Why LangWatch Scenarios represents the future of AI agent testing
Agent simulations are the new unit tests. You shouldn’t ship agents without simulations.
 Rogerio Chaves · June 24, 2025 · Agents
Rogerio Chaves · June 24, 2025 · Agents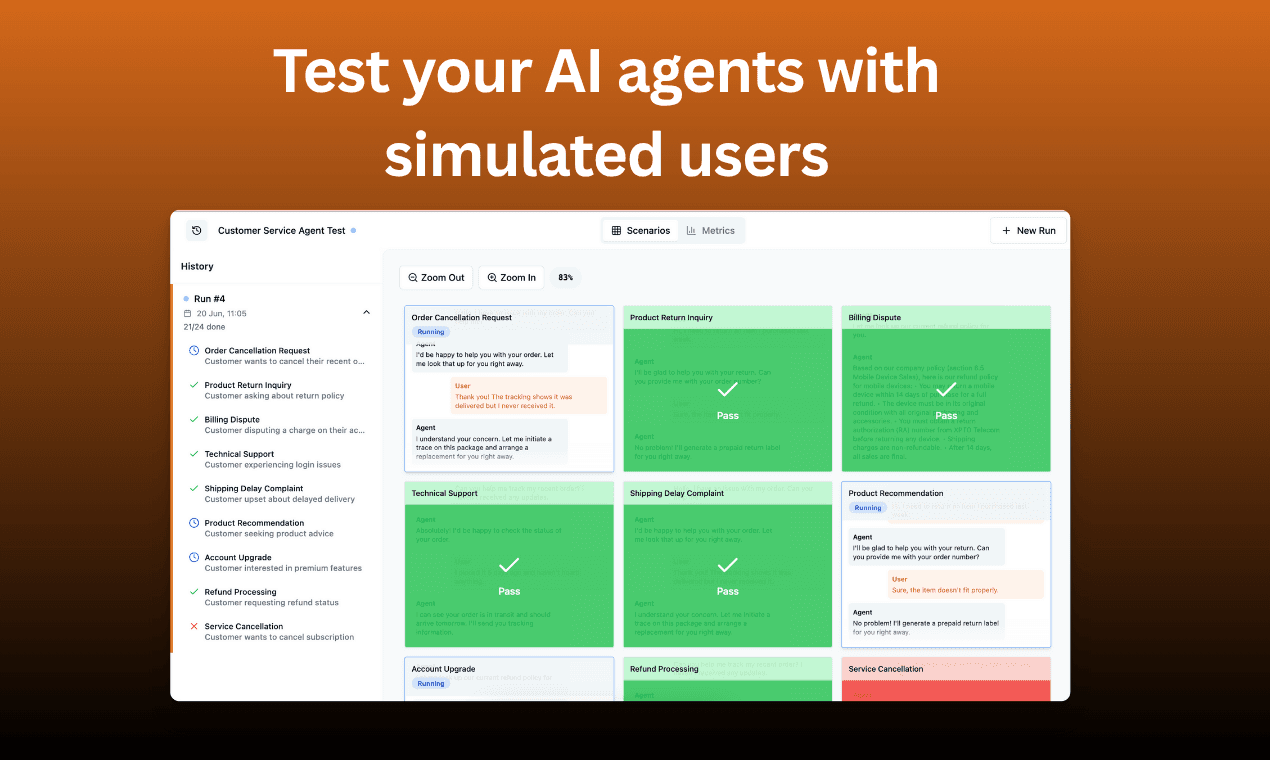
AI adoption is no longer optional. What started as simple LLM integrations has evolved into complex, multi-agent systems that can reason, use tools, and execute increasingly-sophisticated workflows.
Right now, teams are building autonomous agents that can handle customer support, conduct financial analysis, and even make business decisions. But here's what I've learned building testing infrastructure for these systems: there's a massive gap when it comes to AI agent testing.
Let me tell you why this matters.
AI and the paralysis problem
If you walk into just about any company building AI systems today, you’ll often find these organizations split between two camps:
The reckless teams moving fast and breaking things. These are the ones shipping agents with manual testing, crossing their fingers that nothing goes wrong in production, and hoping their "vibe checking" catches the worst issues.
The paralyzed teams are so concerned about quality that development has come to a halt. They're spending weeks manually testing every conversation flow, getting sign-offs from multiple stakeholders, and postponing releases indefinitely because they require perfection.
Unfortunately both approaches are losing long-term strategies.
Why current testing approaches fail
The root of both issues is how teams are approaching AI agent testing. Most are applying software testing methodologies to systems that fundamentally don't work like software.
When you test traditional software, you're checking that input A produces output B consistently:
-
Click this button, get that result
-
Call this API, receive that response
The system is deterministic, and testing is about verifying predictable behavior.
But agents aren't functions - they're processes. They navigate conversations, make decisions, use tools, and adapt their approach based on context. An agent might need to handle an angry customer, escalate to a human when appropriate, access multiple systems to gather information, and maintain context across dozens of conversation turns.
Manual testing doesn't scale with this complexity. You might be able to manually test a few conversation flows, but you can't manually test every possible combination of user intent, emotional state, edge case, and system condition.
"Vibe checking" might catch obvious problems, but it misses the subtle failures that compound over time. Traditional software testing assumes deterministic behavior, but agent behavior is inherently dynamic.
Basically, you need testing approaches that can handle this complexity, not fight against it.
Agent simulations have become the new unit tests
We believe that agent simulations are the new unit tests. In the same way that we’d never ship code without unit tests, we shouldn’t ship agents without simulations.
Unlike traditional tests that check for specific outputs, simulations test agent behavior across realistic scenarios. They use AI agents to test your AI agents, simulating the kind of dynamic, multi-turn interactions your system will face in production.
In fact, simulations have become the only way to test agents properly. We’ve found that every other option is either too rigid (fixed conversation paths that don't reflect real usage) or too generic (high-level metrics that don't catch specific failures).
Simulations are able to capture the full conversation flow, testing not just what your agent says, but how it navigates complex situations.
And here’s the final crucial insights: domain experts deserve deep involvement in this process. A software engineer building a medical AI assistant can't determine if clinical advice is accurate. A developer creating a legal research tool can't verify case law interpretations. The gap between technical capability and domain validation is real, and it's growing.
The solution isn't to hand finished outputs to domain experts for after-the-fact review - it's to involve them in the testing process itself.
When domain experts can create test scenarios, review agent reasoning, and provide feedback within the development workflow, quality improves dramatically. They go from a passive approver to an active participant, shaping how the system thinks within their domain.
A way forward: LangWatch Scenarios
We built LangWatch Scenarios to eliminate the false choice between speed and quality that's paralyzing the AI industry - as the first platform that lets you test AI agents like you test code.
The platform runs agent simulations automatically, testing agents across realistic scenarios with the same rigor you might apply to software testing.
Domain experts can collaborate seamlessly without breaking developer workflows, and everything is built to integrate with the development tools teams already use - pytest, CI/CD pipelines, version control.
The teams adopting systematic AI testing aren't just avoiding the recklessness vs. paralysis trap. They're gaining an advantage that compounds over time.
While their competitors are still manually testing or avoiding deployment altogether, these teams are iterating faster, shipping more reliably, and building more sophisticated AI systems.
The choice isn't between speed and quality anymore. It's between systematic development and falling behind. And that future starts now.
Put this into production with LangWatch.
Trace your agents, run evaluations, and turn failures into repeatable tests.