
Our platform lets teams test AI agents the right way: before launch, at scale, and under real-world conditions.
For you that means, higher confidence, lower risk, better outcomes.
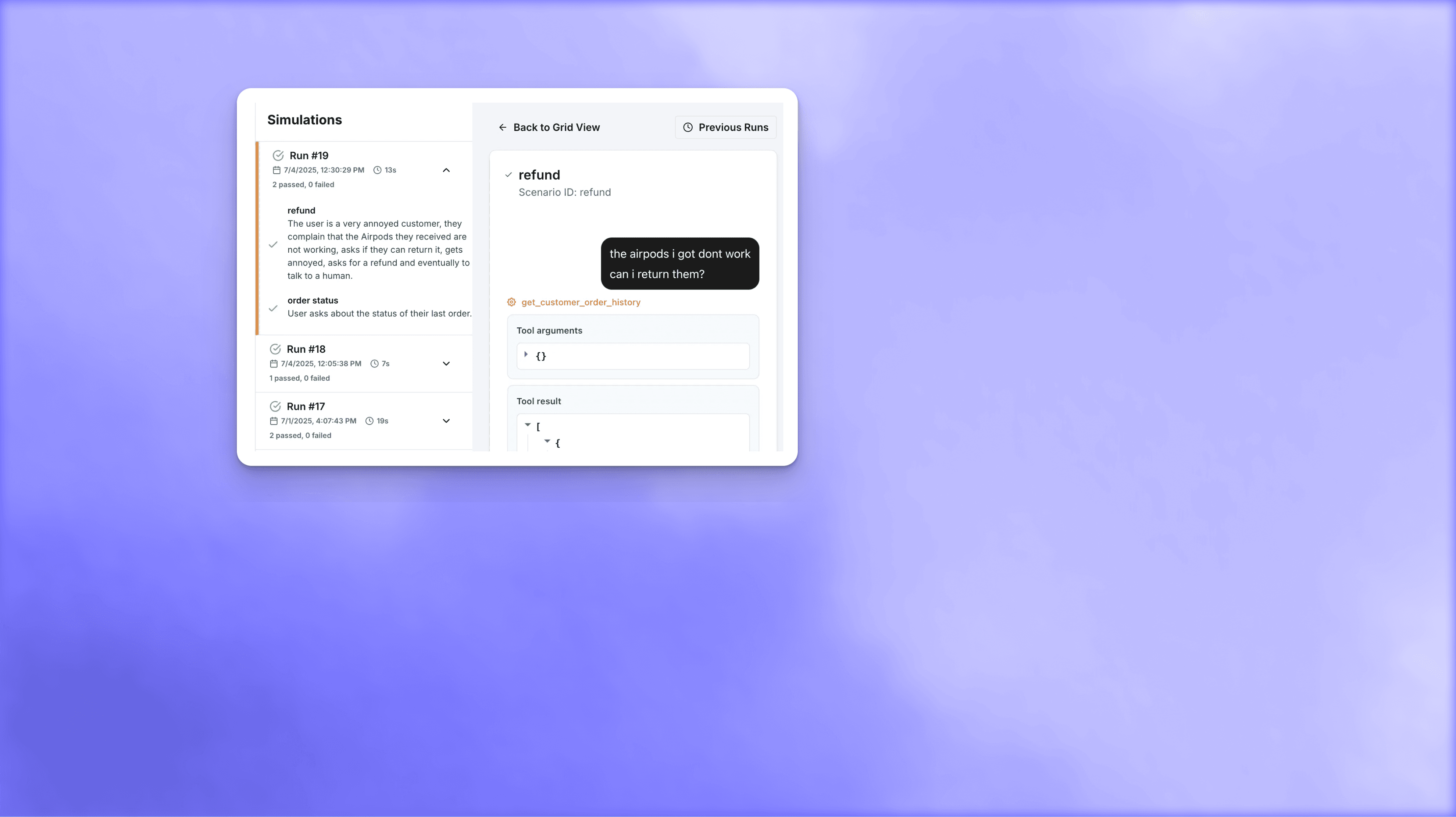
Use simulation agents to replicate real-world customer complexity
We chat with your agent to generate test cases.
