The complete guide for TDD with LLMs
How can we test in a probabilistic environment? Test Driven Development for LLM's
 Rogerio - CTO · July 3, 2024 · Agents
Rogerio - CTO · July 3, 2024 · AgentsTest Driven Development in simple terms means writing the tests before writing the code, but anyone who has practiced it for real knows that it goes much beyond. This simple, unintuitive twist causes a profound shift in your mindset.
Having the test before the implementation makes you think much more about what is actually expected, with the how coming later, and the how is an implementation detail, which can be changed through refactoring.
LLMs excel at doing what you ask them to do… but also kinda don't. You can write a prompt and just ask what is expected, but it's not always that LLMs do what you want, partially because it doesn't always follow the prompt correctly. A working prompt can easily break when changed, but in other part because sometimes you actually don't know every detail on how you want it to behave, you only notice when the output is somewhat off, for some use cases, and language is just so open it's hard to define everything.
This way, TDD matches both pretty well and pretty badly on what is needed to build better LLM applications.
Pretty well on philosophy, if instead of doing the prompt directly you'd first write down what you expect from the output, then the prompt could be guided by the already defined spec, and you could change the prompt or the model later, while making sure everything still works as expected.
Pretty badly though, because generally TDD matches better with unit tests, but LLMs are not a good fit for unit tests, their unpredictable nature means they can fail probabilistically, and many examples are needed to ensure it mostly passes.
But is there a way forward anyway? Well, there is!
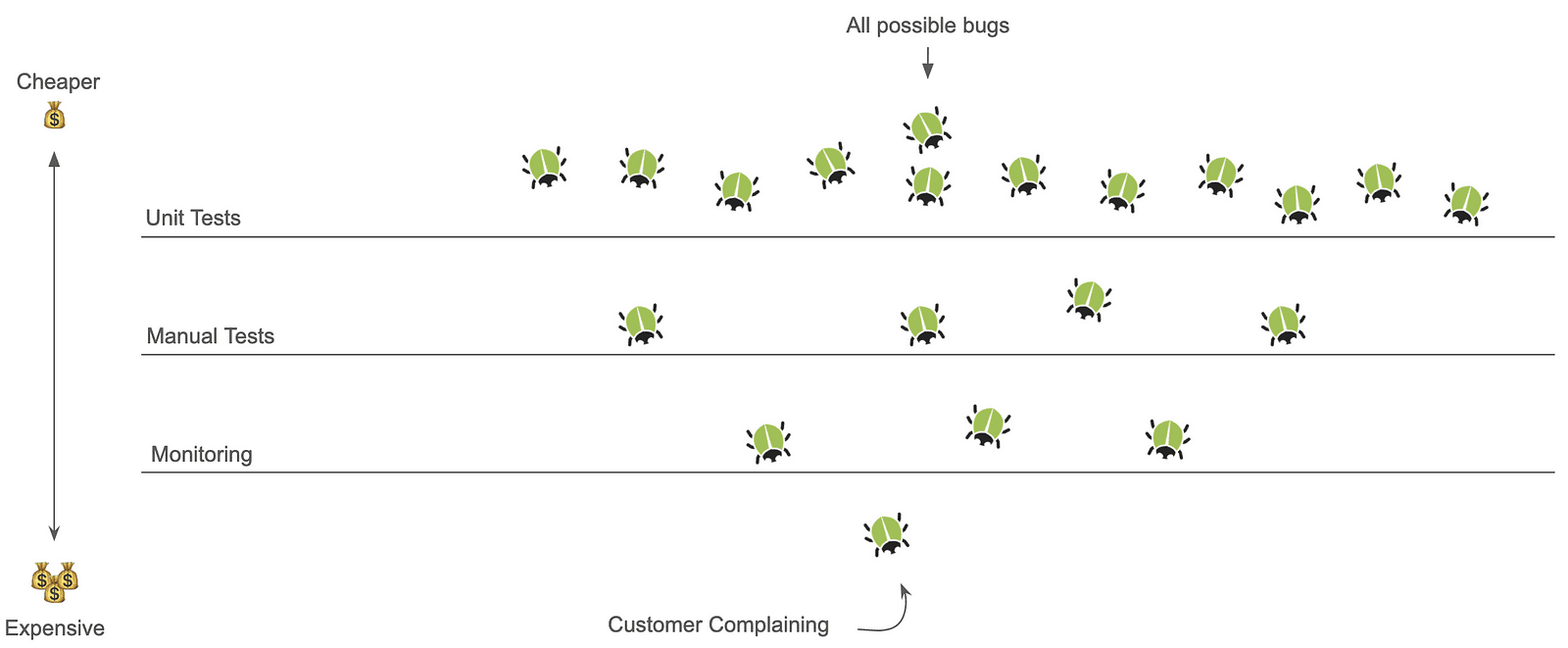
Image caption: our goal is to “shift-left”, the earlier you find issues, the cheaper it is, cheaper in time spent manually testing, cheaper in time spent fixing due to faster cycles, and cheaper literally as less issues hit production
Doing TDD for LLMs with pytest
Alright, no more yapping, let's start with a very simple test case. We are building a bot that will generate and tweet out recipes, as a tweet, it should be short, so our first test is simple enough:
import pytest
from app import recipe_bot
@pytest.mark.asyncio
async def test_fits_a_tweet(entry, model):
recipe = await recipe_bot.generate_tweet(
input="Generate me a recipe for a quick breakfast with bacon",
model="gpt-3.5-turbo"
)
assert len(recipe) <= 140
We use pytest to run and execute the tests plus pytest-asyncio to run tests asynchronously, this will be important later.
