The Ultimate RAG Blueprint: Everything you need to know about RAG in 2025/2026
Use this guide as the map for building and evaluating any RAG system
 Rogerio · October 6, 2025 · Integrations
Rogerio · October 6, 2025 · Integrations
It’s been a couple of years since RAG (Retrieval-Augmented Generation) first exploded in popularity, and today, it quietly powers most modern AI agents, copilots, and chat systems.
At LangWatch, after two years helping teams ship production-grade RAG systems, we’ve mapped the core abstractions that define how any retrieval agent really works.
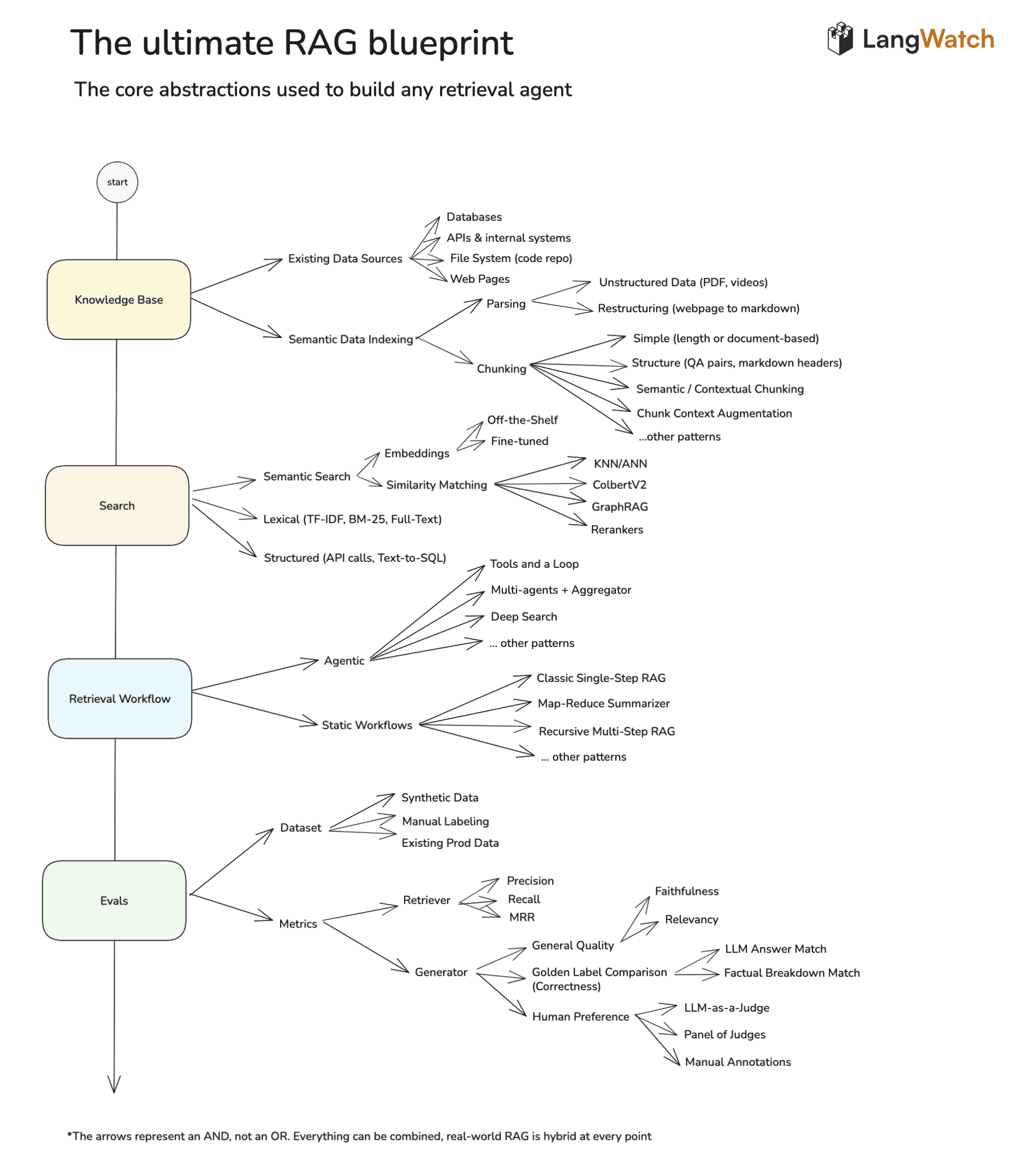
The Ultimate RAG Blueprint Diagram
Below is the full RAG architecture map, from data ingestion to evaluation.
