GPT-5 Release: From Benchmarks to production reality
OpenAI has released its newest flagship model, GPT-5 - Start evaluating the performance within LangWatch available now.
 Manouk Draisma · August 8, 2025 · LLM Evals
Manouk Draisma · August 8, 2025 · LLM EvalsOpenAI has released its newest flagship model, GPT-5.
It arrives with the familiar combination of grand claims - “best model in the world,” “unified reasoning” - and hard numbers from benchmark tests.
The GPT-5 release headlines focus on what’s measurable: reduced hallucinations, improved reasoning, faster responses. These are real, important gains. But if you’re already running AI in production, the more useful question is:
How do these numbers translate into day-to-day application performance, and what should you do next?
At LangWatch, we’re model-agnostic by design. Our focus is not on which model “wins,” but on how to measure, monitor, and optimize whichever model you choose. That makes each new model launch - like GPT-5 - an opportunity to validate assumptions, catch regressions, and improve your stack.
This post is our take on the GPT-5 release: where it advances the state of the art, where it’s still limited, and how to integrate it into your evaluation and monitoring workflow.
What the GPT-5 Benchmarks actually say
OpenAI has positioned GPT-5 as a unified reasoning model that balances advanced capabilities with speed. In practice, there are still multiple variants gpt-5, gpt-5-mini, gpt-5-nano each targeting a different performance-cost trade-off. "to give developers more flexibility to trade off performance, cost, and latency. While GPT‑5 in ChatGPT is a system of reasoning, non-reasoning, and router models, GPT‑5 in the API platform is the reasoning model that powers maximum performance in ChatGPT. Notably, GPT‑5 with minimal reasoning is a different model than the non-reasoning model in ChatGPT, and is better tuned for developers."
From the GPT-5 benchmark results, we can summarize the key data points:
-
Coding: 74.9% on SWE-bench, edging ahead of Claude 4.1’s 74.5%, and above Gemini 1.5’s ~72 - 73%.
-
PhD-level science Q&A: 89.4% accuracy, slightly ahead of most major competitors.
-
Hallucinations: ~4.8% vs 20 - 22% in prior GPT model this is the most substantial improvement.
-
Latency: Noticeable decrease in time-to-first-token (~15 - 20% in our early own LangWatch tests).
-
Access: Reasoning now available to free ChatGPT users.
The gains are incremental. There’s no order-of-magnitude leap in capability, but the drop in hallucination rate is large enough to influence deployment decisions in accuracy-critical environments.
Benchmarks are not the whole story
If you’ve read our earlier post, The Panel of Judges Approach, you know we view benchmarks as an approximation of performance, not a guarantee.
A GPT-5 benchmark score is a useful signal, but:
-
It’s averaged across diverse, synthetic tasks.
-
It doesn’t capture your specific domain language or business rules.
-
It says nothing about model stability over time.
We’ve seen high-scoring models fail on niche workflows: industry-specific compliance questions, nuanced tone matching, or multi-step reasoning chains with tight formatting constraints.
That’s why every GPT-5 release should trigger your own evaluations, against your data, in your workflows, using your success criteria.
Deep-dive: GPT-5 Benchmark results
Below we break down GPT-5’s performance on reasoning, coding, reliability, and a “stress test” benchmark, Humanity’s Last Exam and share where the numbers are most likely to matter in production.
Reasoning capabilities
For deep reasoning, we focus on GPQA Diamond, which measures PhD-level scientific reasoning.

-
GPT-5 Pro + Python tools leads at ~89.4%, slightly ahead of its no-tools variant.
-
Thinking mode (extended reasoning) boosts base GPT-5 from 77.8% → 85.7%.
-
GPT-4o lags at ~70%, showing a significant gap in scientific reasoning tasks.
Across the market, GPT-5 Pro (Python) holds the top spot, with Gemini 2.5 Pro and Grok 4 close behind.
LangWatch tip: Measure reasoning both with and without thinking mode. Gains are real, but so are latency trade-offs.
Code capabilities
Claude models used to dominate coding benchmarks. GPT-5 closes the gap and in some cases, leads.

We look at two practical benchmarks:
-
SWE-bench Verified - solving real GitHub issues with code edits.
-
Aider Polyglot - multi-language code editing correctness.
-
GPT-5 hits 74.9% on SWE-bench and 88% on Aider Polyglot with thinking enabled.
-
Reasoning mode adds +22.1 points on SWE-bench and +61.3 on Aider Polyglot.
-
GPT-4o scores notably lower on both.
LangWatch tip: Benchmark with your real development workflows multi-file changes, repo context, and code review steps before assuming these gains carry over.
Reliability capabilities
Reliability and factual accuracy were central in the GPT-5 release messaging, and here, the numbers match the story.
