Building an LLM Eval framework that actually works in practice

Manouk
Mar 20, 2025
Evals are the thing of 2025 and building high-quality Evals is one of the most impact investments you can make.
Why are Evals important?
As long as our team has been focussing on having our users Shipping Qualitative LLM-apps, it finally kicks in! AI teams all over the world are seeing the shift and the need of evals is here!
Companies are evolving rapidly from prototypes and experiments to mature products in production. Teams realize that you can't effectively build and refine generative AI products without robust evals.
As more organizations prioritize evals, we've noticed that many teams struggle with where to begin, finding some concepts confusing.
The initial thought seems clear—“We need relevant evals to measure our product’s performance”—but the specifics on "how" can feel unclear. There's also plenty of market noise debating the "best evals," and it's tempting to adopt simple, off-the-shelf metrics that might not truly be helpful.
At LangWatch, we've found that the best approach is practical and straightforward: Identify what needs improvement, determine how to measure it, and create targeted evals for your highest priority metrics. This establishes a repeatable process your team can use to monitor production, analyze data, and iterate on your core AI system (prompts, RAG, etc.) and your evals as insights grow.
In this post, we'll demonstrate how LangWatch enables you to integrate various types of evals, provide guidance on when and how to use them, and outline a lightweight process to iteratively enhance your eval suite.
Ultimately, the goal is continuous improvement—better insights into product performance, and faster iterations that enhance your AI products for customers.
What are "Evals"?
First, let's clarify what "evals" actually mean, as that can sometimes be confusing!
Evals are individual evaluation criteria you apply to data samples. Each criterion typically involves calculating an aggregate score across a dataset and conducting individual, case-level analyses. People often interchangeably reference eval criteria, aggregate metrics, and row-level comparisons.
It helps to consider each separately. Aggregate metrics give a general sense of improvement, whereas row-level before/after comparisons reveal specific issues and guide meaningful adjustments. Different criteria may matter more at different stages.
Common eval criteria include:
Quality (complex but essential!)
Accuracy
Interestingness (first introduced by DeepMind evaluating LaMDA in 2021)
Rudeness
Schema adherence or formatting
Beyond these general criteria, our customers frequently create highly specific metrics tailored to their unique cases—for example, ""Does the chatbot accurately categorize customer inquiries into correct support topics?" or "Does the summarized contract accurately highlight all critical legal clauses?" Custom evals often prove critical in fine-tuning products.
For generative AI products, various questions arise when evaluating whether the LLM behaves as desired, or if prompt, model, and code changes truly enhance user experience.
A robust eval suite should reliably help your team:
Monitor and identify production issues.
Assess experiments and quantify improvements or regressions before deployment.
Rapidly design experiments and explore new evaluation questions.
Typically, teams use multiple criteria simultaneously, creating comprehensive eval suites. Certain criteria may gain priority when experimenting to enhance specific aspects, making a flexible eval suite essential.
Type of Evaluations
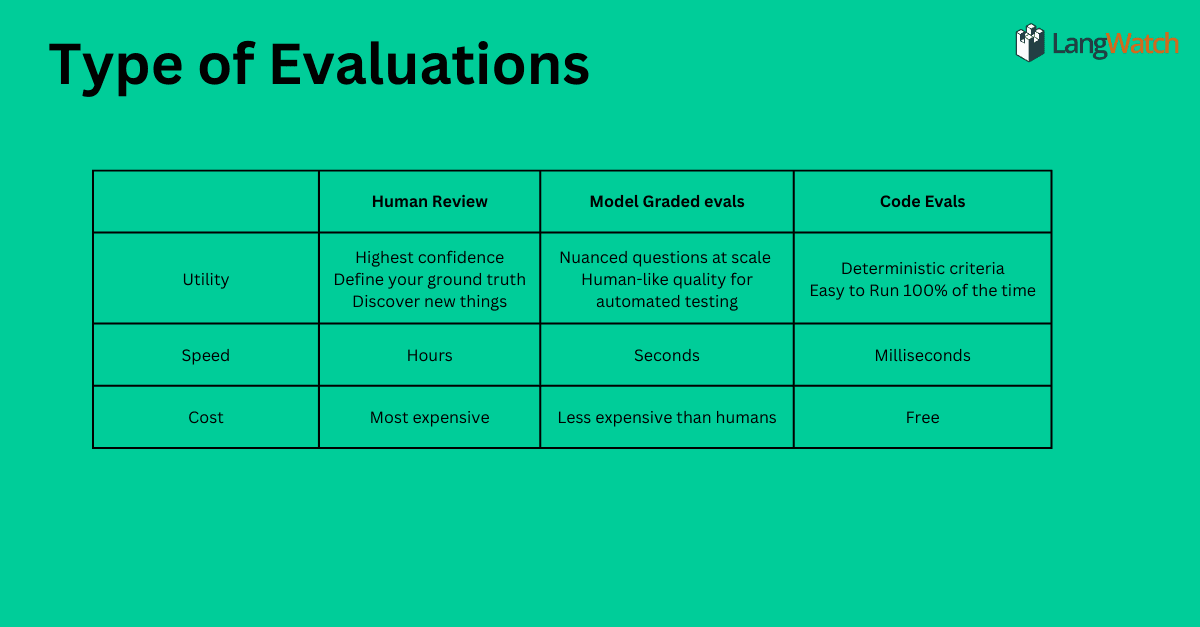
Different Types of Evals & When to Use Them
So, how should you execute evals? There are three primary methods, each with distinct benefits:
Human in the Loop ("Annotations")
Despite automation's rise, human review remains vital. If you're developing AI products, analyzing substantial data is essential.