Our test is simple enough, good old assertion of just checking the length of the output. Now, as per TDD rule, we run the test (without the implementation), we see it fail (if it passes now something is wrong!) and then we proceed to implementation:
import litellm
from litellm import ModelResponse
async def generate_tweet(input: str, model: str = "gpt-3.5-turbo") -> str:
response: ModelResponse = await litellm.acompletion(
model=model,
messages=[
{
"role": "system",
"content": "You are a recipe tweet generator, generate recipes using a max of 140 characters.",
},
{"role": "user", "content": input},
],
temperature=0.0,
) # type: ignore
return response.choices[0].message.content # type: ignore
We use litellm, a drop-in replacement for OpenAI which allows us to use many different LLMs by just switching the model argument. The prompt is simple, straightforward, should work.
Then we run the test again aaand it passe… fails?
> pytest
============================================================================ FAILURES =============================================================================
________________________________________________________________________ test_fits_a_tweet ________________________________________________________________________
@pytest.mark.asyncio
async def test_fits_a_tweet():
recipe = await recipe_bot.generate_tweet(
input="Generate me a recipe for a quick breakfast with bacon",
model="gpt-3.5-turbo",
)
> assert len(recipe) <= 140
E AssertionError: assert 144 <= 140
E + where 144 = len('Crispy Bacon Breakfast Tacos: Cook bacon until crispy, scramble eggs, fill tortillas with eggs, bacon, cheese, and salsa. Enjoy! #breakfasttacos')
Turns out, LLMs are terrible at counting, so even though you asked very explicitly on the prompt, it still goes a bit over 140 characters. Well, since now you have an automated way of validating, it becomes easier to try it out different prompts and see if it works:
- "content": "You are a recipe tweet generator, generate recipes using a max of 140 characters.",
+ "content": "You are a recipe tweet generator, generate recipes using a max of 140 characters, just the ingredients, no yapping.",
It does work!
> pytest
tests/test_recipe_bot.py . [100%]
======================================================================== 1 passed in 1.77s ========================================================================
Awesome, the power of no yapping. Cool, this means it will always work right? For any model and input right? No?
Problem #1: Unpredictable inputs
Users can send any input they want, but our prompt not necessarily will work perfectly for all the cases. Having a working example gives us a bit of confidence, but you know what would be even better? Way more examples. In a probabilistic environment, that’s the best way to get more confidence.
