Background Agents on Slack: How we built our own Claude Tag before it was cool
A fleet of background agents runs a chunk of our engineering, each one scoped to one job and living in its own Slack channel. We built it before Anthropic shipped the same shape as Claude Tag.
 Rogerio Chaves · July 5, 2026 · Article
Rogerio Chaves · July 5, 2026 · ArticleOn our Slack there is a section in the sidebar called LangWatch Agents. Seven of the channels under it are agents that each do one job, and an eighth is just a status feed from the box they run on.
The channel names are the jobs: agent-dependabot-scout, agent-clickhouse-optimizer, agent-changelog-scribe, agent-customer-pulse, agent-tech-debt-fixer, agent-post-deploy-verifier, and agent-pr-reviewer.
Dependabot alerts pile up faster every month now that everyone ships more code with AI, us included, so one agent does nothing but triage them. Another pulls our slowest ClickHouse queries and proposes rewrites, so the product gets a little faster on its own.
The rest draft the weekly changelog, summarize what customers did that week, work through low-priority tech debt, and confirm a production deploy came up clean. The seventh reads the pull requests the other six open and reviews the diff.
Each of the seven is the same kind of thing: a coding agent running headless on a shared box, scoped to one repo and a few tools, pointed at a single Slack channel.
It wakes on a schedule, reads the repo and whatever context its job needs, does the one thing it is for, and posts the result in its channel: what it looked at, what it decided, and a link to any pull request it opened. When we want it to go a different way, we reply in the thread, and it reads the reply and keeps going.
None of them can merge. Every prompt ends with the same instruction, open a pull request, never merge, never approve, and a person makes every merge call. That single rule is what lets us leave the whole set running while we get on with other things.
It is mostly hands-off, day to day. Each agent has its one job and does it on its own, and most mornings we only notice it when there is a pull request to review. We can open any thread to take a look, steer it, or push back, and sometimes we do, but we are not babysitting them.
Most of our own day goes into the Claude Code and Codex sessions we drive by hand on our laptops. The fleet is those same tools pointed only at the chores that come back every week and automate cleanly, like validating a Dependabot bump; we would not hand a task that genuinely needs driving to a background agent. It is not truly hands-off, though, and from experience we know it cannot be: a person still reviews every pull request.
One agent is a long-lived tmux session, named by its slug, with Claude Code running inside it, or Codex for the reviewer. The session is never torn down. A small CLI called kanban-code owns these sessions, and on every boot one systemd service brings the whole fleet back:
# agents-reconcile.service
ExecStart=/usr/local/bin/kanban reconcile
kanban reconcile launches a fresh session per agent or resumes the one already there, so the same panes are always sitting in tmux waiting for work. When kanban-code hands an agent a prompt, it is a tmux send-keys into that pane; the CLI just wraps the session bookkeeping around that one primitive.
What each agent is and does is plain data. The whole fleet is a list in Terraform that renders to a single agents.yaml on the box. Here is the ClickHouse one from the scene below, with the other agents around it trimmed out:
- slug: clickhouse-optimizer
runtime: claude
repos:
- langwatch/langwatch
model: opus
slackChannel: "#agent-clickhouse-optimizer"
schedule: "09:00"
dailyPrompt: |
Good morning. Use the optimize-clickhouse-slow-queries skill
(/optimize-clickhouse-slow-queries) to do today's run end to end.
The skill covers sourcing the prod-CloudWatch reader credentials,
finding the two slowest queries in the last 24h, and opening one
advisory optimisation PR per query against langwatch/langwatch.
The prompt is deliberately short. The real instructions live in a skill, /optimize-clickhouse-slow-queries, a SKILL.md the agent reads and follows. The never-merge rule is written down there, in the skill's own words:
Advisory only: open the PR, never merge or approve it. You run
EXPLAIN via /ops to validate, the human still ships.
So how does the day's work reach a running session? A per-agent systemd timer, staggered so they don't all fire at once:
# agent-nudge-clickhouse-optimizer.timer
OnCalendar=Mon..Fri *-*-* 09:00:00 Europe/Berlin
Persistent=false
When it fires, it runs agent-nudge.sh, which reads that agent's dailyPrompt out of agents.yaml and hands it to the session with one line:
/usr/local/bin/kanban send "$SLUG" "$PROMPT"
A kanban send does not restart anything. It types the prompt straight into the tmux pane that is already running, the same session that still remembers what it did yesterday. The box's own health check drives those panes with the exact same primitive when it needs to, a tmux send-keys aimed at the session by slug:
tmux send-keys -t "$slug" ...
Two guards keep that honest across reboots. Persistent=false tells systemd never to replay a nudge it missed while the box was asleep, so a timer that fired into a sleeping box is skipped, not queued up for later. And agent-nudge.sh writes a per-day stamp file only after a send succeeds, and bails if today's stamp already exists, so a mid-day restart cannot fire the same nudge twice. At most one nudge per agent per day, delivered into the same live session. The behaviour spec says it plainly: the nudge "is sent into the existing long-lived session" and "the session is not restarted or recreated."