Human review is maybe costly, yet so crucial for:
Confidence: Domain experts (think Category managers or Legal professions for a Legal AI) reviews provide certainty about system behavior.
Ground truth labeling: Fundamental for refining model-graded evals, ensuring alignment with human expectations.
Discovery: Human analysis naturally surfaces unexpected insights and issues—your path to finding "unknown unknowns."
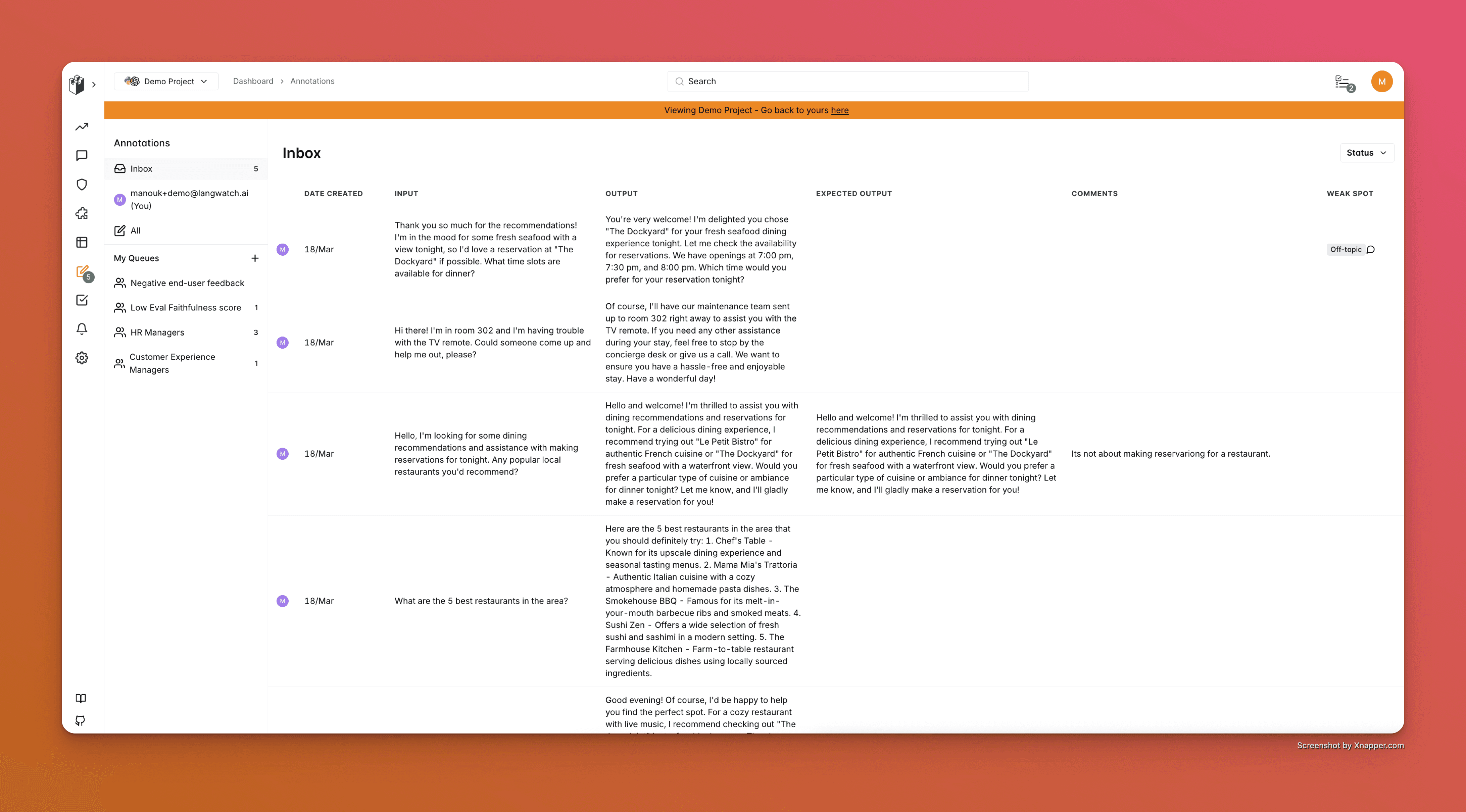
An user-friendly for non-technical people, annotation inbox (to provide feedback on output)
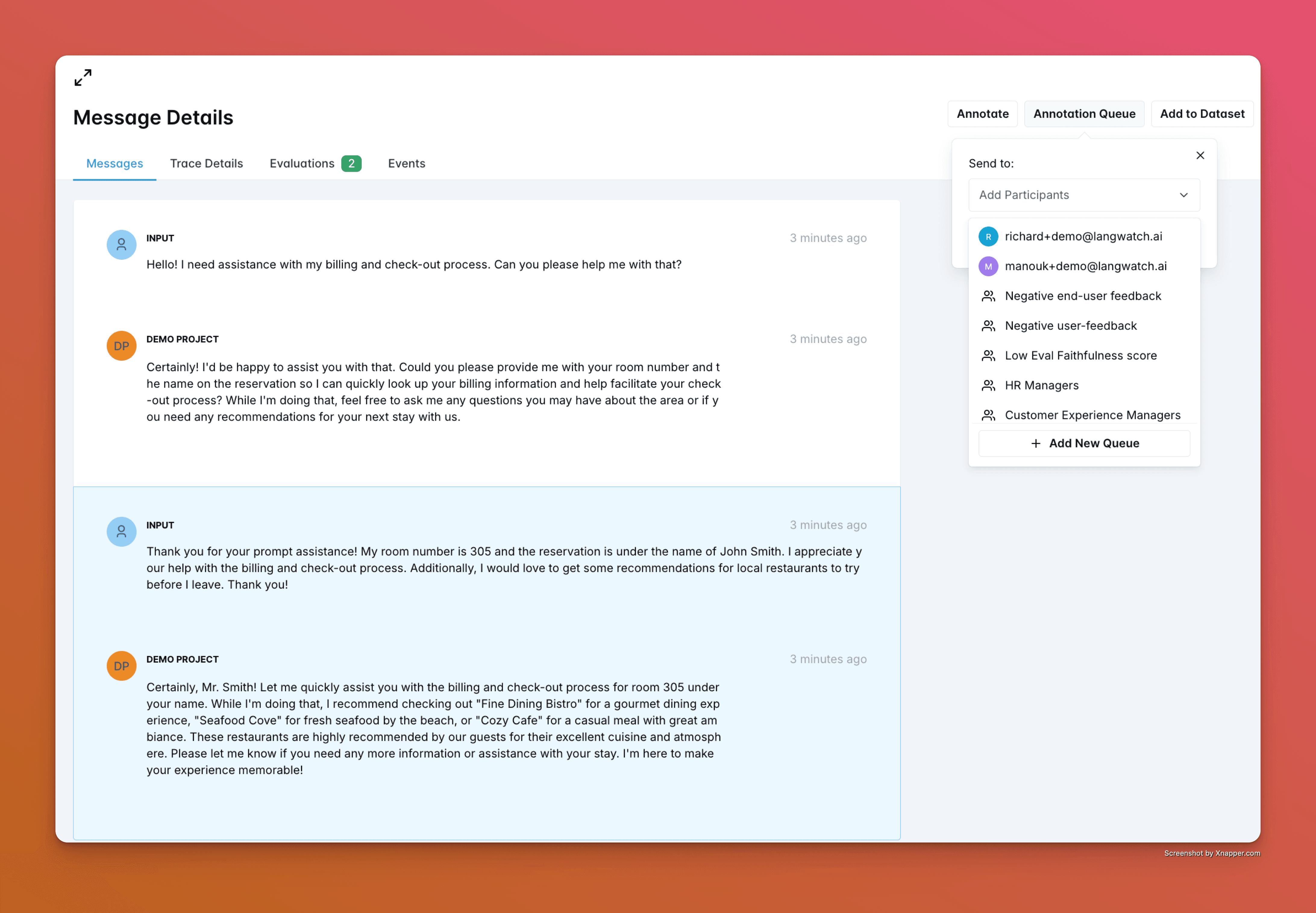
Labelling LLM-output and adding them to an "Annotation queue"
Model-Graded Evals ("LLM-as-a-Judge")
Using AI to evaluate AI is appealing and incredibly beneficial for scaling analysis and accelerating experimentation.