Luckily, we can use pytest’s parametrize for that:
import pandas as pd
entries = pd.DataFrame(
{
"input": [
"Generate me a recipe for a quick breakfast with bacon",
"Generate me a recipe for a lunch using lentils",
"Generate me a recipe for a vegetarian dessert",
"Generate me a super complicated recipe for a dinner with a lot of ingredients",
],
}
)
@pytest.mark.asyncio
@pytest.mark.parametrize("entry", entries.itertuples())
async def test_fits_a_tweet(entry):
recipe = await recipe_bot.generate_tweet(
input=entry.input,
model="gpt-3.5-turbo",
)
assert len(recipe) <= 140
Now we have not only one example, but four, and notice that on the last one, the user is trying to be a smartass and jailbreaking a bit, let’s see if our bot is resilient to that!
> pytest
tests/test_recipe_bot.py . [100%]
======================================================================== 4 passed in 7.10s ========================================================================
Yes, it is! Nice, this gives us more confidence. Notice it says 4 passed, by using parametrize with the inputs examples, one test became four already.
Those are things you would probably try by hand as well to break your own bot, however, it’s exhausting doing it every time you change the prompt, it is super convenient to have it automated, so you can tune your prompts worry-free.
But wait, what if you just run again? Actually, sometimes it fails!
============================================================================ FAILURES =============================================================================
FAILED tests/test_recipe_bot.py::test_fits_a_tweet[entry3-gpt-3.5-turbo] - AssertionError: assert 141 <= 140
============================================================= 1 failed, 3 passed, 1 warning in 7.12s ==============================================================
Almost! By one extra character! But how come? The tests just passed on the previous run, my temperature is 0.0, they should always pass every time right? No?
Problem #2: Flakiness
This is a big one for LLMs, flakiness is way more inherent for LLMs than in traditional software, even when temperature is zero. Luckily, there is yet another library can than help us here, and the name is kinda obvious too, flaky! Flaky allows us to mark a test to be retried a number of times, until it works:
@pytest.mark.asyncio
+ @pytest.mark.flaky(max_runs=3)
@pytest.mark.parametrize("entry", entries.itertuples())
async def test_fits_a_tweet(entry):
recipe = await recipe_bot.generate_tweet(
input=entry.input,
model="gpt-3.5-turbo",
)
assert len(recipe) <= 140
With this change, we allow each LLM to retry 3 times before the verdict, effectively doing 3-shot attempts at the problem, and now, let’s see how it goes:
> pytest
tests/test_recipe_bot.py .... [100%]
================================================================== 4 passed, 1 warning in 6.80s ===================================================================
Nice! Everything passes! It means that with a couple more attempt, our bot can successfully keep under 140 characters.
But what are we really saying here? Sometimes it will fail and sometimes it will work (at least 33% of the time), but likely in production, you won’t retry many times, and you won’t even know if what you generated is wrong or not (unless you implement the same test at runtime, like a guardrail) so you can retry, so our test is not giving us that much confidence this way (only 33%).
Expecting 100% also doesn’t work though, LLMs are inherently flaky, but how about instead of just defining an upper bound, we define a lower one as well? I want to be able to say that, in production, I expect this to work at least 67% of the time. We can do that by using the min_passes argument:
@pytest.mark.asyncio
- @pytest.mark.flaky(max_runs=3)
+ @pytest.mark.flaky(max_runs=3, min_passes=2)
@pytest.mark.parametrize("entry", entries.itertuples())
async def test_fits_a_tweet(entry):
recipe = await recipe_bot.generate_tweet(
input=entry.input,
model="gpt-3.5-turbo",
)
assert len(recipe) <= 140
Presto! Now you are saying it can try 3 times, but it should pass at least in 2 of them, ~67% of the time.
