Testing Voice Agents with LangWatch Scenario in Real Time
Learn how to test real-time voice agents with LangWatch Scenario. Automate speech-to-speech testing, simulate user conversations, validate latency and performance, and run voice agent evaluations in CI - no microphones or manual testing required.
 Andrew Joia · November 24, 2025 · Voice AI
Andrew Joia · November 24, 2025 · Voice AI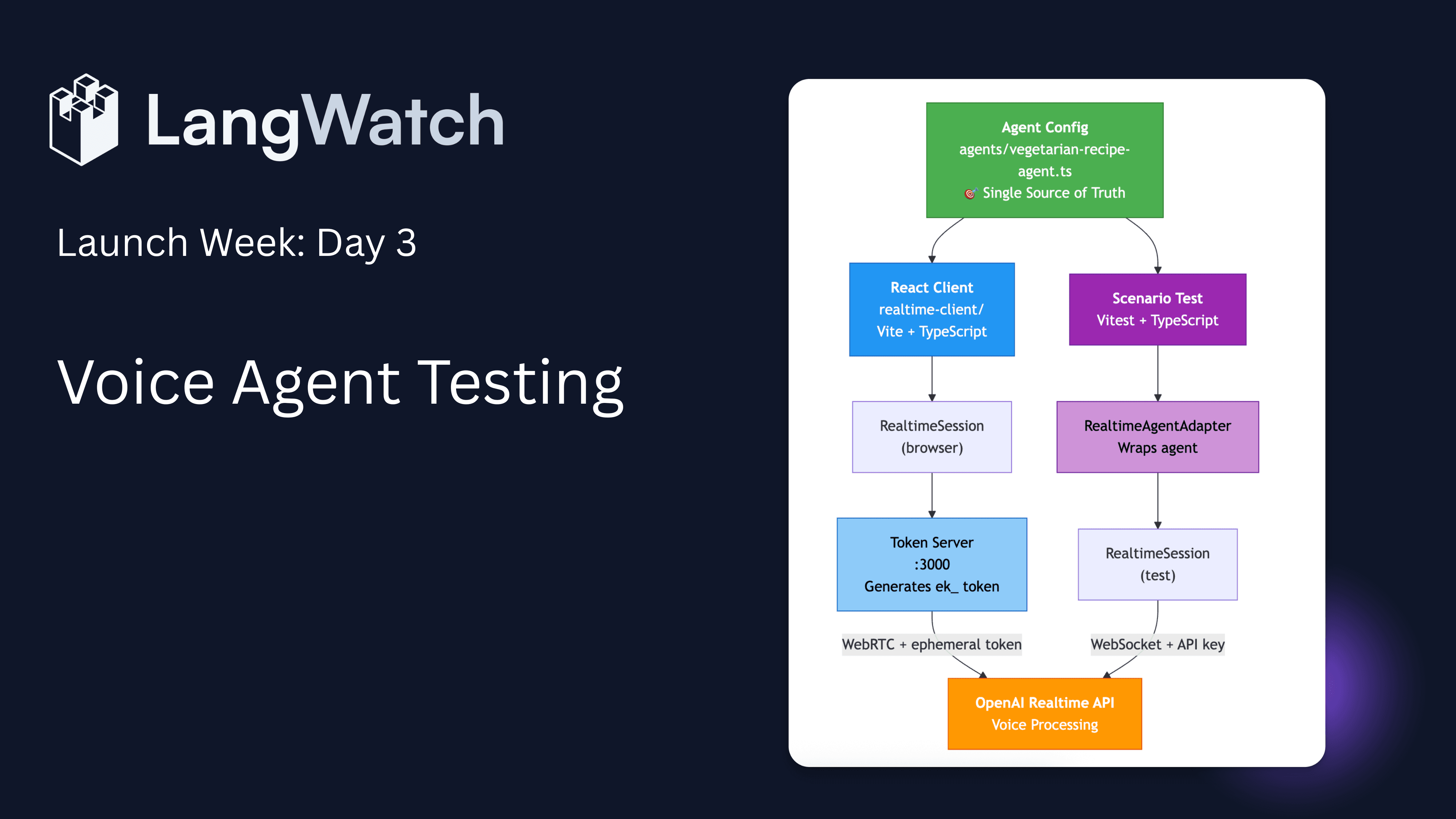
Introduction
In this post, we’ll look at how to test real-time voice agents using LangWatch Scenario.