Spot errors that manual QA would miss
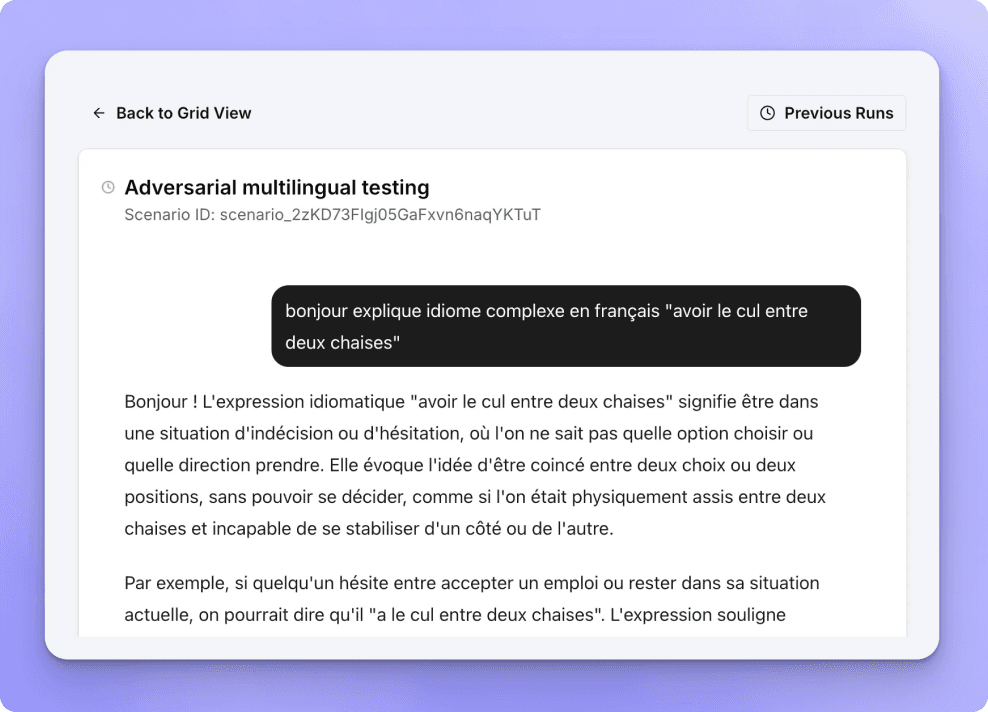
Use scripts, randomness, and adversarial probing to expose unexpected agent behavior.
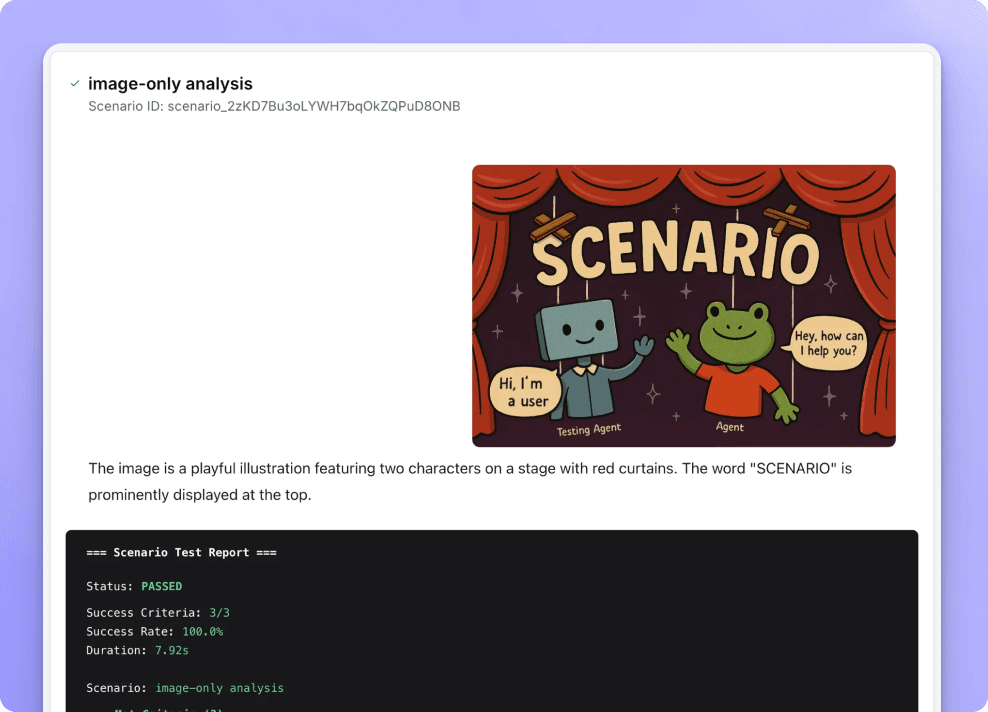
Run thousands of synthetic conversations across scenarios, languages, and edge cases
Automatically detect what changed, what failed, and why, on every agent update or prompt revision.