Giving each agent its own channel is the part I underrated at first. The channel is where the agent shows its work, and where we push back on it.
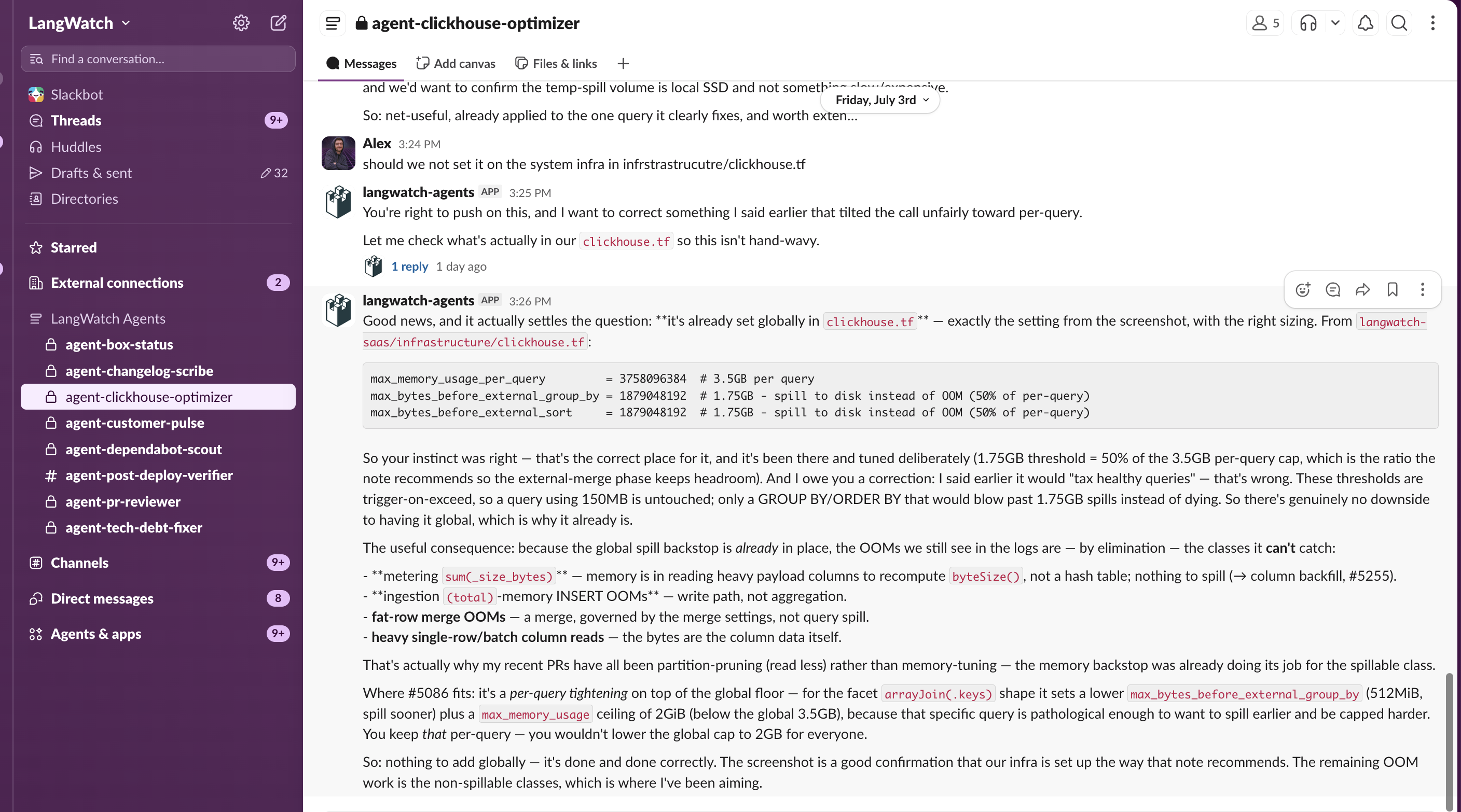
That is the agent-clickhouse-optimizer channel. Alex, one of our engineers, pushed back on where a ClickHouse memory setting belonged, and the agent rechecked the config and walked back an earlier claim. That is ordinary coding-agent behavior, nothing special. What matters is where it happened: in the open, in a thread anyone on the team could read and redirect, instead of inside some agent's private run.
The seventh agent, agent-pr-reviewer, is where the fleet checks itself. It watches for new pull requests, the agents' and ours, reads the diff, and leaves a review. It runs on a different model from the six that write the code, so the reviewer has no stake in the author's assumptions.