Yet, these evals require refinement to match human expectations, adding incremental costs and latency.
Best used for:
Nuanced, large-scale analyses far cheaper and faster than human evaluation.
Human-like automated testing across extensive datasets
Out-of-the-box Evals such as RAGAS, faithfulness or Answer relevancy or if you have a ground-truth dataset: Factual Match have shown to be successfull in giving a automated way of controlling the quality and measuring the performance.
Code-Driven Evals ("Assertions")
Simple yet powerful, code-driven evals serve as "unit tests" for AI products.
These evals might include grammar checks, regex patterns, formatting compliance, and numerical assessments like string or embedding distance calculations. They’re cost-effective and efficient.
Ideal for:
Deterministic checks: formatting, matching strings, etc.
Constant deployment: Integrate assertions into every LLM call, swiftly managing errors.

LangWatch’s Approach: Build & Run an Eval Suite as a Team
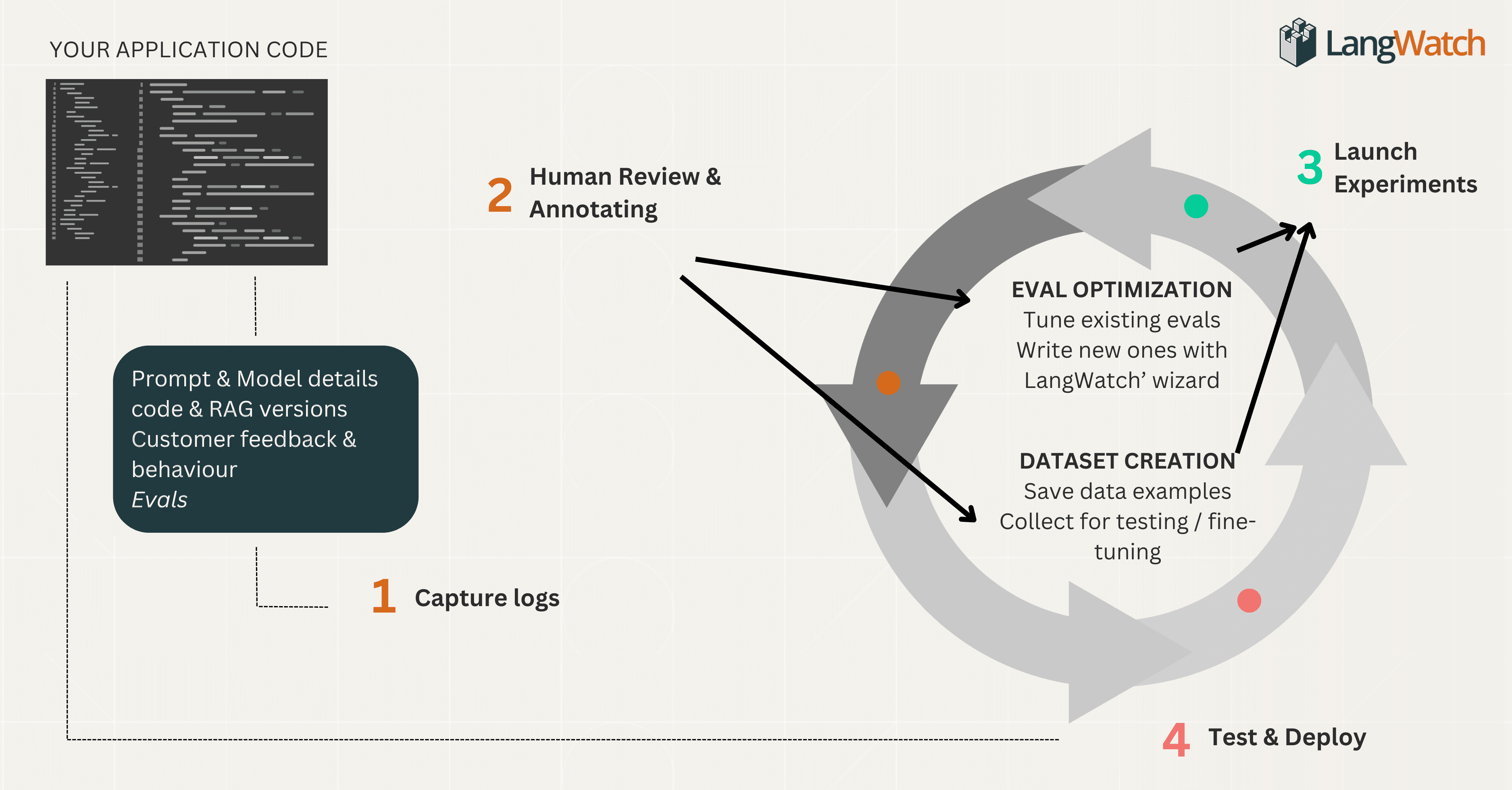
Though valuable, creating eval suites quickly generates new questions:
How many evals should we implement?
Which evals are most suitable?
When do we rely on code, AI models, or human intervention?
How can we trust these evals?
What constitutes the "best" eval?
Fortunately, developing an effective eval suite is inherently iterative, evolving through regular data analysis and practical insights.
There's no pressure to perfect evals immediately. Instead, focus on creating agile processes and tools allowing swift adjustments. A consistent, thoughtful process yields reliable outcomes.
We've seen successful implementation across diverse teams—from large to small, novice to expert—and based on these experiences, LangWatch offers an efficient framework to start quickly and iterate confidently.
Capture All Your Logs
Logs, traces extend beyond events, ensure detailed visibility into extensive textual data.
Version prompts, models, and configurations precisely (LangWatch simplifies this).
Log customer feedback and behavioral indicators, like corrections or regeneration attempts.
Capture relevant automated evals directly via LangWatch or from your code.
Surface Logs for Human Review
