Quickstart
1. Install the SDK
- Python
- TypeScript
2. Set your API Key
- Python (Notebook)
- Environment Variable
3. Start tracking
- Python
- TypeScript
Core Concepts
Evaluation Initialization
The evaluation is started by creating an evaluation session with a descriptive name:- Python
- TypeScript
Iterating over data
- Python
- TypeScript
Use
evaluation.loop() around your iterator so the entries are tracked:Metrics logging
Track any metric you want withevaluation.log():
- Python
- TypeScript
Comparing Multiple Targets
When comparing different models, prompts, or configurations, use targets to organize your results. Both SDKs provide atarget(), withTarget() context that automatically captures latency and enables context inference.
- Python
- TypeScript
Use Alternatively, use the
evaluation.target() for automatic latency capture and context inference:evaluation.target() automatically captures latency, creates isolated traces per target, and enables context inference so log() calls don’t need explicit target parameters. Use log_response() to store the model’s output.target parameter directly with evaluation.log():Target Registration
The first time you use a target name, it’s automatically registered with the provided metadata:- Python
- TypeScript
Metadata for Comparison
Target metadata is used for comparison charts in the LangWatch UI. You can group results by any metadata field:- Python
- TypeScript
Parallel Execution
LLM calls can be slow. Both SDKs support parallel execution to speed up your evaluations.- Python
- TypeScript
Use the built-in parallelization by putting the content of the loop in a function and submitting it:Sync callables passed to
By default,
threads=4. Adjust based on your API rate limits and system resources.Async-native mode
The defaultloop(), submit() path above already parallelises, each submitted task runs in a worker thread, so sync and async tasks both speed up with no extra work on your side. That’s the right choice for most users.Reach for aloop(), asubmit() only when your code is fully async-first and your task relies on async state whose identity is tied to one event loop. The threading path spins up a fresh event loop per worker, so those objects raise "Future attached to a different loop" on first use. aloop, asubmit keep every submitted task on the caller’s event loop, so that state stays valid across concurrent items.asubmit are automatically offloaded to a worker thread so they don’t block the event loop for concurrent async siblings.Built-in Evaluators
LangWatch provides a comprehensive suite of evaluation metrics out of the box.- Python
- TypeScript
Use
evaluation.run() to leverage pre-built evaluators:Browse our complete list of available evaluators including metrics for RAG quality, hallucination detection, safety, and more.
Pairwise Compare
langevals/pairwise_compare compares two candidate outputs for the same input and asks a judge model to pick the better one. This is useful when you want to compare two prompts, models, or agent configurations directly instead of scoring each one independently.
The example below was verified against the live SDK path using evaluation.evaluate("langevals/pairwise_compare", ...).
- Python
- TypeScript
swap_and_confirm performs two judge calls with A/B order reversed on the second pass. If the two calls disagree, the evaluator returns a tie. Set has_golden_answer to false when you want a pure head-to-head comparison without a reference answer.
The SDK result also records the pairwise judge’s own evaluator cost and duration. In exported results, those appear under the evaluator columns for langevals/pairwise_compare; they are separate from include_metrics, which injects each candidate target’s cost or duration into the judge prompt.
If you already have your own local pairwise judge, publish its result with evaluation.log(...) by sending a score, label, and details. Those custom results are tracked like any other SDK metric. The dedicated pairwise column visualization currently comes from the built-in Pairwise Compare evaluator configuration.
Complete Example
- Python
- TypeScript
Tracing Your Pipeline
To get complete visibility into your LLM pipeline, add tracing to your functions:- Python
- TypeScript
Learn more in our Python Integration Guide.