By “voice agents,” I mean AI assistants that listen to users, process what they say, and respond with speech. If you’re already working with OpenAI’s Realtime API or similar tools, the basic idea is familiar. What’s still surprisingly hard is testing these agents end-to-end in a way that’s repeatable and trustworthy, instead of relying on one-off demos or manual checks.
Most teams start with someone talking into a microphone, watching what happens, and adjusting prompts or settings by feel. That’s perfectly fine for early prototypes. Once you’re in production, though, you want something closer to a testing workflow: scenarios you can rerun, clear expectations for what “good” behavior looks like, and the ability to catch regressions before your users do.
The goal here is simple: turn those real-time voice flows into something you can test, automate, and rely on.
TL;DR
-
You can build low-latency voice agents using OpenAI’s Realtime API in the browser.
-
LangWatch Scenario lets you run automated voice-to-voice tests against those agents.
-
A simulated “user” talks to your real-time agent, and a judge evaluates the conversation.
-
All of this can run headless in CI - no microphones, speakers, or manual testing required.
What are Voice Agents?
In this context, a voice agent is a real-time assistant built on OpenAI’s Realtime speech-to-speech capabilities. The browser captures microphone input and streams audio to the Realtime API. The model processes the conversation and streams audio back to the browser. The user hears the responses as speech, rather than reading them as text.
Because everything is streaming, conversations feel more like a call than a request - response cycle. Latency matters, turn-taking matters, and recovery from partial speech or interruptions matters. LangWatch ties into this stack by giving you a way to observe and test these voice flows as they really happen, instead of treating them as a black box.
Live Browser Example
Live browser voice agent example
To make this concrete, we provide a live example of a voice agent running in the browser using the OpenAI Realtime API and Agents SDK.
In that example, the agent listens to user speech through the microphone, streams the audio to the Realtime API, and responds verbally, streaming audio back to the user in real time. From a user’s perspective, it feels like a straightforward conversation: they speak, the assistant replies, and the interaction continues naturally.
From a developer’s perspective, the interesting question is how to test this. You probably don’t want to rely on someone repeatedly speaking the same sentence into their laptop every time you tweak a prompt or change a setting. Ideally, you’d have a way to spin up the same real-time session, simulate a user, and check whether the conversation still behaves the way you expect.
That is exactly where LangWatch Scenario comes in.
Testing with LangWatch Scenario
LangWatch Scenario is a framework for testing agents through simulations. Instead of treating each test as a new manual experiment, you define scenarios that describe how a conversation should unfold and what you expect from the agent.
For real-time voice agents, Scenario gives you a simulated user, a wrapper around your real-time agent, and a way to script entire conversations. The RealtimeUserSimulatorAgent plays the role of the user, talking to your agent using the same Realtime primitives as a browser client would. The RealtimeAgentAdapter wraps your real-time voice agent session so Scenario can send and receive turns from it as if it were any other agent. On top of that, you can include a judge agent that evaluates the interaction against criteria you care about - things like responsiveness, relevance, or adherence to constraints.
All of this can run headlessly. Audio input and output are handled programmatically, so your CI pipeline can run a full voice-to-voice test without microphones, speakers, or special hardware. You end up with an end-to-end test harness: simulated audio in, Realtime API in the middle, your agent logic on top, and audio out - under test.
Example Test Scenario
Here’s what a simple automated test can look like:
import { createVegetarianRecipeSession } from './agents/vegetarian-recipe-agent';
import { RealtimeAgentAdapter, AgentRole, scenario } from '@langwatch/scenario';
import { RealtimeUserSimulatorAgent } from './realtime/agents/realtime-user-simulator.agent';
describe("Vegetarian Recipe Agent (Realtime API)", () => {
let realtimeAdapter: RealtimeAgentAdapter;
let audioUserSim: RealtimeUserSimulatorAgent;
beforeAll(async () => {
// Create and connect the session - same pattern as the browser client
const session = createVegetarianRecipeSession();
// Wrap connected session in adapter for Scenario testing
realtimeAdapter = new RealtimeAgentAdapter({
role: AgentRole.AGENT,
session,
agentName: "Vegetarian Recipe Assistant",
responseTimeout: 30000,
});
// Create user simulator (creates its own session internally)
audioUserSim = new RealtimeUserSimulatorAgent();
// Connect both agents
await Promise.all([realtimeAdapter.connect(), audioUserSim.connect()]);
});
it("should handle voice-to-voice conversation", async () => {
const result = await scenario.run({
name: "Real-Time Voice Agent Conversation",
description: "Simulation of a user talking to a real-time voice assistant with live responses",
agents: [
realtimeAdapter,
audioUserSim,
scenario.judgeAgent({
criteria: ["Agent responds helpfully and promptly"],
}),
],
script: [
scenario.user("Hi, I'm looking for a quick vegetarian recipe"), // Text input to kick things off
scenario.agent(), // Agent responds with voice
scenario.user(), // User simulator responds with voice
scenario.agent(), // Agent responds with voice
scenario.judge(), // Evaluate conversation
],
});
expect(result.success).toBe(true);
});
});
This example follows the same pattern you would use in the browser. You create a Realtime session via createVegetarianRecipeSession, wrap it with RealtimeAgentAdapter, and then introduce a RealtimeUserSimulatorAgent to represent the user. The scenario runs a short conversation, then hands the transcript and context to a judge agent who checks whether the interaction met your criteria. The result is a repeatable test that runs automatically, rather than a manual spot check.