Schedule dedicated review sessions each week with real-world data.
Identify outliers through eval metrics.
Consistently review positive and negative customer feedback.
Random sampling prevents oversight due to biases or skewed data.
When reviewing:
Tag observations, add notes.
Correct inaccurate model-graded evals.
Save compelling examples for future analysis.
Refine or Develop New Evals
Regularly realign model-graded evals with human expectations through periodic human labeling. Add or retire evals based on fresh insights.
Create new evals addressing discovered issues.
Easily integrate additional code-based evals.
LangWatch streamlines evaluation alignment and new eval creation easily with Workflows.
Experiment with Fixes
Prevent overwhelming complexity by focusing each experiment narrowly:
Choose specific objectives and corresponding eval criteria.
Evaluate against relevant datasets.
Analyze and measure results clearly.
Ship Updates & Monitor Production
Continued monitoring in production helps detect deviations and customer surprises early.
We have build LangWatch with a high focus on quality control, having the right evals in place. We have build a Wizzrd for this to get the right eval in place. And we also support in the building the Eval Frame work.
Ready to start for free today or jump on a demo to learn more?
Evals are the thing of 2025 and building high-quality Evals is one of the most impact investments you can make.
Why are Evals important?
As long as our team has been focussing on having our users Shipping Qualitative LLM-apps, it finally kicks in! AI teams all over the world are seeing the shift and the need of evals is here!
Companies are evolving rapidly from prototypes and experiments to mature products in production. Teams realize that you can't effectively build and refine generative AI products without robust evals.
As more organizations prioritize evals, we've noticed that many teams struggle with where to begin, finding some concepts confusing.
The initial thought seems clear—“We need relevant evals to measure our product’s performance”—but the specifics on "how" can feel unclear. There's also plenty of market noise debating the "best evals," and it's tempting to adopt simple, off-the-shelf metrics that might not truly be helpful.