But does this mean your unit tests are saying now that it’s okay for things to fail sometimes? That might make a lot of people uncomfortable, however we are on a probabilistic world remember, having it defined, on your specifications, the pass rate of your executions is already way better than where we started off, completely in the dark, now at least it’s just a matter of increasing those numbers, as you iterate and improve your solution.
Now, what if we try a different model then? A smarter one like gpt-4o ? If it works on gpt-3.5-turbo then it should be a breeze, right? What about an open-source model like llama3? After all the prompts are portable right? No?
Problem #3: Prompt portability
This is a problem for LLMs that unit tests can actually help solving, when you switch models or merely upgrade them, your prompts may stop working. Since we have parametrize and litellm, we can in fact easily run our test examples against different models and see how they behave:
from itertools import product
models = ["gpt-3.5-turbo", "gpt-4o", "groq/llama3-70b-8192"]
@pytest.mark.asyncio
@pytest.mark.flaky(max_runs=3, min_passes=2)
@pytest.mark.parametrize("entry, model", product(entries.itertuples(), models))
async def test_fits_a_tweet(entry, model):
recipe = await recipe_bot.generate_tweet(
input=entry.input,
model=model,
)
assert len(recipe) <= 140
This way we pair up each input entry with each model we want to test against, let’s see the results:
> pytest
tests/test_recipe_bot.py ........F.FF [100%]
============================================================================ FAILURES =============================================================================
FAILED tests/test_recipe_bot.py::test_fits_a_tweet[entry8-groq/llama3-70b-8192] - assert 151 <= 140
FAILED tests/test_recipe_bot.py::test_fits_a_tweet[entry10-gpt-4o] - AssertionError: assert 148 <= 140
FAILED tests/test_recipe_bot.py::test_fits_a_tweet[entry11-groq/llama3-70b-8192] - assert 320 <= 140
============================================================= 3 failed, 9 passed, 1 warning in 45.21s =============================================================
You can see that actually GPT-4 and Llama3 fail this test, with both failing on the last smart-ass user example. But before we get into that, have you noticed something else? 45 seconds! Our tests took 45 seconds to run, and this is just our first test, how long will it take this suite when the project grows? That’s not good.
Problem #4: LLMs are slow
Even though groq is crazy fast, it’s still orders of magnitude slower than ordinary code we unit test, but actually, in our case, those LLMs are not running on our machine but through an API, so the problem here really is that they are being called sequentially, instead of in parallel.
Luckily, we can use pytest-asyncio-cooperative (use my branch if having issues with retries later), this library allows pytest tests to run all at the same time:
- @pytest.mark.asyncio
+ @pytest.mark.asyncio_cooperative
@pytest.mark.parametrize("entry, model", product(entries.itertuples(), models))
async def test_fits_a_tweet(entry, model):
recipe = await recipe_bot.generate_tweet(
input=entry.input,
model=model,
)
assert len(recipe) <= 140
Now let’s run again:
> pytest
============================================================================ FAILURES =============================================================================
FAILED tests/test_recipe_bot.py::test_fits_a_tweet[entry9-gpt-3.5-turbo] - AssertionError: assert 141 <= 140
FAILED tests/test_recipe_bot.py::test_fits_a_tweet[entry11-groq/llama3-70b-8192] - assert 308 <= 140
FAILED tests/test_recipe_bot.py::test_fits_a_tweet[entry10-gpt-4o] - AssertionError: assert 148 <= 140
============================================================= 4 failed, 8 passed, 1 warning in 27.88s ==============================================================
Tests still fail of course, but now it takes 27s, way shorter time, but still a lot due to the retries that end up happening sequentially. If we remove the retries it all runs in 2s, try it out! A fast feedback loop is really important for you to keep tweaking and iterating comfortably, otherwise you will just get annoyed and throw the tests out of the window.
Nice, now that we have bit more speed, let’s go back to the previous problem then, we could try to adjust the prompt to make it work well for all three, but perhaps you don’t actually need it to work on every single prompt, even with retries, again on define boundaries, if you have a big dataset, inevitably some models or some prompts will have a trade-off and being better to answer some inputs well, but others not so much.