This blueprint shows how knowledge bases, search layers, retrieval workflows, and evaluation loops fit together into one unified retrieval ecosystem.
Video Explanation (7 min)
In the video below, we walk through how Agentic RAG, Hybrid Search, and Eval loops evolved to form today’s retrieval systems.
Full Transcript:
Hey there, I wanted to record this video to talk about this - the ultimate RAG blueprint, and nope, RAG is not dead.
It maybe lost its hype a little bit, but a lot of what agents do is still RAG. Like when you’re doing a deep search with ChatGPT, right? This is RAG ’cause basically all it does is go and research on the internet, get some websites, do some more search, then build on top of this search to try to answer your question.
Or when you are in Cursor and then it starts reading all these files one by one to try and understand what’s going on, and then edit the code or give you an answer. Those are all basically RAG.
And it doesn’t matter how the term evolved over time - GraphRAG, AgenticRAG, HybridRAG - everyone is still retrieving, augmenting, and generating.
So no matter what you’re doing, if you’re building an agent and you want your agent to reply based on something, you are following this structure.
First, it starts with a knowledge base, right?
And this knowledge base can be either existing data sources or semantic data indexes.
This is where a lot of people say that RAG is dead, because they think of RAG just as the semantic search - but that’s not true.
RAG is also about the existing data sources that exist - for example, the internet, like the deep search or existing database that you have, or APIs and internal systems that the company might have, or even a file system for a code repo. This is the case of Cursor actually searching on your file system.
Then if you don’t have data indexed, or maybe even if you do, you might want to reindex it semantically.
And then to reindex data semantically, you get a dataset or knowledge base that already exists, and then you parse it so that it can be understood by the LLM that later is going to generate the embeddings for it.
You take data from PDFs or from videos and you translate it to natural text if that’s easier to consume. You can also restructure this data.
For example, transforming a web page from HTML to markdown to make it easier for LLMs, again, to understand.
And then you have a bunch of different techniques for chunking. You might chunk just per paragraph, per length, or you can use the structure of QA pairs - use the markdown headers in your favor.
You might do some contextual chunking - when you use another LLM to understand how to break this content better, you can augment this context so that each small piece still contains the whole hierarchy and never lose context for improving search later on.
But no matter what you’re doing, you are at the end of the day building your knowledge base, right?
This knowledge base later needs to be searched, and then here again it doesn’t matter if you’re doing agentic RAG or non-agentic RAG - something needs to search it.
And this search can be done via semantic search, which is what got RAG popular. But the key part of searching is still the lexical search or the traditional search that we used to know.
And now you can also do generated structure search - that is, you can use AI to generate the parameters for your API calls, or even a bunch of SQL queries to explore the data.
If you’re doing semantic search, then you need to decide which type of embeddings to use. All the big labs basically have their own off-the-shelf models - OpenAI, Gemini and whatnot.
But it might be worth it to fine-tune your own embeddings model. For example, in a dating app where you might want people that love coffee and people that hate coffee to be far apart on the embedding space.
Then after having those embeddings, you have different techniques on how you can find them later and rank for the best similarity.
When we talk about vector databases, in almost all cases we’re talking about k-NN or ANN, but there’s also different techniques like COBERT-V2 or the GraphRAG that got super popular.
And then once you have those matching results, you can re-rank to prioritize the signal over the noise to the LLM.