At LangWatch, we've found that the best approach is practical and straightforward: Identify what needs improvement, determine how to measure it, and create targeted evals for your highest priority metrics. This establishes a repeatable process your team can use to monitor production, analyze data, and iterate on your core AI system (prompts, RAG, etc.) and your evals as insights grow.
In this post, we'll demonstrate how LangWatch enables you to integrate various types of evals, provide guidance on when and how to use them, and outline a lightweight process to iteratively enhance your eval suite.
Ultimately, the goal is continuous improvement—better insights into product performance, and faster iterations that enhance your AI products for customers.
What are "Evals"?
First, let's clarify what "evals" actually mean, as that can sometimes be confusing!
Evals are individual evaluation criteria you apply to data samples. Each criterion typically involves calculating an aggregate score across a dataset and conducting individual, case-level analyses. People often interchangeably reference eval criteria, aggregate metrics, and row-level comparisons.
It helps to consider each separately. Aggregate metrics give a general sense of improvement, whereas row-level before/after comparisons reveal specific issues and guide meaningful adjustments. Different criteria may matter more at different stages.
Common eval criteria include:
Quality (complex but essential!)
Accuracy
Interestingness (first introduced by DeepMind evaluating LaMDA in 2021)
Rudeness
Schema adherence or formatting
Beyond these general criteria, our customers frequently create highly specific metrics tailored to their unique cases—for example, ""Does the chatbot accurately categorize customer inquiries into correct support topics?" or "Does the summarized contract accurately highlight all critical legal clauses?" Custom evals often prove critical in fine-tuning products.
For generative AI products, various questions arise when evaluating whether the LLM behaves as desired, or if prompt, model, and code changes truly enhance user experience.
A robust eval suite should reliably help your team:
Monitor and identify production issues.
Assess experiments and quantify improvements or regressions before deployment.
Rapidly design experiments and explore new evaluation questions.
Typically, teams use multiple criteria simultaneously, creating comprehensive eval suites. Certain criteria may gain priority when experimenting to enhance specific aspects, making a flexible eval suite essential.
Type of Evaluations
Different Types of Evals & When to Use Them
So, how should you execute evals? There are three primary methods, each with distinct benefits:
Human in the Loop ("Annotations")
Despite automation's rise, human review remains vital. If you're developing AI products, analyzing substantial data is essential.
Human review is maybe costly, yet so crucial for:
Confidence: Domain experts (think Category managers or Legal professions for a Legal AI) reviews provide certainty about system behavior.
Ground truth labeling: Fundamental for refining model-graded evals, ensuring alignment with human expectations.
Discovery: Human analysis naturally surfaces unexpected insights and issues—your path to finding "unknown unknowns."
An user-friendly for non-technical people, annotation inbox (to provide feedback on output)
Labelling LLM-output and adding them to an "Annotation queue"
Model-Graded Evals ("LLM-as-a-Judge")
Using AI to evaluate AI is appealing and incredibly beneficial for scaling analysis and accelerating experimentation.
Yet, these evals require refinement to match human expectations, adding incremental costs and latency.
Best used for:
Nuanced, large-scale analyses far cheaper and faster than human evaluation.
Human-like automated testing across extensive datasets
Out-of-the-box Evals such as RAGAS, faithfulness or Answer relevancy or if you have a ground-truth dataset: Factual Match have shown to be successfull in giving a automated way of controlling the quality and measuring the performance.
Code-Driven Evals ("Assertions")
Simple yet powerful, code-driven evals serve as "unit tests" for AI products.
These evals might include grammar checks, regex patterns, formatting compliance, and numerical assessments like string or embedding distance calculations. They’re cost-effective and efficient.
Ideal for:
Deterministic checks: formatting, matching strings, etc.
Constant deployment: Integrate assertions into every LLM call, swiftly managing errors.
LangWatch’s Approach: Build & Run an Eval Suite as a Team
Though valuable, creating eval suites quickly generates new questions:
How many evals should we implement?
Which evals are most suitable?
When do we rely on code, AI models, or human intervention?
How can we trust these evals?
What constitutes the "best" eval?
Fortunately, developing an effective eval suite is inherently iterative, evolving through regular data analysis and practical insights.
There's no pressure to perfect evals immediately. Instead, focus on creating agile processes and tools allowing swift adjustments. A consistent, thoughtful process yields reliable outcomes.
