Introducing the Evaluations Wizard: How to evaluate your LLM: Building an LLM evaluation framework that actually works
Learn how to effectively evaluate and test LLMs with LangWatch's new Evaluations Wizard. Improve your AI model performance
 Rogerio · April 22, 2025 · Product Releases
Rogerio · April 22, 2025 · Product Releases
LLMs are powerful - but without proper LLM evaluations, they're unpredictable.
From testing AI prompts to making significant model swaps, AI teams need a clear way to evaluate AI models and ensure optimal performance. However, today, LLM testing is often scattered across notebooks, dashboards, and scripts, making it slow, unreliable, and difficult to scale effectively.
That’s exactly why we built the LangWatch Evaluations Wizard - a unified, guided workflow for evaluating, testing, and optimizing your LLMs directly within LangWatch.
Common challenges in Evaluating LLMs
Why did we build this Evaluator Wizard? We’ve heard the same pain points from teams struggling with LLM performance testing:
-
"I don't have a dataset to evaluate yet"
-
"How can we measure the quality when there is no defined golden answer in our case?"
-
"I need a clear way to show my customer performance is improving"
-
"I want to run my full pipeline as part of the eval"
-
"I want the domain experts to drive up the expected answers dataset, and focus on the code"
-
"I have no idea how we should get started with evals, should we use LLM-as-a-judge?"
Evaluations may seem like a big investment, but in our experience even a handful of examples to start the evals discussion early on is very productive for AI teams, so lowering the barrier is key.
