What is an Experiment?
An experiment consists of three components:- Dataset - A collection of test cases with inputs (and optionally expected outputs)
- Target - What you’re testing: a prompt, model, API endpoint, or custom code
- Evaluators - Scoring functions that assess output quality
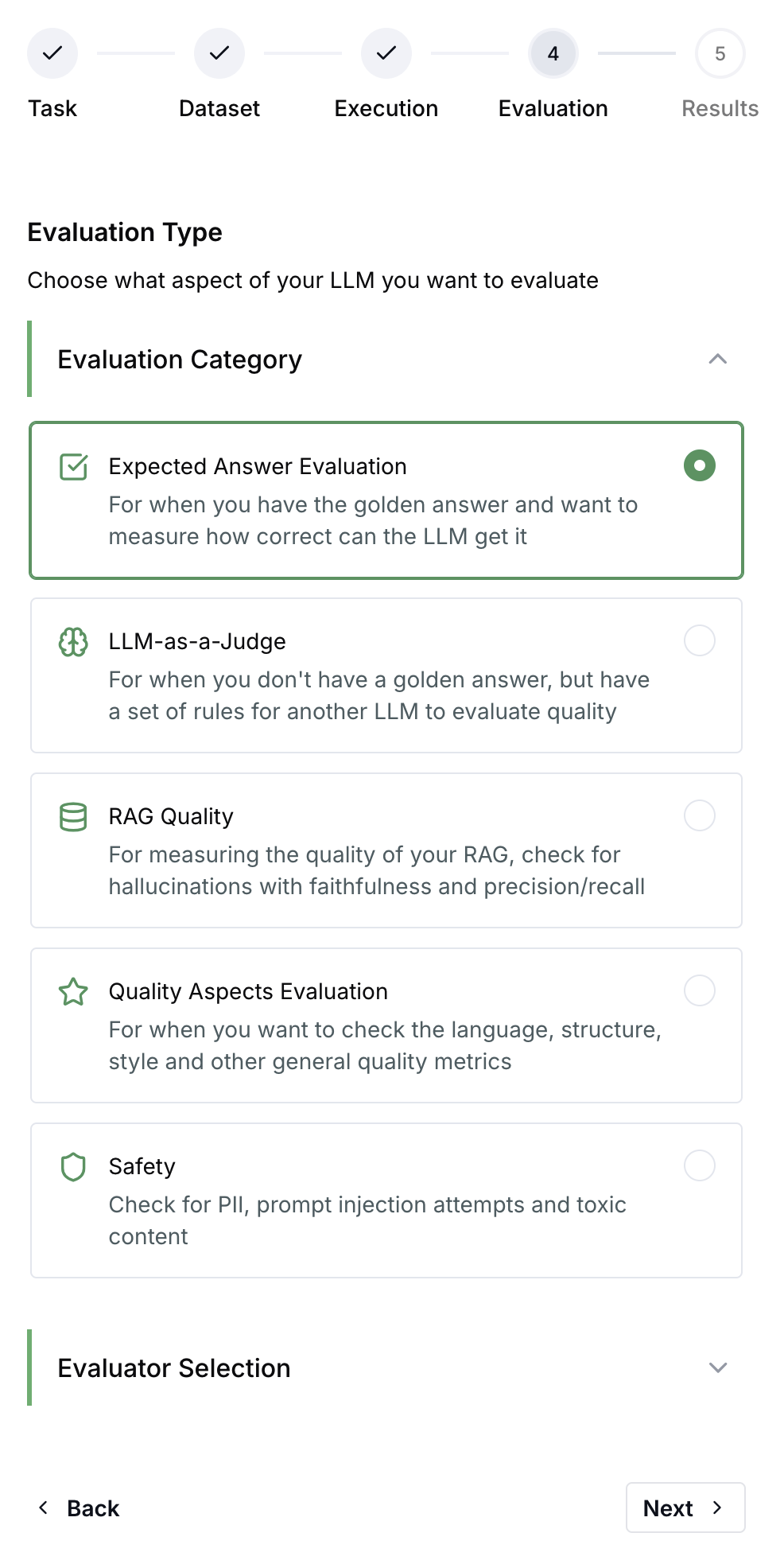
When to Use Experiments
- Before deploying - Validate prompt changes don’t regress quality
- Comparing options - Test different models, prompts, or configurations side-by-side
- CI/CD gates - Automatically block deployments that fail quality thresholds
- Benchmarking - Track quality metrics over time across experiment runs
Getting Started
Choose your preferred approach:Experiments via UI
Experiments via SDK
Quick Example
- Python
- TypeScript
Experiment Results
After running an experiment, you can:- Compare runs - See how different configurations perform side-by-side
- Drill into failures - Inspect individual test cases that scored poorly
- Track trends - Monitor quality metrics across experiment runs over time
- Export data - Download results for further analysis