We've seen successful implementation across diverse teams—from large to small, novice to expert—and based on these experiences, LangWatch offers an efficient framework to start quickly and iterate confidently.
Capture All Your Logs
Logs, traces extend beyond events, ensure detailed visibility into extensive textual data.
Version prompts, models, and configurations precisely (LangWatch simplifies this).
Log customer feedback and behavioral indicators, like corrections or regeneration attempts.
Capture relevant automated evals directly via LangWatch or from your code.
Surface Logs for Human Review
Schedule dedicated review sessions each week with real-world data.
Identify outliers through eval metrics.
Consistently review positive and negative customer feedback.
Random sampling prevents oversight due to biases or skewed data.
When reviewing:
Tag observations, add notes.
Correct inaccurate model-graded evals.
Save compelling examples for future analysis.
Refine or Develop New Evals
Regularly realign model-graded evals with human expectations through periodic human labeling. Add or retire evals based on fresh insights.
Create new evals addressing discovered issues.
Easily integrate additional code-based evals.
LangWatch streamlines evaluation alignment and new eval creation easily with Workflows.
Experiment with Fixes
Prevent overwhelming complexity by focusing each experiment narrowly:
Choose specific objectives and corresponding eval criteria.
Evaluate against relevant datasets.
Analyze and measure results clearly.
Ship Updates & Monitor Production
Continued monitoring in production helps detect deviations and customer surprises early.
We have build LangWatch with a high focus on quality control, having the right evals in place. We have build a Wizzrd for this to get the right eval in place. And we also support in the building the Eval Frame work.
Ready to start for free today or jump on a demo to learn more?
Evals are the thing of 2025 and building high-quality Evals is one of the most impact investments you can make.
Why are Evals important?
As long as our team has been focussing on having our users Shipping Qualitative LLM-apps, it finally kicks in! AI teams all over the world are seeing the shift and the need of evals is here!
Companies are evolving rapidly from prototypes and experiments to mature products in production. Teams realize that you can't effectively build and refine generative AI products without robust evals.
As more organizations prioritize evals, we've noticed that many teams struggle with where to begin, finding some concepts confusing.
The initial thought seems clear—“We need relevant evals to measure our product’s performance”—but the specifics on "how" can feel unclear. There's also plenty of market noise debating the "best evals," and it's tempting to adopt simple, off-the-shelf metrics that might not truly be helpful.
At LangWatch, we've found that the best approach is practical and straightforward: Identify what needs improvement, determine how to measure it, and create targeted evals for your highest priority metrics. This establishes a repeatable process your team can use to monitor production, analyze data, and iterate on your core AI system (prompts, RAG, etc.) and your evals as insights grow.
In this post, we'll demonstrate how LangWatch enables you to integrate various types of evals, provide guidance on when and how to use them, and outline a lightweight process to iteratively enhance your eval suite.
Ultimately, the goal is continuous improvement—better insights into product performance, and faster iterations that enhance your AI products for customers.
What are "Evals"?
First, let's clarify what "evals" actually mean, as that can sometimes be confusing!
Evals are individual evaluation criteria you apply to data samples. Each criterion typically involves calculating an aggregate score across a dataset and conducting individual, case-level analyses. People often interchangeably reference eval criteria, aggregate metrics, and row-level comparisons.
It helps to consider each separately. Aggregate metrics give a general sense of improvement, whereas row-level before/after comparisons reveal specific issues and guide meaningful adjustments. Different criteria may matter more at different stages.
Common eval criteria include:
Quality (complex but essential!)
Accuracy
Interestingness (first introduced by DeepMind evaluating LaMDA in 2021)
Rudeness
Schema adherence or formatting
Beyond these general criteria, our customers frequently create highly specific metrics tailored to their unique cases—for example, ""Does the chatbot accurately categorize customer inquiries into correct support topics?" or "Does the summarized contract accurately highlight all critical legal clauses?" Custom evals often prove critical in fine-tuning products.
For generative AI products, various questions arise when evaluating whether the LLM behaves as desired, or if prompt, model, and code changes truly enhance user experience.
A robust eval suite should reliably help your team:
Monitor and identify production issues.
Assess experiments and quantify improvements or regressions before deployment.
Rapidly design experiments and explore new evaluation questions.
Typically, teams use multiple criteria simultaneously, creating comprehensive eval suites. Certain criteria may gain priority when experimenting to enhance specific aspects, making a flexible eval suite essential.