LLM evaluations shouldn't be an afterthought; they need to be fast, intuitive, and continuous. The Evaluations Wizard brings that vision into reality.
How the Evaluations Wizard simplifies LLM testing
The LangWatch Evaluations Wizard is your new centralized hub for LLM QA. It replaces our old real-time and experiments views and give you tools to quickly get from zero to evals, for all evaluation needs, with one seamless, step-by-step interface.
Here's how you can evaluate your AI models efficiently:
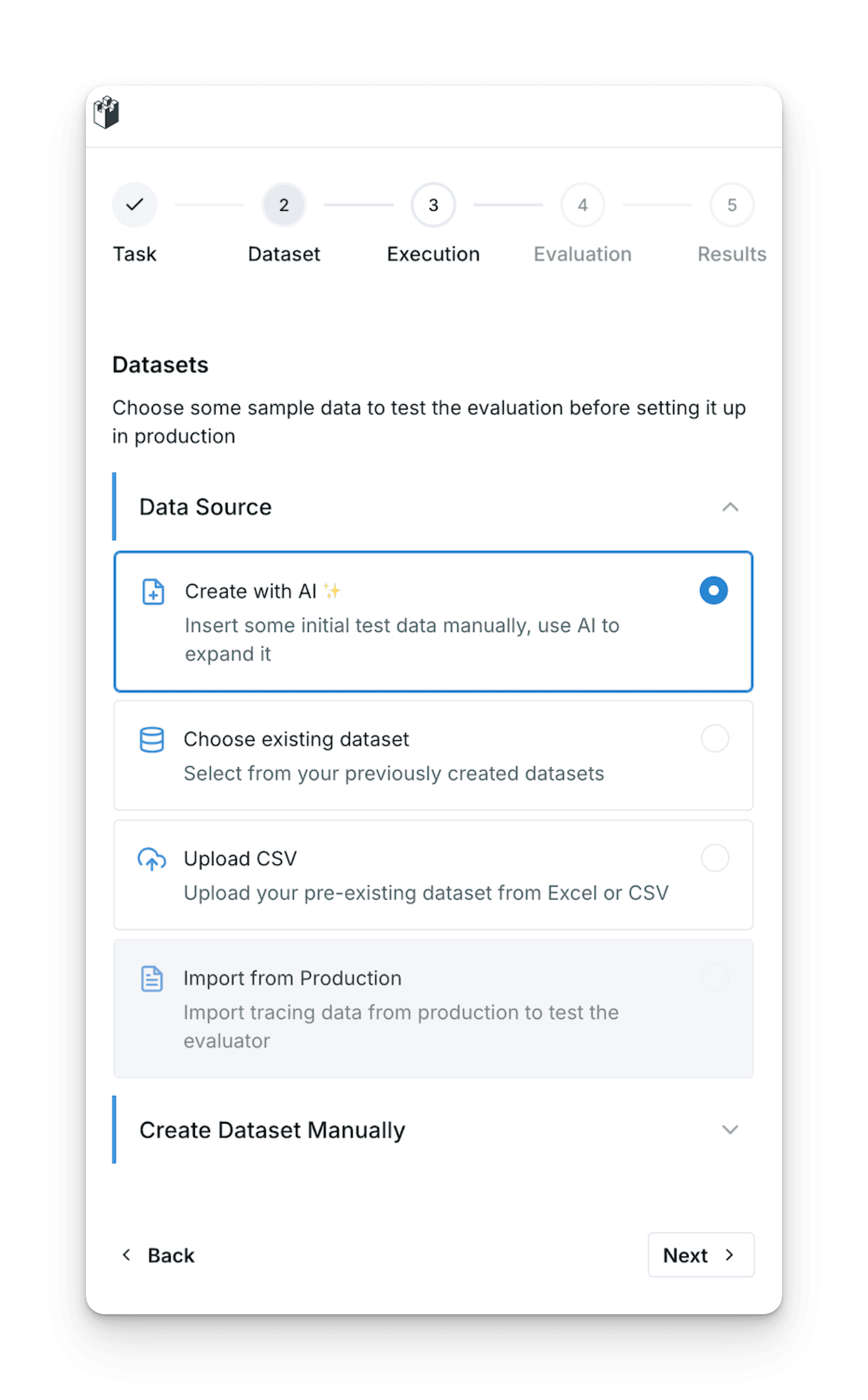
Create test datasets your way
-
Upload a CSV or paste examples directly
-
Use our AI Copilot to generate synthetic examples from your documentation
-
Manually create test cases with custom metadata
Evaluate complete LLM Pipelines
-
Connect directly to any deployed model or HTTP endpoint
-
Chain multiple LLM calls together to simulate realistic, multi-step workflows
-
Leverage real or synthetic test data
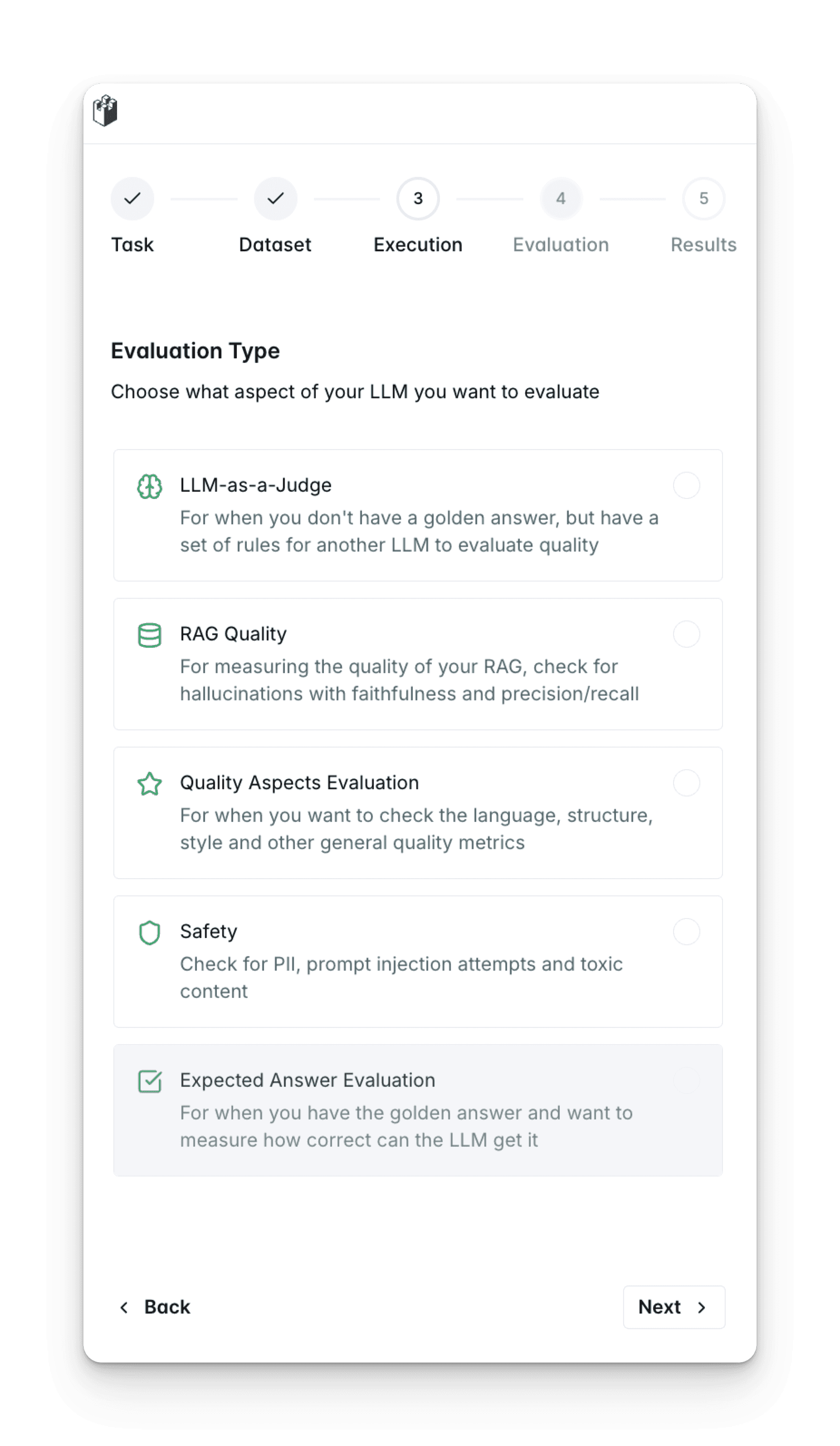
Select your ideal evaluators
-
Choose from 30+ built-in evaluators (accuracy, relevance, toxicity, and more)
-
Leverage LLM-as-a-judge for building custom evaluators
-
Engage human-in-the-loop annotations for subjective assessments and safety-critical cases
Integrate with your workflow
-
Run batch tests directly from the UI or with the CLI using our SDK
-
Integrate LangWatch seamlessly into your applications or CI/CD pipelines using our Python and TypeScript SDKs
-
Run all the evaluations in parallel and get results in minutes, including cost and latency