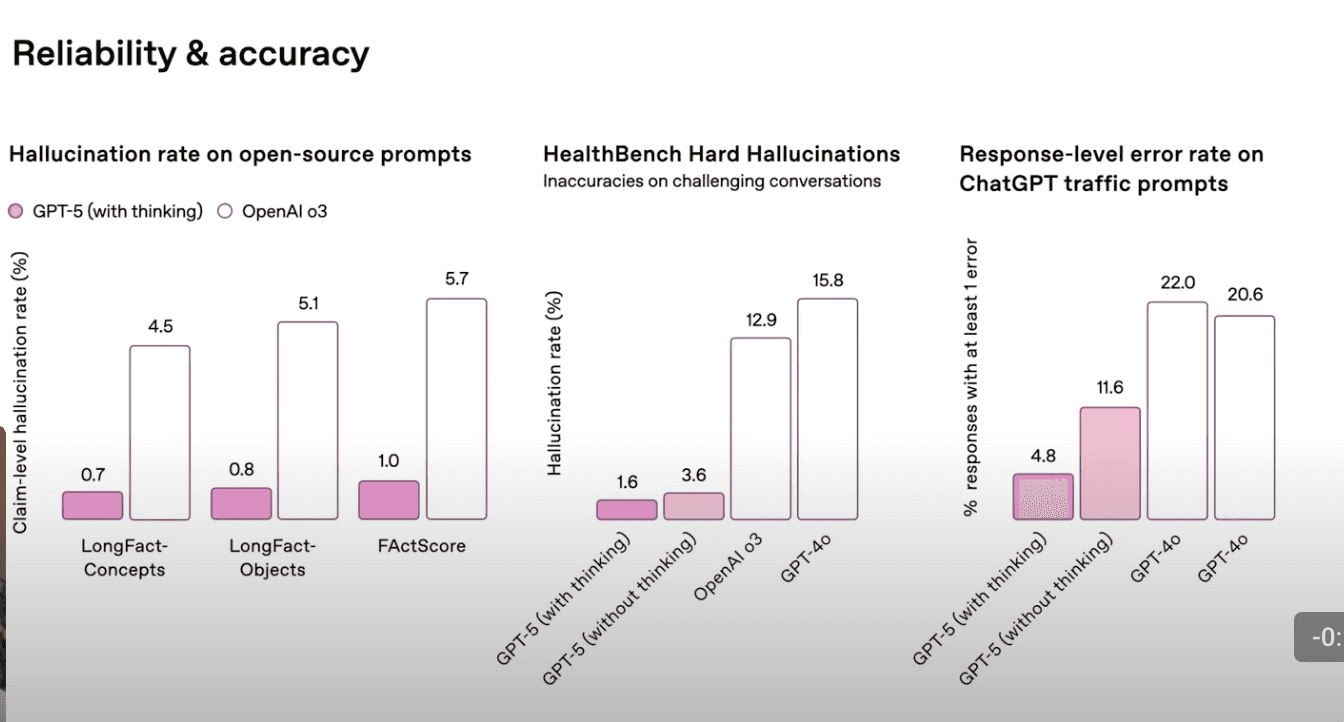
-
GPT-5 (with thinking) records <1% hallucinations on open-source prompts and 1.6% on HealthBench hard cases.
-
Real-world traffic error rates drop from 11.6% → 4.8% when reasoning is enabled.
-
GPT-4o’s error rates are significantly higher across the same categories.
LangWatch tip: Track claim-level error rates in your own environment. Even a 5% hallucination rate means 1 in 20 outputs may still be wrong - unacceptable in high-stakes contexts.
Humanity’s last exam
Humanity’s Last Exam pushes models across expert-level questions in math, science, and humanities.
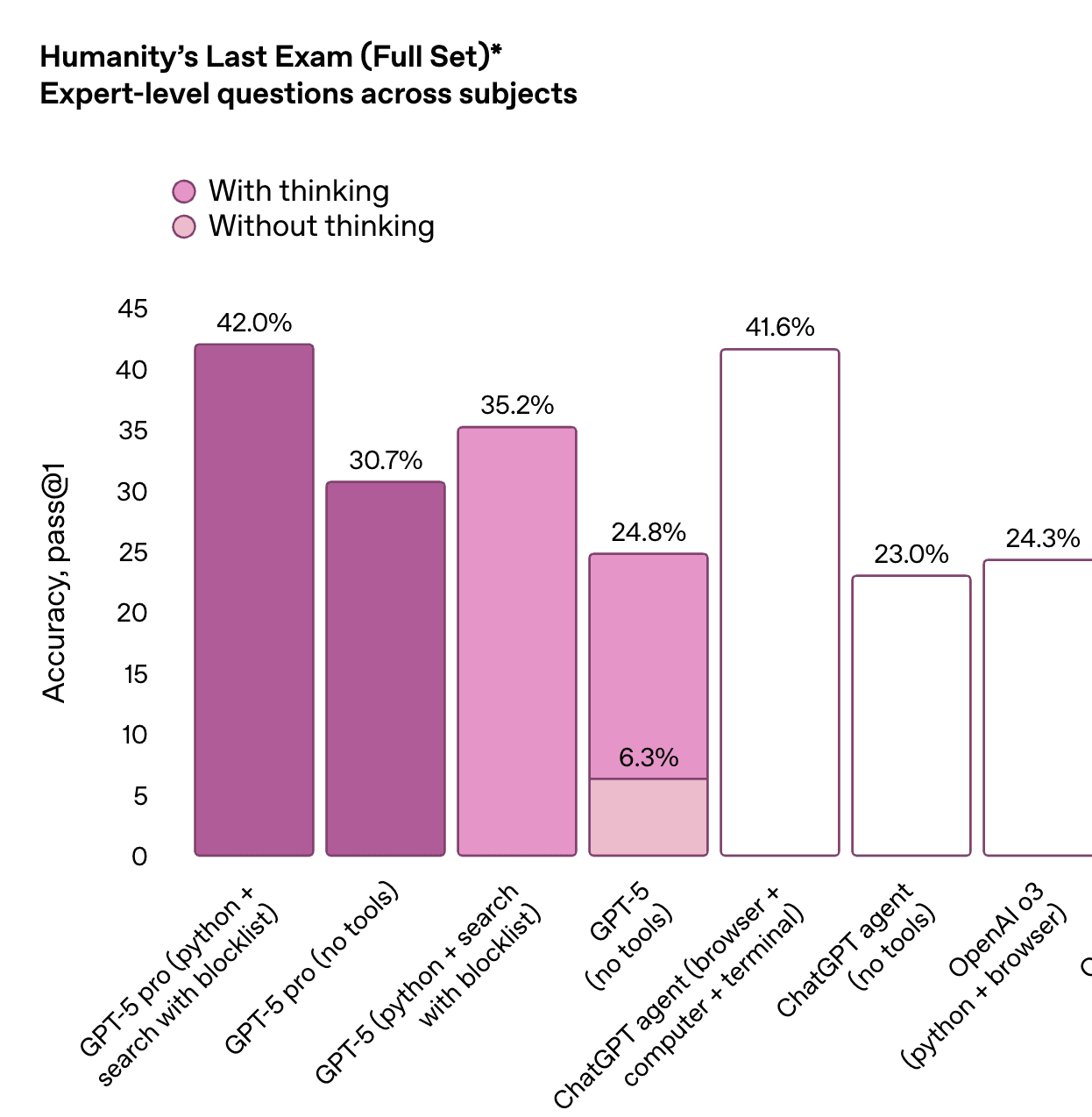
-
GPT-5 Pro (tools + reasoning) scores ~42%, edging past the best ChatGPT agent setups (~41.6%).
-
Thinking mode takes base GPT-5 from 6.3% → 24.8%.
-
Agent stacks still trail GPT-5 Pro here, highlighting orchestration limits.
LangWatch tip: For agentic setups, test both model-only and model+tools performance weak orchestration can bottleneck even the strongest model.
LLM Hallucinations: Why this drop matters
Going from ~20% to under 5% hallucination rates means:
-
Fewer factual errors in customer-facing responses.
-
More predictable structured data extraction.
-
Lower guardrail rejections.
In finance, healthcare, or legal contexts, this can shift AI from “too risky” to “viable” provided you still monitor and evaluate your AI products closely.
Latency: The overlooked metric
A 15 - 20% latency reduction:
-
Improves chat flow.
-
Reduces abandonment in live support.
-
Speeds up coding assistant feedback loops.
But latency gains only matter if you’ve profiled your entire pipeline.
Why “Unified model” still means choices
You still need to choose between:
-
gpt-5: highest capability, highest cost.
-
gpt-5-mini: balanced.
-
gpt-5-nano: fastest and cheapest.