Problem #5: Pass Rate
Just like we did retries for every single item and established a minimum pass rate there, there are some items that your LLM won’t be able to get right no matter how many times you try, however, it doesn’t mean it’s worthless, getting the examples on your dataset right 80% of the time is still better than getting it right 50% of the time, and again, you then get explicit on your limitations rather than in the dark, and can only improve from there.
In our case for example, maybe it’s okay that GPT-4 or Llama3 fails in one of the tasks after trying 3 times, we still consider it good enough. So we need then a pass rate across the board, a global pass rate. For that, we are going to use the library langevals, which is all about providing evaluations for LLMs, but it also provides this nice pass_rate pytest annotation:
entries = pd.DataFrame(
{
"input": [
"Generate me a recipe for a quick breakfast with bacon",
"Generate me a recipe for a lunch using lentils",
"Generate me a recipe for a vegetarian dessert",
- "Generate me a super complicated recipe for a dinner with a lot of ingredients",
],
}
)
@pytest.mark.asyncio_cooperative
@pytest.mark.flaky(max_runs=3, min_passes=2)
+ @pytest.mark.pass_rate(0.8)
@pytest.mark.parametrize("entry, model", product(entries.itertuples(), models))
async def test_fits_a_tweet(entry, model):
recipe = await recipe_bot.generate_tweet(
input=entry.input,
model=model,
)
assert len(recipe) <= 140
With this parameter, now we are saying that the minimum passes we expect is 80%, we are okay with 20% of failed inputs, as long as most of them (80%) are indeed less than 140 characters. I’ve also removed the last tricky example, it was indeed throwing the other models completely off, we can add it back later after improving our prompt.
> pytest
======================================================================= test session starts =======================================================================
x.xx......
============================================================ 8 passed, 3 xfailed, 1 warning in 20.42s =============================================================
Nice! Now our test suite passes, even though not all tests passed completely, notice the 3 xfailed ones, those failed, but were “forgiven”, either because they were retried and worked, or because they are within the pass rate margin.
We have now all the tools we need to write tests for LLMs, and making our uncertainty rates clear. But TDD is about creating writing more tests, so you can add more features to your application, so let’s finally jump into it.
TDD for adding more features
Having 140 characters is nice and well, but that is a too simple of a test to be honest, and it would be easy enough to just cut the string short to fit in there. The more interesting use cases for LLMs is not something like that, the more interesting cases for LLMs is actually being able to do things that code itself cannot do, that cannot be expressed with logic, those are also the most interesting features for your solution to have.
For example, let’s make our bot output only vegeratian recipes, we want to go green and save the planet! This is something that cannot be expressed with basic programming logic, but LLMs are perfect for. However, how do we evaluate this? There is no pytest assertion for that! Turns out those interesting features, are also the most interesting ones to be evaluated.
Problem #6: Evaluations
Enter LangEvals! LangEvals is a library that aggregates various LLM-focused evaluators, exactly for the purpose of evaluating and validating LLMs,.
Validating if our recipe is really vegetarian is really hard to do with traditional code, but it does seems like something an LLM would be good to. LangEvals does not have a “vegetarian evaluator” out-of-the-box, however it does have a CustomLLMBooleanEvaluator, which allows us to easily build a LLM-as-a-judge evaluator, which behinds the scene uses function calling to always return true or false for whatever you want to evaluate.
So let’s write our test with it (before the implementation of course) together with the expect utility:
from langevals import expect
from langevals_langevals.llm_boolean import (
CustomLLMBooleanEvaluator,
CustomLLMBooleanSettings,
)
@pytest.mark.asyncio_cooperative
@pytest.mark.parametrize("entry, model", product(entries.itertuples(), models))
async def test_llm_as_judge(entry, model):
recipe = await recipe_bot.generate_tweet(input=entry.input, model=model)
vegetarian_checker = CustomLLMBooleanEvaluator(
settings=CustomLLMBooleanSettings(
prompt="Look at the output recipe. Is the recipe vegetarian?",
)
)
expect(input=entry.input, output=recipe).to_pass(vegetarian_checker)
Since we are TDDing, let’s run this test to make sure it is failing and we actually need to implement anything (maybe it’s vegetarian by default, so we would have nothing to do!). Let’s check:
> pytest
tests/test_recipe_bot.py F..F.F.F.