Still, having a hybrid between semantic search and lexical search has proven to give better results than semantic search alone.
And the structure search allows you to search data that you cannot even possibly index on the vector databases - for example, some private APIs for very enterprise company data, or even infrastructure data monitoring how your machines are operating.
In practice, all those are combined, and you use whatever gives you the best results.
Then… after having search mechanisms in place, you need to think of your retrieval workflow. And this is what a lot of people talk about - the Agentic RAG.
In the Agentic RAG, in opposition to the traditional RAG with a classic single step, instead of just going to the search, returning the results, and then replying to the user, you can give tools and a loop to an agent.
And then the agent itself decides what kind of search it wants, what kind of API calls it’s going to do, and that can do that in a loop until it gives you the best answer.
You can also decide to go for multi-agent. So maybe you run a bunch of agents in parallel, each one doing searches in different systems, and then you have an aggregator at the end that just analyzes and summarizes the raw results.
This is similar to deep search, but when we talk deep search, we generally mean taking a step even further and searching for several minutes and keeping a notebook with the notes where you keep aggregating data.
There are, of course, an infinite amount of patterns that you can try here and see what issues the best results.
However, a lot of times the non-agentic static workflows may be very valuable because they are generally faster and cheaper. Classic single-step RAG can give your users an immediate answer.
The MapReduce Summarizer is the simpler version of the multi-agents aggregator. And here as well, you have basically an infinite number of patterns.
Now, which one of those is better? None of those. None of those are better.
That’s why you need to evaluate, and you need to find out what is better for you, your data, and your use case.
So after getting a knowledge base, searching, retrieving - now it’s time to know if the results make any sense.
To do that, first you need a dataset to compare. And you can kick off your dataset by using synthetic data.
For example, if you give your knowledge base to an AI and ask it to generate probable questions based on the data that you already have available.
A lot of those will probably need to be manually labeled for starters, so you can remove the examples that are actually wrong and not evaluate based on that.
And if you have something already running and you have feedback from customers, you can use existing production data, see the feedback from the users, and then use that as a reference on what’s good and what’s not.
With your dataset in hand, you still need some metrics, so that every time that you change your retrieval workflows or your searching methods, you can run that again and you know if your RAG has now improved.
The most straightforward to measure is, of course, the retrieval or the search mechanism that you have here above.
Given an input, what is the precision and what is the recall of the documents retrieved?
Precision means that we only retrieved signal, not noise, even though we might not have retrieved all the signal that was there to be retrieved.
And recall means that we did retrieve all the signal that was there, even though we got some noise together.
The key is to balance those two.
Then after having a great retriever, you also want to have a great generator.
Given the perfect documents, how do you know the answer of the AI is good?
Well, there are some general quality metrics like faithfulness and relevancy, but honestly nowadays most models are really good at them.
However, if this is low, it might indicate that your retriever is still not as good.
Then the best way to compare is if you actually have a golden label.
This measures the correctness of the answer for those cases where you do have a correct answer.
And you can easily check if the answer your RAG generated is correct by using another LLM to check if those answers match.
You can also go a step further and break it down into sentences and see if each sentence is factually correct and score for each fact how much they match compared to the golden label.
Still, a big part of RAG is human preference - the writing style, the psychology terms, the coaching techniques, or the slides that it generates at the end.
For that, you can use an LLM as a judge - to validate specific criteria that you found on the error analysis that you did when looking at your data.
If you put a bunch of those together, then you can create a panel of judges that captures a bunch of those nuances together and even though less interpretable, it aligns better with human preference.
And of course, it’s still incredibly valuable to do manual annotations, having someone checking the end result if any of it makes sense.
Having these evaluations allows you to refactor the other parts of your RAG - choose different storing mechanisms, retrieval or agentic flows - knowing that your solution is always improving.
That’s why we also have a footnote here saying the arrows represent “and,” not “or.”
Everything can be combined as real-world RAG is hybrid at every point.
I’m going to drop the link to the ultimate RAG blueprint in the comments.
Thanks for watching.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.