Practical examples of how to evaluate your LLM
Teams are already leveraging the Evaluations Wizard for impactful use cases:
-
Validating Model Upgrades: Run side-by-side comparisons between model or prompt versions on realistic test sets, assessing precisely where new models improve (or regress) performance before deploying.
-
Detecting Data Drift: Re-evaluate using nightly CI/CD jobs on top of the knowledge base that may change every day for detecting data drifts that causes the RAG application to degrade in answer correctness.
-
Optimizing Prompts with Real Data: Create targeted edge-case queries from actual help center or customer support ticket history, then utilize DSPy optimizations to objectively find the best-performing prompt variants.
-
Human + AI Evaluation Loop: Route flagged outputs automatically to domain experts, gather structured feedback, and retrain your evaluation datasets workflow.
Start your LLM Evaluations today
Whether you're building complex LLM pipelines, refining prompts, or conducting essential safety checks before launch, the LangWatch Evaluations Wizard empowers you to move faster and smarter.
Launch the Evaluations Wizard today, or dive deeper into how to evaluate your LLM effectively.
✨ Launch the Evaluations Wizard
📘 Learn more about LLM testing in our docs
💬 Join our community on Discord to talk about what LLM Evals worked for you
We’re excited to see the robust LLM QA processes you build - and how you use them to push the boundaries of AI.
Let's integrate effective LLM evaluations directly into the AI development loop.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.