Type of Evaluations
Different Types of Evals & When to Use Them
So, how should you execute evals? There are three primary methods, each with distinct benefits:
Human in the Loop ("Annotations")
Despite automation's rise, human review remains vital. If you're developing AI products, analyzing substantial data is essential.
Human review is maybe costly, yet so crucial for:
Confidence: Domain experts (think Category managers or Legal professions for a Legal AI) reviews provide certainty about system behavior.
Ground truth labeling: Fundamental for refining model-graded evals, ensuring alignment with human expectations.
Discovery: Human analysis naturally surfaces unexpected insights and issues—your path to finding "unknown unknowns."
An user-friendly for non-technical people, annotation inbox (to provide feedback on output)
Labelling LLM-output and adding them to an "Annotation queue"
Model-Graded Evals ("LLM-as-a-Judge")
Using AI to evaluate AI is appealing and incredibly beneficial for scaling analysis and accelerating experimentation.
Yet, these evals require refinement to match human expectations, adding incremental costs and latency.
Best used for:
Nuanced, large-scale analyses far cheaper and faster than human evaluation.
Human-like automated testing across extensive datasets
Out-of-the-box Evals such as RAGAS, faithfulness or Answer relevancy or if you have a ground-truth dataset: Factual Match have shown to be successfull in giving a automated way of controlling the quality and measuring the performance.
Code-Driven Evals ("Assertions")
Simple yet powerful, code-driven evals serve as "unit tests" for AI products.
These evals might include grammar checks, regex patterns, formatting compliance, and numerical assessments like string or embedding distance calculations. They’re cost-effective and efficient.
Ideal for:
Deterministic checks: formatting, matching strings, etc.
Constant deployment: Integrate assertions into every LLM call, swiftly managing errors.
LangWatch’s Approach: Build & Run an Eval Suite as a Team
Though valuable, creating eval suites quickly generates new questions:
How many evals should we implement?
Which evals are most suitable?
When do we rely on code, AI models, or human intervention?
How can we trust these evals?
What constitutes the "best" eval?
Fortunately, developing an effective eval suite is inherently iterative, evolving through regular data analysis and practical insights.
There's no pressure to perfect evals immediately. Instead, focus on creating agile processes and tools allowing swift adjustments. A consistent, thoughtful process yields reliable outcomes.
We've seen successful implementation across diverse teams—from large to small, novice to expert—and based on these experiences, LangWatch offers an efficient framework to start quickly and iterate confidently.
Capture All Your Logs
Logs, traces extend beyond events, ensure detailed visibility into extensive textual data.
Version prompts, models, and configurations precisely (LangWatch simplifies this).
Log customer feedback and behavioral indicators, like corrections or regeneration attempts.
Capture relevant automated evals directly via LangWatch or from your code.
Surface Logs for Human Review
Schedule dedicated review sessions each week with real-world data.
Identify outliers through eval metrics.
Consistently review positive and negative customer feedback.
Random sampling prevents oversight due to biases or skewed data.
When reviewing:
Tag observations, add notes.
Correct inaccurate model-graded evals.
Save compelling examples for future analysis.
Refine or Develop New Evals
Regularly realign model-graded evals with human expectations through periodic human labeling. Add or retire evals based on fresh insights.
Create new evals addressing discovered issues.
Easily integrate additional code-based evals.
LangWatch streamlines evaluation alignment and new eval creation easily with Workflows.
Experiment with Fixes
Prevent overwhelming complexity by focusing each experiment narrowly:
Choose specific objectives and corresponding eval criteria.
Evaluate against relevant datasets.
Analyze and measure results clearly.
Ship Updates & Monitor Production
Continued monitoring in production helps detect deviations and customer surprises early.
We have build LangWatch with a high focus on quality control, having the right evals in place. We have build a Wizzrd for this to get the right eval in place. And we also support in the building the Eval Frame work.
Ready to start for free today or jump on a demo to learn more?
Boost your LLM's performance today
Get up and running with LangWatch in as little as 10 minutes.
Integrations
Recourses
Platform
About
Boost your LLM's performance today
Get up and running with LangWatch in as little as 10 minutes.
Integrations
Recourses
Platform
About
Boost your LLM's performance today
Get up and running with LangWatch in as little as 10 minutes.
Integrations
Recourses
Platform
About