============================================================================ FAILURES =============================================================================
FAILED tests/test_recipe_bot.py::test_llm_as_judge[entry2-groq/llama3-70b-8192] - AssertionError: Custom LLM Boolean Evaluator to_pass FAILED - The recipe is not vegetarian because it contains bacon.
FAILED tests/test_recipe_bot.py::test_llm_as_judge[entry1-gpt-4o] - AssertionError: Custom LLM Boolean Evaluator to_pass FAILED - The recipe is not vegetarian because it contains bacon.
FAILED tests/test_recipe_bot.py::test_llm_as_judge[entry0-gpt-3.5-turbo] - AssertionError: Custom LLM Boolean Evaluator to_pass FAILED - The recipe is not vegetarian because it contains bacon.
============================================================= 3 failed, 6 passed, 1 warning in 6.99s ==============================================================
The test failed for the first entry on all models. Of course, because the first input asked for a “quick breakfast with bacon”, so it’s not vegetarian. The LLM Boolean evaluator caught that, and nicely tells us why it decided it fails right there on the error message, and it is because the output recipe contains bacon, which is not vegetarian.
Now you might be thinking, isn’t it weird that an LLM is grading it’s own homework? Won’t it just agree with itself most of the time? Well, not necessarily, first of all because you can use a different, smarter model to evaluate the one you will actually use in production at scale, for example GPT-4 evaluating GPT-3.5 results, but also, because this prompt here is way more focus, it does one thing and one thing well only, it won’t break because you are not updating it and doing many things at once like your main bot’s prompt.
This is one of the very important reasons for us to run our tests before write the code, so we “test our test”. By the reasoning on the outputs, it seems to be working perfectly well, so now we can trust it will evaluate our actual implementation code. Let’s go ahead and update our prompt then:
async def generate_tweet(input: str, model: str = "gpt-3.5-turbo") -> str:
response: ModelResponse = await litellm.acompletion(
model=model,
messages=[
{
"role": "system",
- "content": "You are a recipe tweet generator, generate recipes using a max of 140 characters, just the ingredients, no yapping.",
+ "content": "You are a recipe tweet generator, generate recipes using a max of 140 characters, just the ingredients, no yapping. Also, the recipe must be vegetarian.",
},
{"role": "user", "content": input},
],
temperature=0.0,
) # type: ignore
return response.choices[0].message.content # type: ignore
Small addition of “Also, the recipe must be vegetarian.”, let’s see how it behaves:
tests/test_recipe_bot.py .........
================================================================== 9 passed, 1 warning in 9.19s ===================================================================
Nice! It all works! And since you wrote the tests before, you don’t need to add any new tests now, you are done, commit, push, and boom, you have a new feature in production, and can change your prompt with peace of mind that this very important concept on your product of having the recipes to be vegetarian will continue working.
For the next feature, you can just think of what you expect the model to output first, verify it, and then implement, this will help you ensure you always move only forward, and don’t break features that were previously working, even in this highly unpredictable environment.
Wrapping Up
I hope this guide gave you a good idea on what is it like to TDD with LLMs, all the challenged on writing tests for it, and ways how to handle each.
The field of LLM evaluations is still a very new one and in fast expansion, every day people are exploring new ideas and finding more and more ways that we can control those very powerful but unpredictable creatures.
Check out LangEvals Documentation for all the available evaluators, contributions for new ones are also very welcome!
Also, if you like this guide, please give LangEvals a star on github, and for all those bugs that cannot be captured by unit tests, check out LangWatch, our LLM Ops monitoring platform, powered by LangEvals.
Good testing!
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.