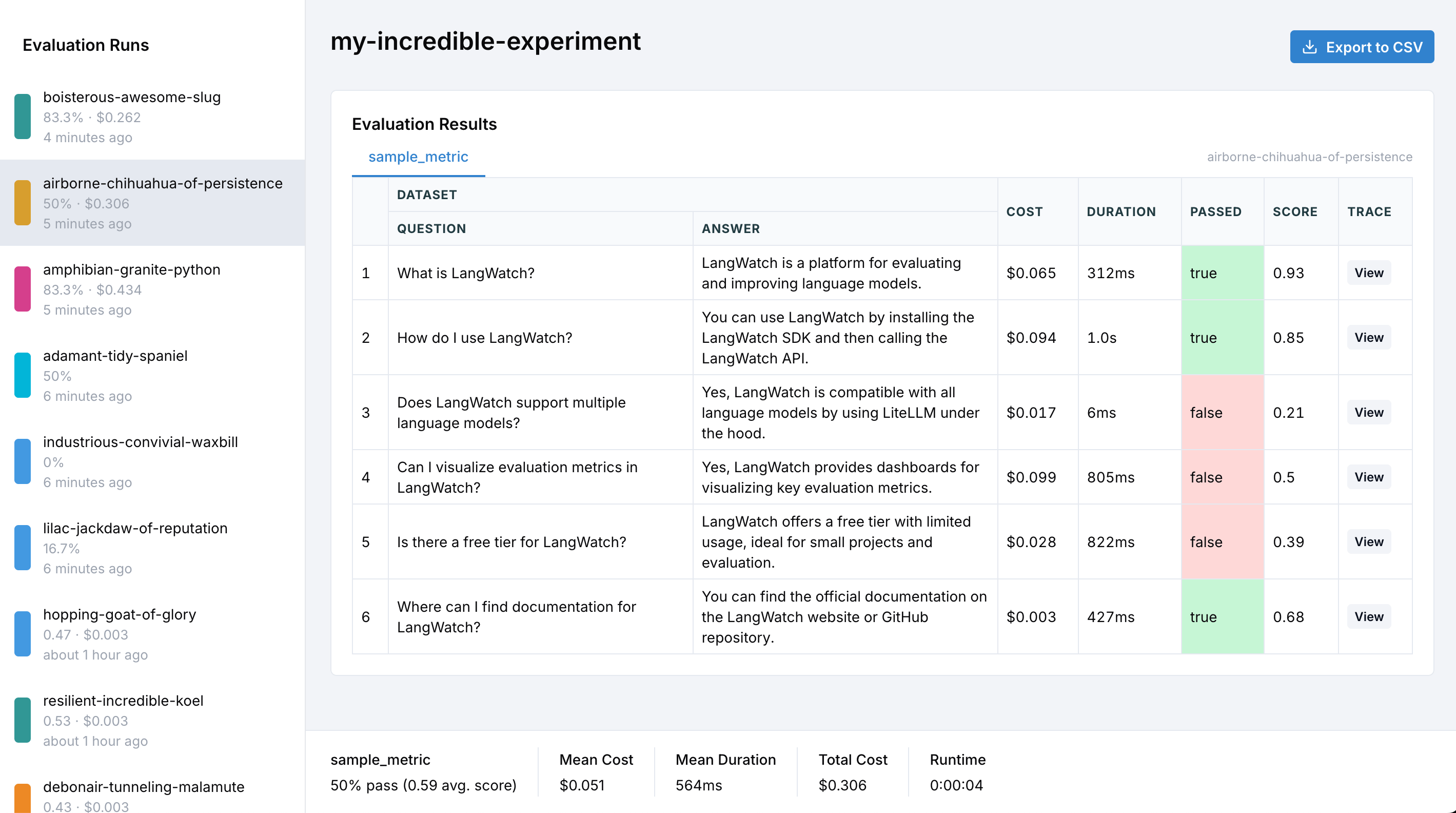
Exporting Results to CSV
After running your evaluations, you can export results to CSV for further analysis in spreadsheet tools like Excel or Google Sheets.How to Export
Click the Export to CSV button in the top-right corner of the evaluation results page to download a complete CSV file with all your data.CSV Structure
The exported CSV contains comprehensive data organized by dataset rows and targets. Here’s the complete column structure:Row Index
Dataset Columns
All columns from your input dataset are included with their original names.Target Columns (per target)
For each target in your evaluation, the following columns are exported:Evaluator Columns (per target, per evaluator)
For each evaluator applied to a target:
For
langevals/pairwise_compare, the evaluator cost and duration columns describe the pairwise judge run itself. When swap_and_confirm is enabled, that judge run may include two model calls.
Example CSV Output
For an evaluation comparing GPT-4 and Claude with a faithfulness evaluator:Using the Data
The CSV export enables powerful analysis workflows:Filter and compare models
Filter and compare models
Use spreadsheet filters to compare specific models or configurations:
- Filter by
{target}_modelto analyze specific model performance - Sort by
{target}_{evaluator}_scoreto find best/worst performing samples - Filter by
{target}_errorto identify failed executions
Analyze costs and latency
Analyze costs and latency
Calculate aggregate metrics across your evaluation:
- Sum
{target}_costcolumns for total evaluation cost per model - Average
{target}_duration_msto compare response times - Identify outliers with high latency or cost
Group by metadata
Group by metadata
Analyze performance across different configurations:
- Pivot tables by temperature, max_tokens, or custom metadata
- Compare prompt versions side-by-side
- Track improvements across iterations
Debug failures
Debug failures
Investigate problematic samples:
- Filter rows where
{target}_erroris not empty - Cross-reference
indexwith the UI for detailed inspection - Click through to traces using
{target}_trace_id
All column headers are normalized to lowercase with spaces replaced by underscores for consistency and compatibility with data analysis tools.
Running in CI/CD
You can run SDK experiments in your CI/CD pipeline. Theprint_summary() method outputs a structured summary and exits with code 1 if any evaluations fail:
What’s Next?
CI/CD Integration
Run experiments in your CI/CD pipeline
View Evaluators
Explore all available evaluation metrics
Datasets
Learn about dataset management
View Examples
Check out example notebooks