LLM-as-a-Judge: Using the Panel of Judges Approach to Approximate Human Preference
Discover how multiple LLM as a judge evals create a panel system that match with human preference for subjective AI quality.
 Rogerio Chaves · August 7, 2025 · LLM Evals
Rogerio Chaves · August 7, 2025 · LLM EvalsMany applications are being built with LLMs and agents: RAG, unstructured text extraction, automation, conversational systems, and so on. For all of them, evaluation is essential. If you don’t have a way to measure quality, you’ll be forced to rely on gut feelings without any metrics - and you’ll be afraid to make changes to prompts, models, or architecture.
Different Agents, Different Evaluation Strategies
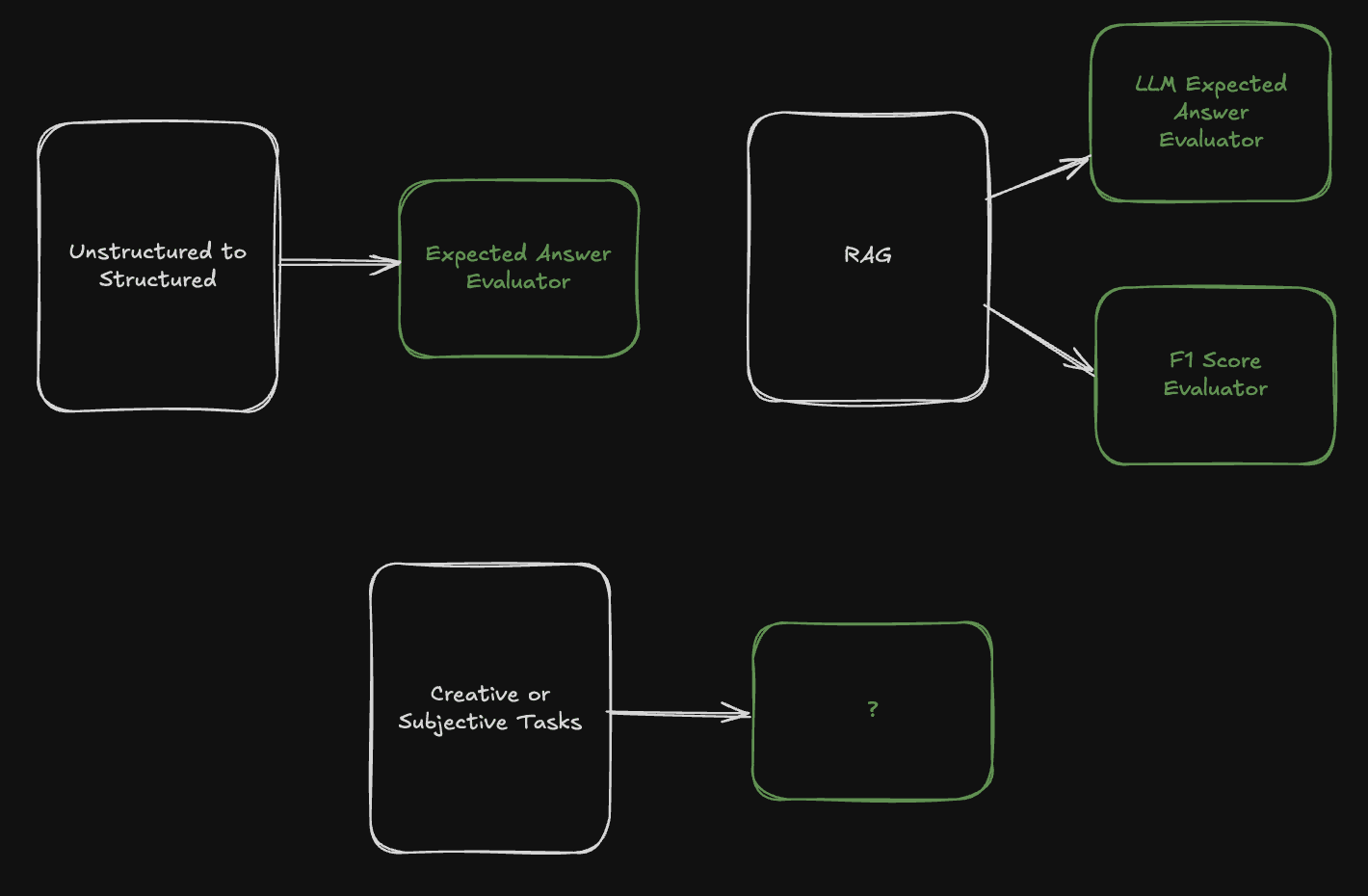
Some tasks are easier to evaluate. For example, categorization and unstructured-to-structured conversions can be measured with simple accuracy - it's either correct or not, based on a dataset. RAG is trickier, but with the right evaluators, you can measure retrieval F1 scores and assess answer correctness using an LLM to compare the answers - and still get high confidence in performance.