Testing each in your context avoids over- or under-spending.
Implementation beats model choice
Switching models without improving prompts, context handling, and monitoring rarely moves the needle.
The levers that matter:
-
Prompt/context engineering.
-
Continuous evaluation.
-
Observability.
-
Guardrails.
LangWatch operationalizes all four.
How to evaluate GPT-5 in LangWatch
GPT-5 in LangWatch available now
You can already:
-
Run GPT-5 benchmarks on your data.
-
Track hallucination rates over time.
-
Compare all GPT-5 variants side-by-side.
-
Catch regressions automatically.
-
Import / create your evaluation sets - real and synthetic cases.
-
Run side-by-side GPT-5 benchmarks with your baseline model in the optimization studio.
-
Add evaluations or write scenarios to score correctness, tone, and compliance.
-
Monitor in pre-production with shadow traffic.
-
Roll out gradually with live monitoring enabled.
No code changes just swap the model in LangWatch and run your tests.
Treat GPT-5 as an evaluation window, not an auto-upgrade. Test for at least a week, review with both automated and human scoring, and re-benchmark to catch performance issues.
Last but not least, OpenAI’s GPT-OSS isn’t just another model release. It’s a signal that high-quality AI is turning into common infrastructure - available to anyone, on any hardware, at any cloud. The winners will be the teams who treat that infrastructure as a starting point and race to add the data, design and trust layers that truly set them apart.
The only way to know if it’s worth switching is to run the benchmarks yourself on your own data, in your own workflows. LangWatch makes that both fast and repeatable.
💡 Want to see how GPT-5 compares to Claude, Gemini, Grok or any other model for your use case?
Compare them in LangWatch.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.