That watching is not the agent polling on its own. A second systemd timer runs a small watcher that lists open pull requests with gh, waits a few minutes so CI and the first-pass bots go first, and then hands the reviewer the job the same way the daily nudge does:
/usr/local/bin/kanban send "pr-reviewer" \
"Please review the PR $url using the review skill. Reuse your
existing worktree for that repo (gh pr checkout), do not re-clone.
Post your findings as a PR comment."
There is a second watcher like it for deploys. A prod deploy for us is a "Bump submodules" commit landing on the langwatch-saas main branch, so a deploy watcher polls that branch every ten minutes, reads the deployed app SHA out of the commit's +Subproject commit line, and fires the post-deploy-verifier at it with a plain kanban send carrying that SHA. Same shape as the PR watcher: a timer notices an event, a send drops the job into a live session, and the Slack bridge (kanban slack bridge) mirrors the whole exchange back into the channel so we can watch and interrupt.
Which tool goes on which job, and why the reviewer is on Codex while the builders are on Claude Code, is a whole separate argument, one we are writing up as a companion post. For this post the wiring is what matters: the six build, a different reader reviews, and a person merges.
We keep one session alive per channel and reuse it, instead of spinning up a fresh agent for each job. It compacts as it fills up and keeps what it has already done in memory, so agent-dependabot-scout wakes the next morning and picks up the next dependency, and agent-clickhouse-optimizer takes whatever slow query showed up overnight, each one still carrying the context from its earlier runs. Most setups we looked at do the opposite: they spin an agent up for one task and throw it away, so the next run starts cold and has to relearn the codebase from scratch.
The box itself does not stay up. It is an EC2 spot instance that stops itself overnight once it sits idle, to keep the bill honest, and the whole thing, the box, the timers, the agent list, the skills, is Terraform. On the next morning's wake, agents-reconcile.service runs kanban reconcile and every session resumes where it left off, so the nudge that fires a few minutes later lands in an agent that still remembers everything.
On 23 June, Anthropic shipped Claude Tag: a persistent Claude that lives in a Slack channel, with scoped access to your tools and code, that picks up work you hand it in a thread the team can watch. Karpathy called it the third major redesign of LLM interfaces.
It is the same object we had been running for months, underneath the Slack channel it lives in: a session with an identity and a persistent memory, that you hand work to and that remembers what it did last time.
I do not want to make that a we-did-it-first, because it mostly is not true for anyone.
The parts were on the shelf already: a coding agent that holds a long headless session, a Slack app, a line in a scheduler. We wired them together for ourselves, and Anthropic turned the same wiring into a product more teams can pick up.
The value has been real and mostly boring. The slow ClickHouse queries do get faster, one small pull request at a time, and our worst query times have drifted down for weeks with nobody running it as a project. The Dependabot backlog stays triaged instead of rotting into a wall of red we learn to ignore, and the changelog has a first draft by Friday that a person only has to edit.
None of this has gone badly wrong for us, and that is down to how it is wired more than to luck. Everything an agent produces goes through a pull request a person approves, the work happens in a channel the whole team can read and interrupt, and each agent holds just enough access to explore and run EXPLAIN but not to drop a table or force-push over anything that matters. The worst a confused one can usually do is open a bad pull request or post a wrong answer in its channel, and a person sees both first.
One worry does get heavier as the fleet grows. Once a handful of persistent agents are acting against your real systems every day, you want to know who ran what, what it cost, and whether it stayed inside policy.
Each of these agents is a Claude Code session, Codex for the reviewer, so the cost and usage we watch on them come from LangWatch, the product we sell, pointed at ourselves. If you run Claude Code, you can track its usage and cost the same way.
Frequently asked questions
- What is a background agent?
- For us it is a coding agent running headless on a schedule, scoped to one repo and a handful of tools, and wired to its own Slack channel. It wakes up, does one job like triaging Dependabot alerts or rewriting a slow query, opens a pull request, and posts what it did in the channel so we can steer it. It cannot merge; a person makes every merge call.
- How is this different from Claude Tag?
- It is the same shape. Claude Tag, which Anthropic launched on 23 June 2026, is a persistent Claude in a Slack channel with scoped access that you tag and hand work to. We built our own version out of a coding agent, a Slack app, and a scheduler before it had a name. The main difference is ownership: our transcripts and memory live on our own box rather than inside one vendor.
- Can background agents merge their own code?
- Ours cannot, on purpose. Every agent prompt ends with the same instruction: open a pull request, never merge, never approve. A human reviews and merges everything. That single rule is what makes it safe to leave the fleet running.
- Do you still need people if agents do the work?
- Yes, more than the demos suggest. Left alone, an agent will write down a confident, slightly wrong answer and move on. The value shows up when a human pushes back in the thread and the agent rechecks and corrects itself. It saves us the work of starting something; someone still has to read what comes back.