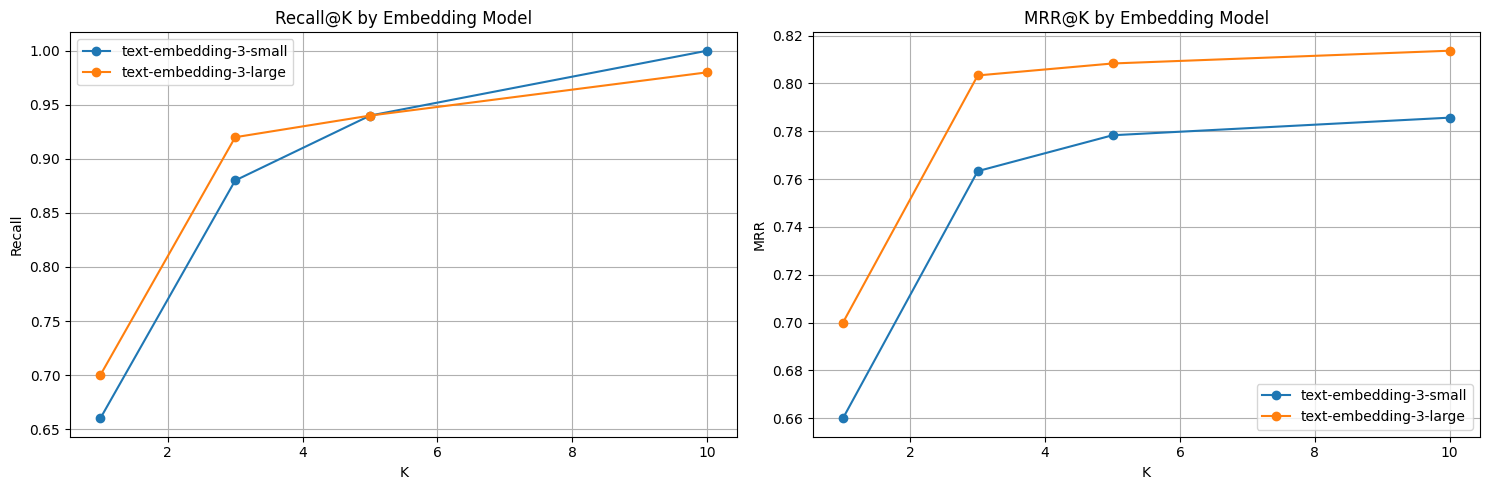
# Main evaluation function
def run_evaluation(k_values=[1, 3, 5, 10]):
"""Run evaluation across different k values and embedding models"""
results = []
# Sample a subset of queries for evaluation
eval_sample = eval_df.sample(min(50, len(eval_df)))
for k in k_values:
for model_name, collection in [("small", small_collection), ("large", large_collection)]:
model_results = []
# Use evaluation.loop() but process results synchronously
for index, row in evaluation.loop(eval_sample.iterrows()):
query = row['query']
expected_ids = [row['id']] # The document ID that should be retrieved
# Retrieve documents
retrieved_ids = retrieve(query, collection, k)
# Calculate metrics
recall = calculate_recall(retrieved_ids, expected_ids)
mrr = calculate_mrr(retrieved_ids, expected_ids)
# Log metrics to LangWatch
evaluation.log("recall", index=index, score=recall,
data={"model": model_name, "k": k, "query": query})
evaluation.log("mrr", index=index, score=mrr,
data={"model": model_name, "k": k, "query": query})
# Store results for this query
model_results.append({
"recall": recall,
"mrr": mrr
})
# Calculate average metrics
avg_recall = sum(r["recall"] for r in model_results) / len(model_results) if model_results else 0
avg_mrr = sum(r["mrr"] for r in model_results) / len(model_results) if model_results else 0
results.append({
"model": model_name,
"k": k,
"avg_recall": avg_recall,
"avg_mrr": avg_mrr
})
print(f"Model: {model_name}, k={k}, Recall={avg_recall:.4f}, MRR={avg_mrr:.4f}")
return pd.DataFrame(results)
# Run the evaluation
results_df = run_evaluation()