Why This Matters
Real-time voice agents fail in ways that don’t always show up in unit tests or basic API checks. You can have latency creeping up after a configuration change, responses that stop mid-sentence, or subtle prompt edits that make the agent slower or less helpful without raising an error.
If your only way of detecting those issues is to manually talk to the system now and then, it’s easy for problems to slip into production. Teams also tend to lose the details of “what went wrong” because the test lives in someone’s memory instead of a script.
Voice-to-voice testing with LangWatch Scenario gives you a way to exercise the full path - audio in, Realtime processing, agent logic, audio out - on every change. You can encode specific behaviors you care about, run them regularly, and know whether a prompt tweak or model switch changed the quality of the interaction. Over time, that shifts testing from intuition and memory toward something you can actually track and iterate on.
How to Get Started
Getting started with real-time voice agent testing in LangWatch Scenario is meant to feel familiar if you already have a test suite.
First, set up your environment by installing the LangWatch Scenario SDK and wiring it into your existing test runner.
pnpm install @langwatch/scenario
Next, build or connect a real-time voice agent session. Typically, this means creating a session factory using OpenAI’s Realtime API, such as createVegetarianRecipeSession(), which you can reuse in both your browser client and your tests.
Then, wrap that session with RealtimeAgentAdapter so the Scenario framework can treat it like an agent. At the same time, create a RealtimeUserSimulatorAgent that will play the role of the user in your tests. Together, they give you both sides of the conversation: the assistant and the simulated user.
Once that’s in place, define your scenarios using scenario.run, scenario.user, scenario.agent, and scenario.judge. This is where you describe the conversational flow and the criteria that matter to you, whether that’s helpfulness, promptness, adherence to certain rules, or domain-specific checks.
Finally, run these scenarios locally and in CI, just like any other test. As you gather results and logs, you can refine prompts, adjust timeouts, and tune behavior over time. The important part is that the process becomes repeatable: you can rerun the same scenarios whenever something changes and see how the voice experience evolves.
For a full working example, check out our repo
And be sure to check out the Scenario docs to see the full host of features and functionalities built in:.
Ready to view the results in the LangWatch Platform? Sign-up or book a call with me or my colleague via this link..
Frequently Asked Questions (FAQ)
Q: What is a real-time voice agent?
A real-time voice agent is an AI system that processes and responds to voice input with low latency, typically using OpenAI’s Realtime API to stream audio in and out. Instead of sending a single text request and waiting for a complete text response, you get an ongoing, spoken conversation with overlapping turns and streaming updates.
Q: Can I test voice agents without audio hardware?
Yes. In LangWatch Scenario, audio input and output are handled programmatically through the Realtime sessions, so your tests can run on a CI server without microphones or speakers. The simulator and agent exchange audio frames as data, not as physical sound.
Q: What languages and platforms are supported?
The realtime Scenario components are written in TypeScript and integrate with the OpenAI Realtime API. You run them in Node.js for automated tests, and the same underlying patterns apply to browser-based clients for live demos and production experiences.
Scenario is also available in Python. Core support for Realtime agent testing is coming soon!
Q: How does RealtimeUserSimulatorAgent work?
RealtimeUserSimulatorAgent creates its own RealtimeSession and uses the same primitives as your voice agent, but from the user’s side of the conversation. When you define steps like scenario.user(), it sends user turns, receives the agent’s responses, and participates in the conversation just like a real user would - only in a way that’s fully scriptable and repeatable.
Q: Is this approach suitable for production readiness testing?
Yes. These scenarios are designed to cover the real-time behavior you will actually ship: latency, interaction flow, and conversational quality. By running them alongside your other tests before deploying, you can catch regressions and validate that your voice agent still behaves the way you expect after changes to prompts, models, or configurations.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.