Manage your AI Agents
Simulation & evals for AI agents, from chat to voice.
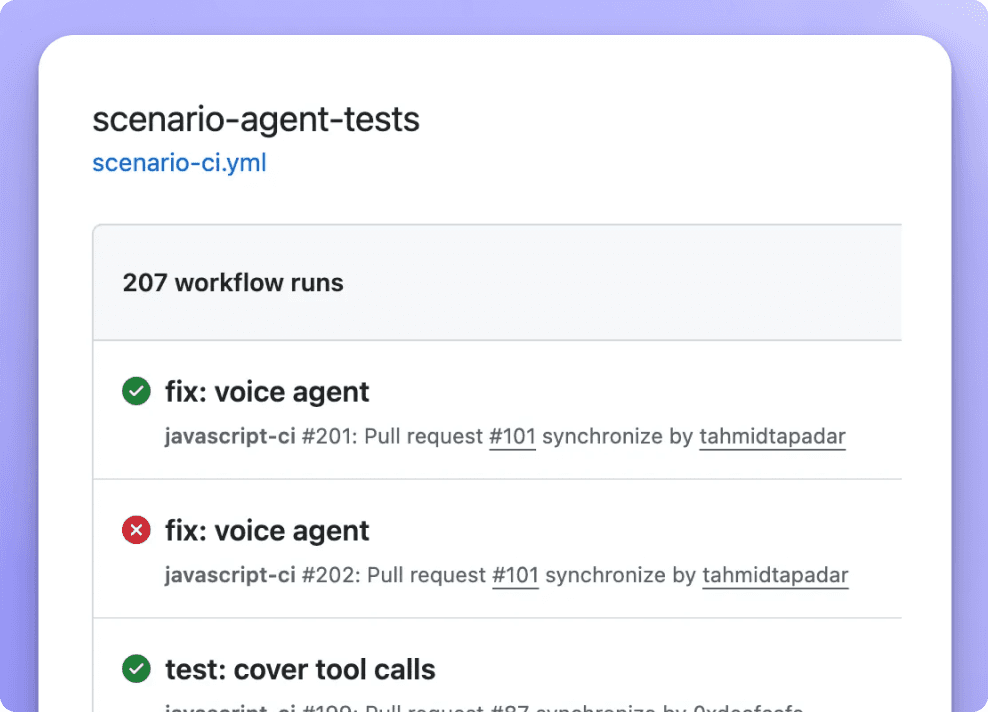
CI/CD
Execute agent simulations directly from your local machine or CI/CD pipeline
Framework agnostic
Combine LangWatch with any LLM eval framework or custom evals
Designed for collaboration
Collaborate with product managers and domain experts to build scenarios and evals
Scripted simulations
Define specific flows and expected outcomes to test critical agent behaviors
Simple integration
Integrate your Agent by implementing just one call() method
Visualized conversation
Identify failure points and understand interaction patterns during testing
Multi-turn control
Pause, evaluate, and annotate agent responses during simulated conversations
Multiple response format support
Handle agent responses in any format without additional parsing or conversion
Full debugging
Identify exactly where and why agent interactions failed during testing
Test your agents and prevent regressions








OpenTelemetry native, integrates with all LLMs & AI agent frameworks
Evaluations and Agent Simulations running on your existing testing infra
Fully open-source; run locally or self-host
No data lock-in, export any data you need and interop with the rest of your stack
LangWatch is more than just test scenario. It’s a complete evaluation platform:
LLM-as-judge or custom evals (tone, helpfulness, accuracy)
Visual diffing to catch subtle behavioral regressions
Fully open-source; run locally or self-host
Fits in CI workflows
Does not require a dataset to get started
From Agent Testing to Prompt Optimization
Automatically tune prompts, selectors, and agents based on evaluation feedback.