But many other applications still face the challenge of evaluating quality when there is no golden truth to rely on. Think about a consultant agent creating presentations for executives, or a business coach assistant with psychological insight, or an academic research agent surfacing papers.
How do you measure the quality of those outputs? And how do you steer it in the right direction?
The First Attempt: Automated Quality Evaluators
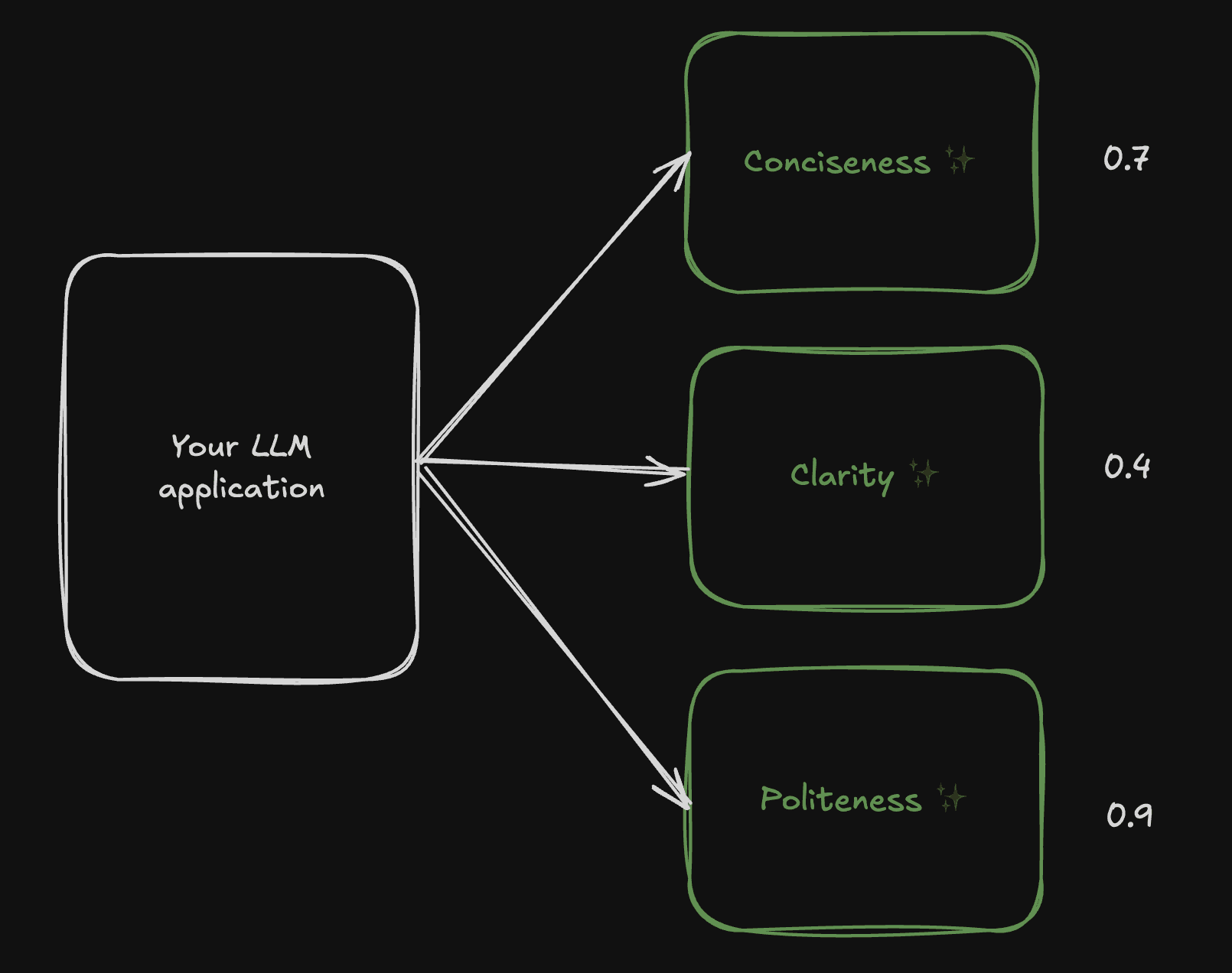
One of the earliest ideas for evaluating LLM output was the use of out-of-the-box “quality evaluators.” These would measure metrics like “Conciseness,” “Clarity,” and “Politeness,” and give a score (for example, from 0.0 to 1.0), supposedly indicating how good an answer was.
