

AI evaluations, automated - from dev to production
Test your agents and prevent regressions
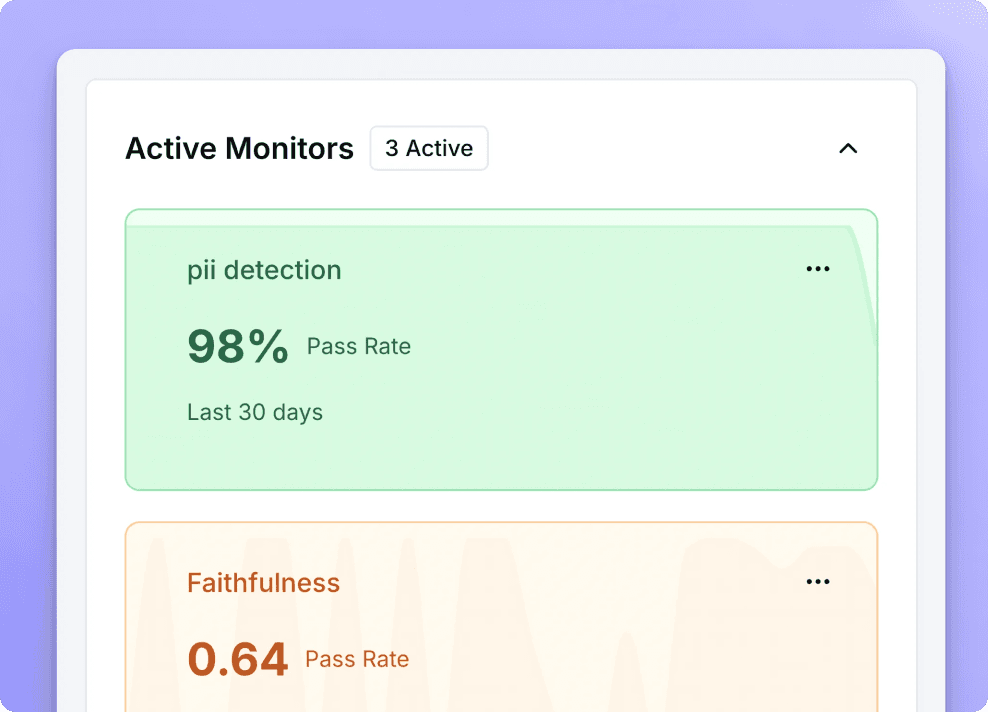
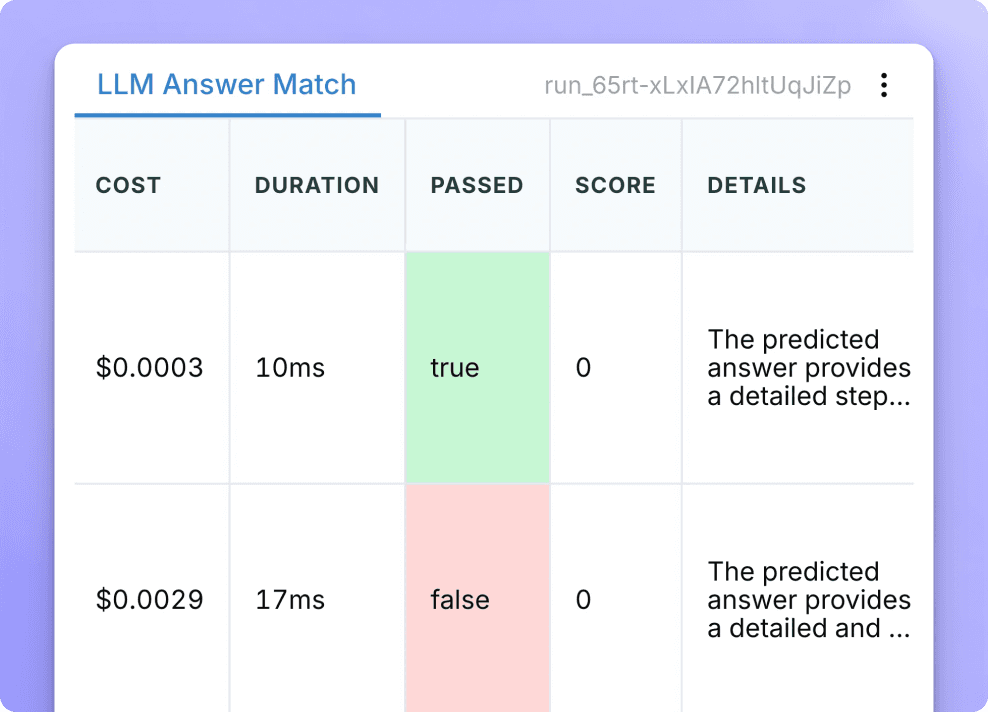
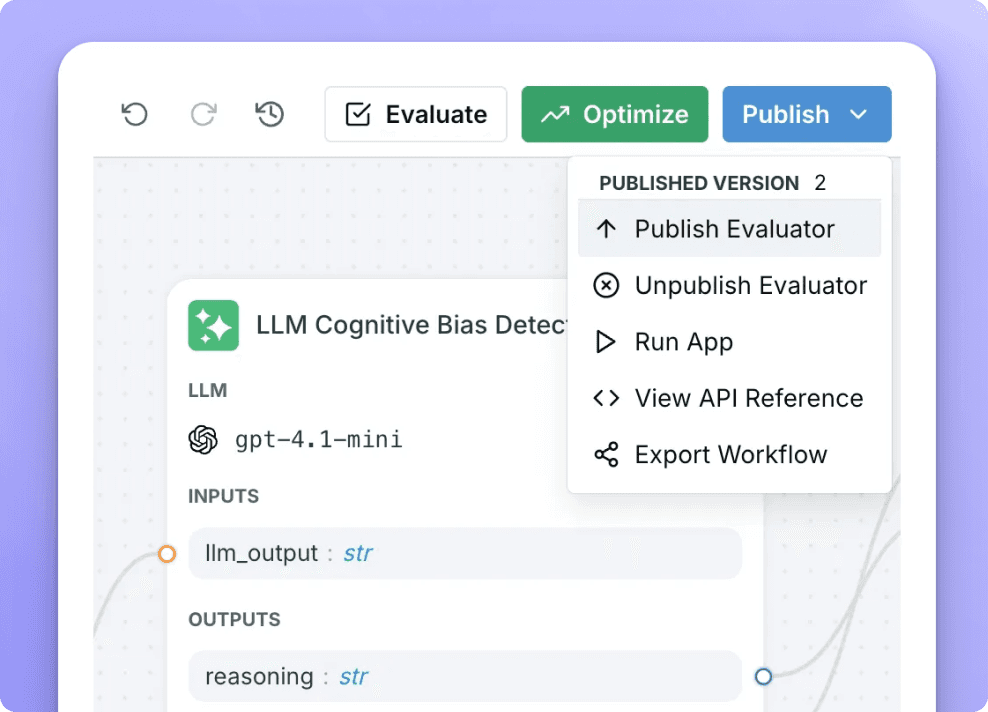

Enable anyone on your team, product, devs, QA, domain experts to define your quality framework and run evaluations with zero code
Run Experiments from your CI/CD, and test
before they’re pushed to production
No-code interface
to build eval logic and workflows
Collaborate across teams
with shared evaluations and result views

CI/CD Evaluation Pipelines
Run evaluations continuously as part of your deployment stack. Keep your own infrastructure and workflows — no changes required.
Evaluate Structured Outputs and Tool Calls
Support complex evaluation formats, from JSON and function calling to multi-tool agents. Understand how your models behave in real-world applications
Air-Gapped and Self-Hostable
Run everything locally or in your private cloud. No lock-in, no external dependency full control over your data, models, and eval flows.
From Evaluation to Optimization
Automatically tune prompts, selectors, and agents based on evaluation feedback.


