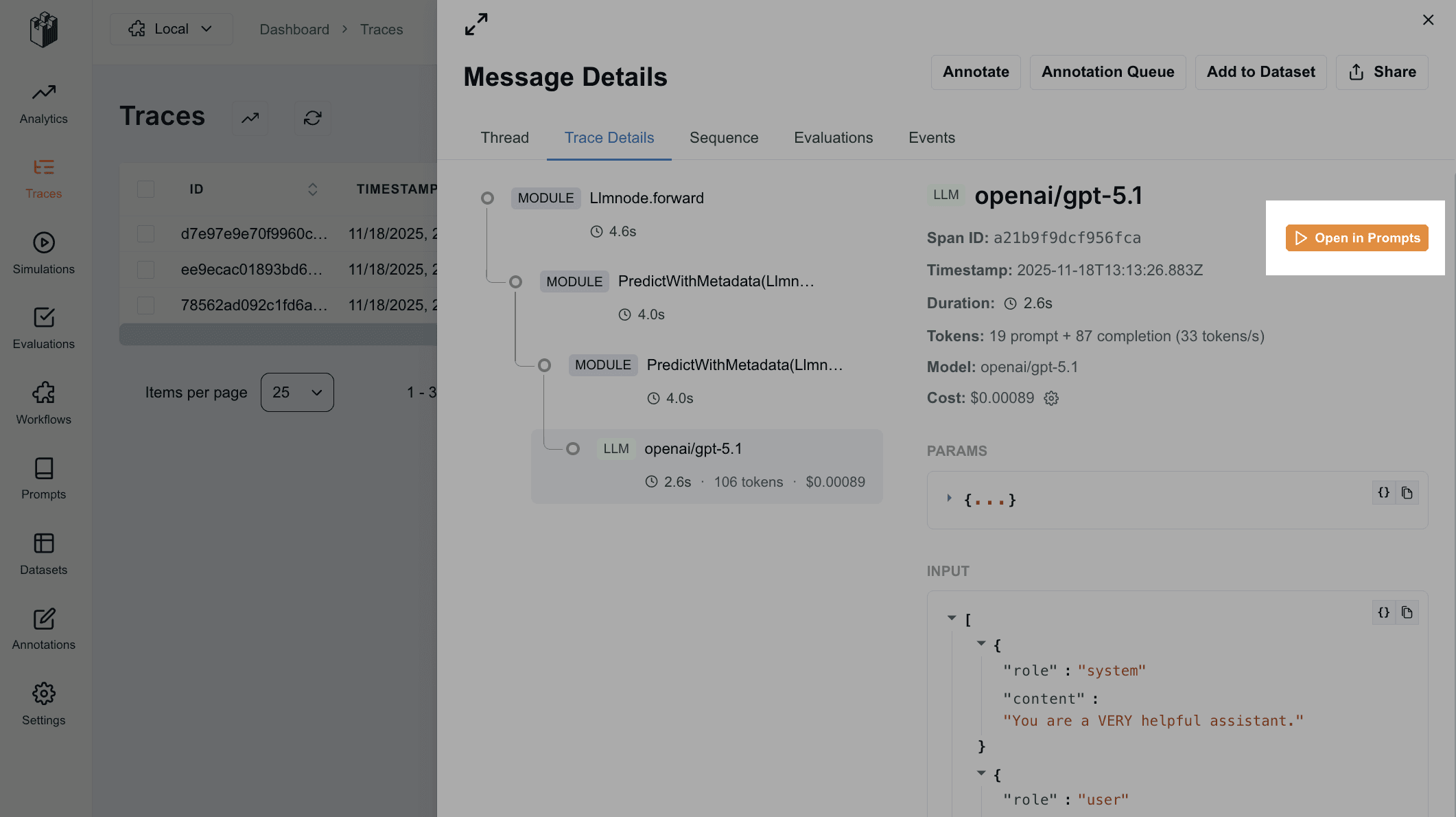
When you’ve instrumented your application with LangWatch, you can now jump straight from your LLM spans to a populated conversation in the playground to start testing against what really happened.
From there, you can replay that conversation, nudge the wording, add an example, tighten a constraint, and see on the spot whether your fix actually stops the agent from doing something insane. And when you’re happy, you don’t just ship it and hope; you turn that one bad conversation into part of a dataset or a Scenario, so the next time you change the prompt, that failure case is automatically checked for regressions.
6. Tracking performance, not just vibes
Your sense of “this prompt is better” is currently mostly vibes. It should be backed by the same kind of numbers you use for the rest of your product.
Because prompts in LangWatch are versioned and connected to analytics, you can follow a prompt the way you’d follow any other part of the system. You see how often it runs, how many tokens and dollars it burns, how that shifts when you change a line that “shouldn’t matter”, whether a supposedly minor wording tweak quietly tanked your resolution rate.
You can finally answer questions like:
-
Did this version improve resolution rate?
-
Did we reduce hallucinations?
-
Did a minor wording change double token usage?
-
Did performance quietly tank after someone added a “nice-to-have” example?