Very quickly, people realized these metrics are useless. First, because foundational models like GPT, Claude, Gemini, and others are already trained to optimize for general writing quality. Second, because these scores are too generic to be helpful in a specific domain. And third, because the results are uninterpretable: what does a score of 6.5 mean? What should you do with that?
The Second Wave: Custom LLM-as-a-Judge with Binary Outcomes
As people continued seeking effective ways to evaluate LLM outputs, generic numerical ratings were replaced by custom LLM-as-a-judge systems with binary outcomes.
The custom LLM-as-a-judge approach means there’s no free lunch - if you want to measure the quality of your product, you need to invest the effort. You need the right tools to annotate data, do error analysis, build judges, and most importantly: look at your data. Start creating evaluators specifically tailored to your product.
The binary outcomes part means returning true or false, instead of a numeric score from 0.0 to 1.0. This greatly improves interpretability. It forces both the evaluator and the evaluation logic to make a clear judgment: for each case, the output either passes or fails.
This method works well for identifying major classes of errors, preventing regressions, and even catching issues in production.
However, it still leaves a gap. Binary outcomes work great for objective, observable problems - but if you want your LLM to “design high-quality presentations” or “sound like an expert in finance,” things that are more subjective and nuanced, it’s still hard to measure and optimize for that feeling - and to know how close you are to achieving it.

Enter the Panel of Judges Approach
LLMs are, arguably, the best machines we have for understanding human language. When prompted properly, they can capture nuance. So while individual numerical scores aren’t very interpretable, they still hold value in aggregate.
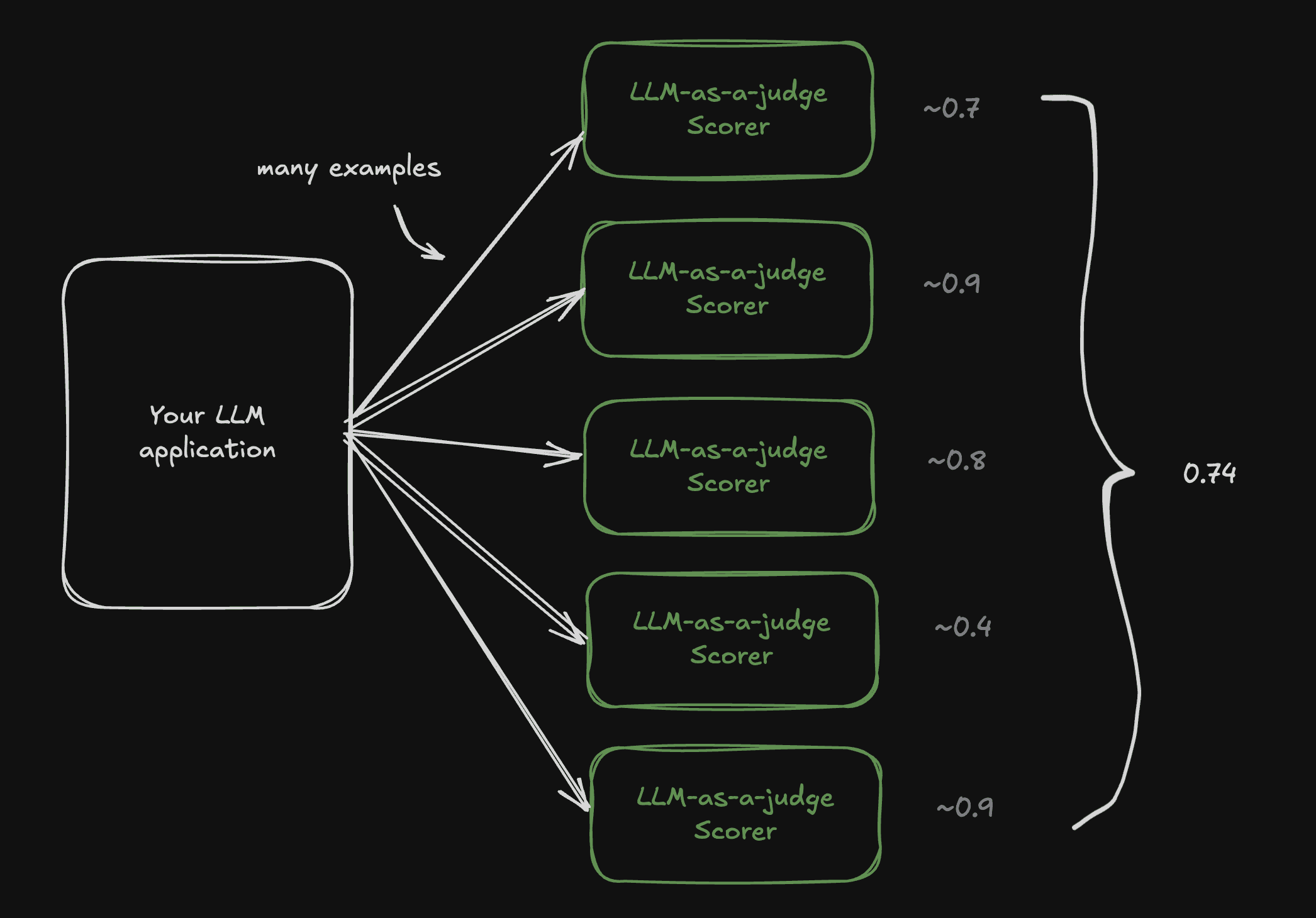
This is the idea behind the Panel of Judges Approach. A single judge with a score metric is often hard to trust, and you’ll likely disagree with it frequently. But by combining both earlier approaches, using multiple custom LLM-as-a-judge evaluators, each outputting a score, we’ve found on our clients that maximizing scores across the board correlates with maximizing human preference.
One judge isn’t enough, but 5 to 10 judges can help capture and optimize for subjective qualities like expertise and perceived quality.
In Summary, the Trick Is:
-
Look at your data: ask a domain expert to freely annotate several conversations
-
Group the annotations: identify 5 to 10 recurring “angles” or themes the expert flagged
-
Write custom LLM-as-a-judge evaluators to score outputs on each of those metrics
-
Test against your current prompts, review the results, and adjust the judges with expert input
-
Iterate: tweak your prompts or even your models to maximize scores across the panel and watch your quality improve
This gives a kind of redemption to the original idea of automated quality evaluators. But with a twist: the realization that looking at your data and customizing for your specific problem is essential.
Of course, when you run these evaluations, you’ll get multiple scores, but those should never be interpreted individually, always in aggregate.
Where Can LangWatch Help?
From day one, LangWatch has been the platform for LLM evaluations, especially when it comes to domain expert collaboration. It helps teams quickly ramp up and build custom evaluators, with tools like:
-
Powerful, customizable LLM-as-a-judge setups for binary outcomes, scoring, or categorization
-
A completely agnostic, unopinionated API so you can run evaluations with any custom metric, no need to change your tech stack
-
The Optimization Studio: build and run evaluations directly on the platform, with domain experts in the loop
-
Real-time evaluators, no need to host anything yourself
-
Annotation tools and production datasets that feel like Google Docs or Sheets, so domain experts can collaborate naturally
Start building your Panel of Judges today or book a demo for a free consultation with our team.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.