Instead of vague vibes, you get a timeline. Old version, new version, here’s what happened in the metrics. Sometimes the fancy, clever copy loses to the slightly boring one that users actually understand. Prompt Playground plus tracking lets you find that out before your users, or your support team does.
7. Evaluations: Turning opinions into signals
Your evals today are mostly “hmm, that looks okay to me.” They should be explicit checks that run on real data and tie back to specific prompt versions.
LangWatch has evals baked in. You can score outputs for faithfulness, structure, usefulness, or whatever custom rules your domain experts actually care about, and you can run those evals on live traffic or on datasets built from your traces. Crucially, you can attach them to the actual prompt versions coming out of Prompt Playground, instead of vaguely “the system.”
The versions you create there are the same ones you run through evals. You can make a change, run it against a battery of real examples, and see whether the scores moved in the direction you wanted. You don’t have to trust your gut or your last three test messages; you get a bit of statistical reality to go with your instincts.
8. Optimizing: Let the machine explore, you stay in control
Your current “optimization” process is you and a teammate arguing over wording. It should be an actual search over many candidates, guided by the metrics you care about.
This is where LangWatch’s Optimization Studio and DSPy integration come in. You can feed it your prompts and datasets and let it explore the space for better variants, using DSPy’s optimizers like MIPROv2 to tune few-shot examples and instructions against real success metrics, without hand-editing every candidate.
Prompt Playground sits on the human side of that loop. It’s where you understand failures, sketch new ideas, and hash things out with your domain experts. Optimization Studio sits on the machine side, where you say, “Okay, given this baseline, go explore more aggressively, but don’t break our scores.” Together, they give you something pretty rare in LLM land: a workflow where prompts are not just mystical incantations, but artifacts you can design, test, optimize, and still understand.
Conclusion
Once you’re in production, prompts stop being a toy; they become part of the infrastructure. They’re shared across teams, and they have to adhere to business rules. You need to be confident that they are guiding your agents to be helpful, not confusing or a literal liability.
At LangWatch, everything we build is in service of one thing: you shipping AI products and agents with actual confidence, not crossed fingers and a rollback plan taped to your monitor. Prompts sit right in the middle of that. So Prompt Playground is not “yet another place where you can chat with a model.” It lives inside prompt management, inside observability, inside evals, and optimization. It knows about traces, versions, datasets, and scenarios. It knows what happened in production five minutes ago, not just what you typed into a box right now.
That's how you go from:
“We think this prompt is better.”
to
“This prompt improved success rate by 12%, reduced tokens by 18%, and passed all regression checks - ship it.”
FAQ
**Is this different from just using the OpenAI / Anthropic playground?
**Yes. Those playgrounds are great for quick experiments, but they don’t know anything about your application. Prompt Playground is tied to your traces, prompt versions, analytics, and evals. You’re iterating on the same prompts your app actually runs, not isolated copies.
**How does this relate to Optimization Studio / DSPy?
**Prompt Playground is about manual iteration: you tweak templates, variables, and settings by hand. Optimization Studio (and DSPy) are about automated optimization: running structured experiments, tuning prompts, and parameters systematically. The Playground is where you understand and fix behavior; Optimization Studio is where you squeeze out the last 10 - 20% by running bigger, automated experiments.
**Can my team work on the same prompts together?
**Yes. Prompts live in LangWatch’s prompt management layer, not on your laptop. Your team can open the same prompt, see its history, and use the same handles in code. You can effectively treat prompts like shared infrastructure: versioned, reviewable, and visible to everyone.
**Does this replace my code editor?
**No. You’ll still define how your app wires prompts into flows, tools, and business logic in your own code. Prompt Playground is where you design and evolve the prompts themselves, then pull in the generated API snippets, or use the LangWatch SDKs and CLI to keep your code in sync.
**What about testing and evaluations?
**Prompt Playground is focused on interactive testing and comparison. For more systematic testing - datasets, evals, regression checks - you’d plug into LangWatch’s Evaluations and Scenario features. The nice part is that prompt versions created in the Playground are the same ones you can evaluate and monitor later.
**Is Prompt Playground only for chatbots?
**No. It works for any prompt-driven use case: agents, retrieval flows, email generators, internal tools… anything where you’re maintaining prompt templates and want to treat them as first-class, versioned objects.
How to get started with Prompt Playground?
If you’re already using LangWatch:
-
Open your project dashboard
-
Go to Prompt Management → Prompts (or navigate to /prompts)
-
Either create a new prompt or open one from the sidebar [!!!! gif]
-
Or jump in from a trace with “Open in Prompt Playground” [!!!! screenshot]
If you’re new to LangWatch:
-
You can explore the docs for Prompt Playground and Prompt Management to see how it fits with versions, evaluations, and analytics.
-
Or just sign up and plug in your LLM app - most teams get basic tracing and prompt management running in a few minutes.
Ship prompts with confidence, not crossed fingers.
Prompt Playground gives you one place to see how your prompts behave, fix them, and ship new versions, anchored in real production traffic instead of copy-pasted snippets.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.